










-
经典计算机的运算能力依赖于芯片单位面积上晶体管的数量, 其发展符合摩尔定律. 未来随着晶体管的间距接近工艺制造的物理极限, 经典计算机的运算能力将面临发展瓶颈. 另一方面, 机器学习的发展对计算机的运算能力的需求却快速增长, 计算机的运算能力和需求之间的矛盾日益突出. 量子计算作为一种新的计算模式, 比起经典计算, 在一些特定算法上有着指数加速的能力, 有望给机器学习提供足够的计算能力. 用量子计算来处理机器学习任务时, 首要的一个基本问题就是如何将经典数据有效地在量子体系中表示出来. 这个问题称为态制备问题. 本文回顾态制备的相关工作, 介绍目前提出的多种态制备方案, 描述这些方案的实现过程, 总结并分析了这些方案的复杂度. 最后对态制备这个方向的研究工作做了一些展望.The development of traditional classic computers relies on the transistor structure of microchips, which develops in accordance with Moore's Law. In the future, as the distance between transistors approaches to the physical limit of manufacturing process, the development of computation capability of classical computers will encounter a bottleneck. On the other hand, with the development of machine learning, the demand for computation capability of computer is growing rapidly, and the contradiction between computation capability and demand for computers is becoming increasingly prominent. As a new computing model, quantum computing is significantly faster than classical computing for some specific problems, so, sufficient computation capability for machine learning is expected. When using quantum computing to deal with machine learning tasks, the first basic problem is how to represent the classical data effectively in the quantum system. This problem is called the state preparation problem. In this paper, the relevant researches of state preparation are reviewed, various state preparation schemes proposed at present are introduced, the processes of realizing these schemes are described, and the complexities of these schemes are summarized and analyzed. Finally, some prospects of the research work in the direction of state preparation are also presented.
-
Keywords:
- state preparation /
- quantum machine learning /
- encoding
[1] Jordan M I, Mitchell T M 2015 Science 349 255
 Google Scholar
Google Scholar
[2] Lay K T, Katsaggelos A K 1990 Opt. Eng. 29 436
Google Scholar
[3] Lu D, Weng Q 2007 Int. J. Remote Sens. 28 823
Google Scholar
[4] Samaria F S, Harter A C 2002 Proceedings of 1994 IEEE Workshop on Applications of Computer Vision Sarasota, December 5–7, 1994 p138
[5] Guillaumin M, Verbeek J, Schmid C 2009 In 2009 IEEE 12th international conference on computer vision Kyoto, Japan, September 29–October 2, 2009 p498
[6] [7] Silver D, Huang A, Maddison C J, Guez A, Sifre L, Driessche G V, Schrittwieser J, Antonoglou I, Panneershelvam V, Lanctot M, Dieleman S, Grewe D, Nham J, Kalchbrenner N, Sutskever I, Lillicrap T, Leach M, Kavukcuoglu K, Graepel T, Hassabis D 2016 Nature 529 484
Google Scholar
[8] Silver D, Schrittwieser J, Simonyan K, Antonoglou I, Huang A, Guez A, Hubert T, Baker L, Lai M, Bolton A, Chen Y, Lillicrap T, Hui F, Sifre L, Driessche G V, Graepel T, Hassabis D 2017 Nat. Nature 550 354
Google Scholar
[9] [10] Biamonte J, Wittek P, Pancotti N, Rebentrost P, Wiebe N, Lloyd S 2017 Nature 549 195
Google Scholar
[11] Soklakov A N, Schack R 2006 Phys. Rev. A 73 012307
Google Scholar
[12] Schuld M, Petruccione F 2018 Supervised Learning with Quantum Computers (Vol. 17) (Berlin: Springer) pp139–171
[13] Harrow A W, Hassidim A, Lloyd S 2009 Phys. Rev. Lett. 103 150502
Google Scholar
[14] Lloyd S, Mohseni M, Rebentrost P 2014 Nat. Phys. 10 631
Google Scholar
[15] Rebentrost P, Mohseni M, Lloyd S 2014 Phys. Rev. Lett. 113 130503
Google Scholar
[16] Grover L, Rudolph T 2002 arXiv: 0208112 v1 [quant-ph].
[17] Kaye P, Mosca M 2001International Conference on Quantum Information New York, USA, June 13, 2001 p28
[18] Nielsen M A, Chuang I 2002 Quantum Computation and Quantum Information (Cambridge: Cambridge University Press) pp120−215
[19] Kerenidis I, Prakash A 2016 arXiv: 1603.08675 v3 [quant-ph].
[20] Matteo O D, Gheorghiu V, Mosca M 2020 IEEE Trans. Quantum Eng. 1 4500213
Google Scholar
[21] Paler A, Oumarou O, Basmadjian R 2020 Phys. Rev. A 102 032608
Google Scholar
[22] Hann C T, Lee G, Girvin S M Jiang L 2021 PRX Quantum 2 020311
Google Scholar
[23] Mitarai K, Kitagawa M, Fujii K 2019 Phys. Rev. A 99 012301
Google Scholar
[24] Kitaev A, Webb W A 2008 arXiv: 0801.0342 [quant-ph].
[25] Holmes A, Matsuura A Y 2020 In 2020 IEEE International Conference on Quantum Computing and Engineering (QCE) Denver, CO, USA, October 12−16, 2020 p169
[26] Vazquez A C, Woerner S 2021 Phys. Rev. A 15 034027
[27] Zoufal C, Lucchi A, Woerner S 2019 npj Quantum Inf. 5 103
[28] Arrazola J M, Bromley T R, Izaac J, Myers C R, Brádler K, Killoran N 2019 Quantum Sci. Technol. 4 024004
Google Scholar
[29] Montanaro A 2015 Proc. R. Soc. A 471 20150301
Google Scholar
[30] Orus R, Mugel S, Lizaso E 2019 Rev. Phys. 4 100028
Google Scholar
[31] Stamatopoulos N, Egger D J, Sun Y, Zoufal C, Iten R, Shen N, Woerner S 2020 Quantum 4 291
Google Scholar
[32] Woerner S, Egger D J 2019 npj Quantum Inf. 5 15
[33] Lloyd S 1996 Science 273 1073
Google Scholar
[34] Matteo O D, McCoy A, Gysbers P, Miyagi T, Woloshyn R M, Navrátil P 2021 Phys. Rev. A 103 042405
Google Scholar
[35] Zhou P F, Hong R, Ran S J 2021 arXiv: 2104.14949[quant-ph].
-
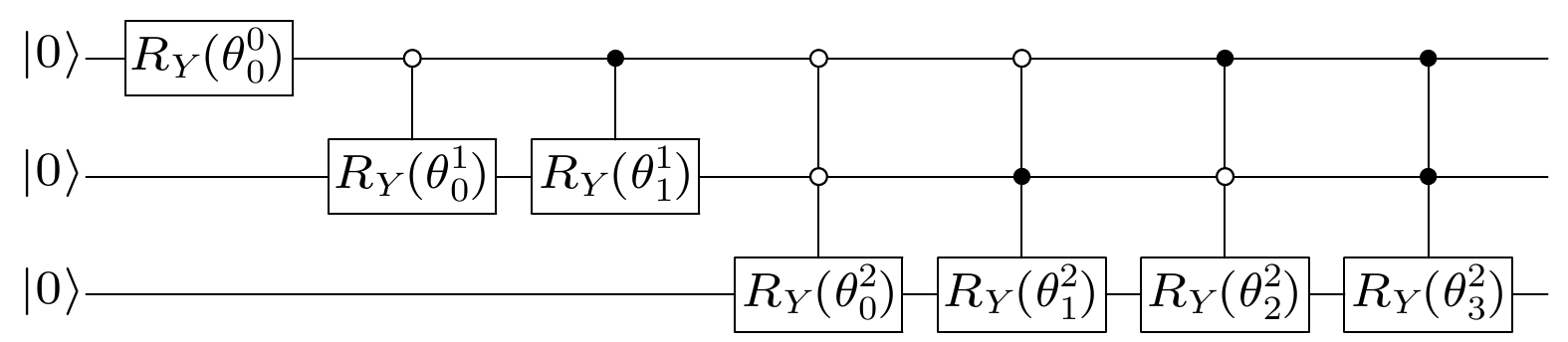
图 2
$ N = 8 $ 时用$ \mathcal O(N) $ 的时间制备$ f(X) $ Fig. 2. Preparation for
$ f(X) $ in$ \mathcal O(N) $ time for$ N = 8 $ .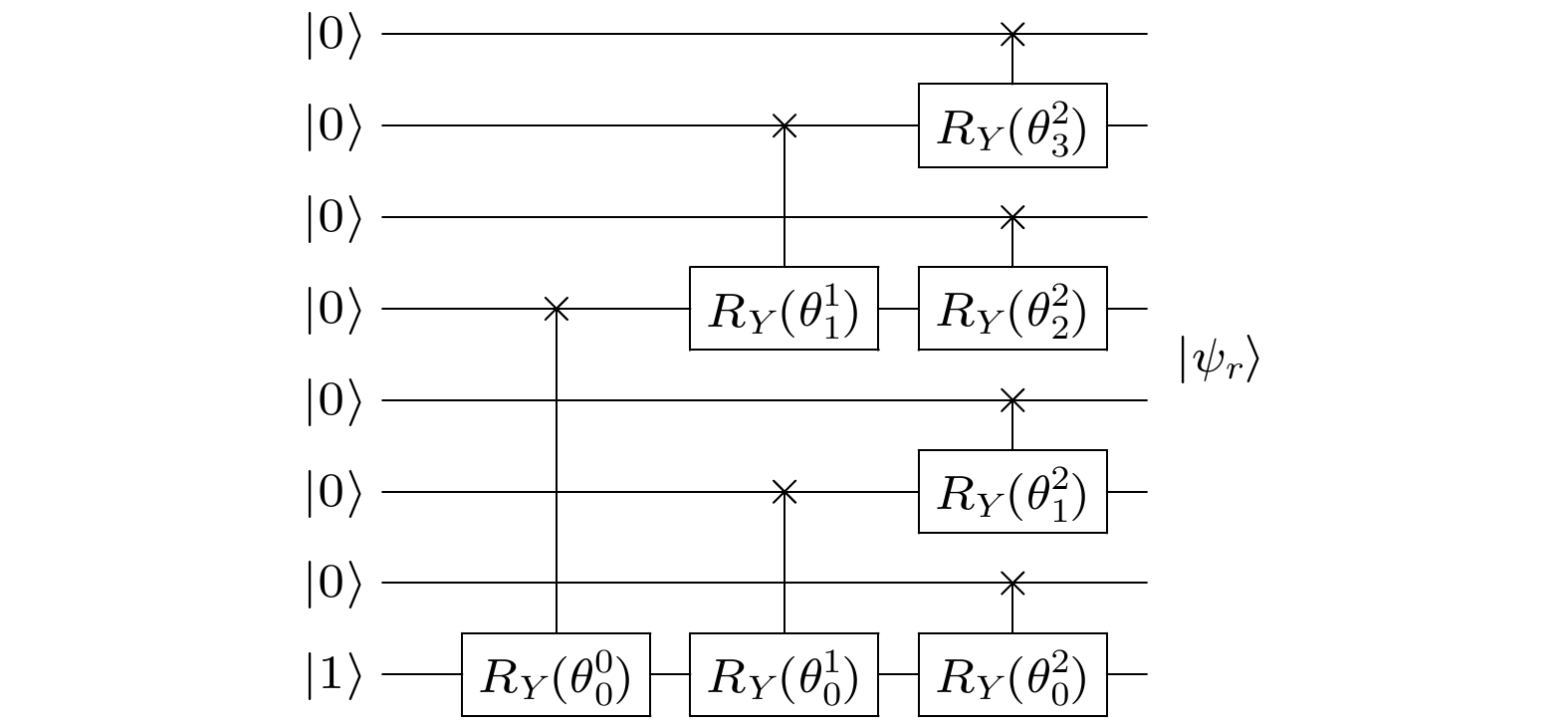
图 3
$ N = 8 $ 时用$ \mathcal O(\log N) $ 的时间获取振幅Fig. 3. Acquiring the amplitudes in
$ \mathcal O(\log N) $ time for$ N = 8 $ .表 1 态制备的不同编码方式的复杂度分析
Table 1. Complexity analysis of kinds of encoding methods for state preparations.
编码方式 数据类型 比特数 执行时间 基底编码 二值数据 $\mathcal O(N)$ $\mathcal O(N)$ 显式振幅编码 计算基$|i\rangle$上编码 连续变量 $\mathcal O(\log N)$ $\mathcal O(N)$ $|2^i\rangle$上编码 连续变量 $\mathcal O(N)$ $\mathcal O(\log N)$ 含黑箱振幅编码 Grover和Kaye 连续变量 $\mathcal O(\log N)$ — Soklakov和Schack 连续变量 $\mathcal O(\log N)$ $\mathcal O({\rm{Poly}}(\log N))^*$ QRAM 连续变量 $\mathcal O(N)$ $\mathcal O(\log N)$ 量子抽样编码 分布函数 $\mathcal O(\log N)$ $\mathcal O(\log N)$ 哈密顿量编码 连续变量 $\mathcal O(N)/\mathcal O(\log N)$ $\mathcal O({\rm{Poly}}(\log N))^*$ 注: *同时受保真度和成功率的影响.  下载: 导出CSV
下载: 导出CSV
-
[1] Jordan M I, Mitchell T M 2015 Science 349 255
Google Scholar
[2] Lay K T, Katsaggelos A K 1990 Opt. Eng. 29 436
Google Scholar
[3] Lu D, Weng Q 2007 Int. J. Remote Sens. 28 823
Google Scholar
[4] Samaria F S, Harter A C 2002 Proceedings of 1994 IEEE Workshop on Applications of Computer Vision Sarasota, December 5–7, 1994 p138
[5] Guillaumin M, Verbeek J, Schmid C 2009 In 2009 IEEE 12th international conference on computer vision Kyoto, Japan, September 29–October 2, 2009 p498
[6] [7] Silver D, Huang A, Maddison C J, Guez A, Sifre L, Driessche G V, Schrittwieser J, Antonoglou I, Panneershelvam V, Lanctot M, Dieleman S, Grewe D, Nham J, Kalchbrenner N, Sutskever I, Lillicrap T, Leach M, Kavukcuoglu K, Graepel T, Hassabis D 2016 Nature 529 484
Google Scholar
[8] Silver D, Schrittwieser J, Simonyan K, Antonoglou I, Huang A, Guez A, Hubert T, Baker L, Lai M, Bolton A, Chen Y, Lillicrap T, Hui F, Sifre L, Driessche G V, Graepel T, Hassabis D 2017 Nat. Nature 550 354
Google Scholar
[9] [10] Biamonte J, Wittek P, Pancotti N, Rebentrost P, Wiebe N, Lloyd S 2017 Nature 549 195
Google Scholar
[11] Soklakov A N, Schack R 2006 Phys. Rev. A 73 012307
Google Scholar
[12] Schuld M, Petruccione F 2018 Supervised Learning with Quantum Computers (Vol. 17) (Berlin: Springer) pp139–171
[13] Harrow A W, Hassidim A, Lloyd S 2009 Phys. Rev. Lett. 103 150502
Google Scholar
[14] Lloyd S, Mohseni M, Rebentrost P 2014 Nat. Phys. 10 631
Google Scholar
[15] Rebentrost P, Mohseni M, Lloyd S 2014 Phys. Rev. Lett. 113 130503
Google Scholar
[16] Grover L, Rudolph T 2002 arXiv: 0208112 v1 [quant-ph].
[17] Kaye P, Mosca M 2001International Conference on Quantum Information New York, USA, June 13, 2001 p28
[18] Nielsen M A, Chuang I 2002 Quantum Computation and Quantum Information (Cambridge: Cambridge University Press) pp120−215
[19] Kerenidis I, Prakash A 2016 arXiv: 1603.08675 v3 [quant-ph].
[20] Matteo O D, Gheorghiu V, Mosca M 2020 IEEE Trans. Quantum Eng. 1 4500213
Google Scholar
[21] Paler A, Oumarou O, Basmadjian R 2020 Phys. Rev. A 102 032608
Google Scholar
[22] Hann C T, Lee G, Girvin S M Jiang L 2021 PRX Quantum 2 020311
Google Scholar
[23] Mitarai K, Kitagawa M, Fujii K 2019 Phys. Rev. A 99 012301
Google Scholar
[24] Kitaev A, Webb W A 2008 arXiv: 0801.0342 [quant-ph].
[25] Holmes A, Matsuura A Y 2020 In 2020 IEEE International Conference on Quantum Computing and Engineering (QCE) Denver, CO, USA, October 12−16, 2020 p169
[26] Vazquez A C, Woerner S 2021 Phys. Rev. A 15 034027
[27] Zoufal C, Lucchi A, Woerner S 2019 npj Quantum Inf. 5 103
[28] Arrazola J M, Bromley T R, Izaac J, Myers C R, Brádler K, Killoran N 2019 Quantum Sci. Technol. 4 024004
Google Scholar
[29] Montanaro A 2015 Proc. R. Soc. A 471 20150301
Google Scholar
[30] Orus R, Mugel S, Lizaso E 2019 Rev. Phys. 4 100028
Google Scholar
[31] Stamatopoulos N, Egger D J, Sun Y, Zoufal C, Iten R, Shen N, Woerner S 2020 Quantum 4 291
Google Scholar
[32] Woerner S, Egger D J 2019 npj Quantum Inf. 5 15
[33] Lloyd S 1996 Science 273 1073
Google Scholar
[34] Matteo O D, McCoy A, Gysbers P, Miyagi T, Woloshyn R M, Navrátil P 2021 Phys. Rev. A 103 042405
Google Scholar
[35] Zhou P F, Hong R, Ran S J 2021 arXiv: 2104.14949[quant-ph].



 下载:
下载:










计量
- 文章访问数: 15801
- PDF下载量: 669
- 被引次数: 0
