










-
在后摩尔时代, 突破原有技术极限, 进行原子尺度的精准构筑, 是当前的重大科学问题. DNA作为具有原子级精准度的生物大分子, 能够进行程序性的分子识别, 构筑原子数量与位置均严格确定的自组装结构, 因此是进行原子制造的理想平台. 本文提出基于DNA自组装折纸结构的精准定位能力, 构筑铁原子阵列图案, 并应用于对信息的加密. 实验结果表明, 采用类似“信息预置”的方法, 铁原子成功实现在DNA折纸不同位置的高效定位, 此方法还极大降低了实验工作量, 非常有利于多种不同阵列图案的平行制备. 利用所构建的铁原子阵列, 本文发展了原子阵列DNA折纸加密技术, 将密文编码为二进制并用类似盲文斑点的形式在DNA折纸上以特定图案表示, 通过单分子成像手段对密文信息进行了读取, 而密钥长度可高达700位以上. 作为示例, 成功地对普通文本及唐诗《登鹳雀楼》进行了加密, 证明了此策略的通用性和实用性.The fabrication of precise arrays of atoms is a key challenge at present. As a kind of biomacromolecule with strict base-pairing and programmable self-assembly ability, DNA is an idea material for directing atom positioning on predefined addresses. Here in this work, we propose the construction of iron atom arrays based on DNA origami templates and illustrate the potential applications in cryptography. First, ferrocene molecule is used as the carrier for iron atom since the cyclopentadienyl groups protect iron from being affected by the external environment. To characterize the iron atom arrays, streptavidins are labelled according to the ferrocene-modified DNA strand through biotin-streptavidin interactions. Based on atomic force microscopy scanning, ferrocene-modified single-stranded DNA sequences prove to be successfully immobilized on predefined positions on DNA origami templates with high yield. Importantly, the address information of iron atoms on origami is pre-embedded on the long scaffold, enabling the workload and cost to be lowered dramatically. In addition, the iron atom arrays can be used as the platform for constructing secure Braille-like patterns with encoded information. The origami assembly and pattern characterizations are defined as encryption process and readout process, respectively. The ciphertext can be finally decoded with the secure key. This method enables the theoretical key size of more than 700 bits to be realized. Encryption and decryption of plain text and a Chinese Tang poem prove the versatility and feasibility of this strategy.
-
Keywords:
- DNA origami /
- atom array /
- self-assembly /
- cryptography
[1] Frank-Kamenetskii M, Mrikin S 1995 Annu. Rev. Biochem. 64 65
 Google Scholar
Google Scholar
[2] Wang J, Yue L, Wang S, Willner I 2018 ACS Nano 12 12324
Google Scholar
[3] Ge Z, Gu H, Li Q, Fan C H 2018 J. Am. Chem. Soc. 140 17808
Google Scholar
[4] Hu Q, Li H, Wang L, Gu H, Fan C H 2019 Chem. Rev. 119 6459
Google Scholar
[5] Rothemund P W 2006 Nature 440 297
Google Scholar
[6] Hong F, Zhang F, Liu Y, Yan H 2017 Chem. Rev. 117 12584
Google Scholar
[7] Qian L, Winfree E, Bruck J 2011 Nature 475 368
Google Scholar
[8] Chao J, Wang J, Wang F, Ouyang X, Kopperger E, Liu H J, Li Q, Shi J, Wang L, Hu J, Wang L, Huang W, Simmel F C, Fan C H 2019 Nat. Mater. 18 273
Google Scholar
[9] Zhang Z, Wang Y, Fan C H, Li C, Li Y, Qian L, Fu Y, Shi Y, Hu J, He L 2010 Adv. Mater. 22 2672
Google Scholar
[10] Wu N, Czajkowsky D M, Zhang J, Qu J, Ye M, Zeng D, Zhou X, Hu J, Shao Z, Li B, Fan C H 2013 J. Am. Chem. Soc. 135 12172
Google Scholar
[11] 贾思思, 晁洁, 樊春海, 柳华杰 2014 化学进展 26 695
Google Scholar
Jia S, Chao J, Fan C H, Liu H J 2014 Prog. Chem. 26 695
Google Scholar
[12] 张祎男, 王丽华, 柳华杰, 樊春海 2017 物理学报 66 147101
Google Scholar
Zhang Y N, Wang L H, Liu H J, Fan C H 2017 Acta Phys. Sin. 66 147101
Google Scholar
[13] Fang W, Jia S, Chao J, Wang L, Duan X, Liu H J, Li Q, Zuo X, Wang L, Liu N, Fan C H 2019 Sci. Adv. 5 eaau4506
Google Scholar
[14] Liu X, Zhang F, Jing X, Pan M, Liu P, Li W, Zhu B, Li J, Chen H, Wang L, Lin J, Liu Y, Zhao D, Yan H, Fan C H 2018 Nature 559 593
Google Scholar
[15] Yao G, Li J, Chao J, Pei H, Liu H J, Zhao Y, Shi J, Huang Q, Wang L, Huang W, Fan C H 2015 Angew. Chem. Int. Ed. Engl. 54 2966
Google Scholar
[16] Maune H T, Han S P, Barish R D, Bockrath M, Goddard W A, Rothemund P W, Winfree E 2010 Nat. Nanotechnol. 5 61
Google Scholar
[17] Ekert A K 1991 Phys. Rev. Lett. 67 661
Google Scholar
[18] Zhan P, Wen T, Wang Z G, He Y, Shi J, Wang T, Liu X, Lu G, Ding B 2018 Angew. Chem. Int. Ed. 57 2846
Google Scholar
[19] Douglas S, Bachelet I, Church J 2012 Science 335 831
Google Scholar
[20] Zhao Y, Shaw A, Zeng X, Benson E, Nyström A, Högberg B 2012 ACS Nano 6 8684
Google Scholar
[21] Zhang Q, Jiang Q, Li N, Dai L, Liu Q, Song L, Wang J, Li Y, Tian J, Ding B, Du Y 2014 ACS Nano 8 6633
Google Scholar
[22] Woods D, Doty D, Myhrvold C, Hui J, Zhou F, Yin P, Winfree E 2019 Nature 567 366
Google Scholar
[23] Ge Z, Liu J, Guo L, Yao G, Li Q, Wang L, Li J, Fan C H 2020 J. Am. Chem. Soc. 142 8800
Google Scholar
[24] Zhang Y N, Wang F, Chao J, Xie M, Liu H J, Pan M, Kopperger E, Liu X, Li Q, Shi J, Wang L, Hu J, Wang L, Simmel F C, Fan C H 2019 Nat. Commun. 10 5469
Google Scholar
-
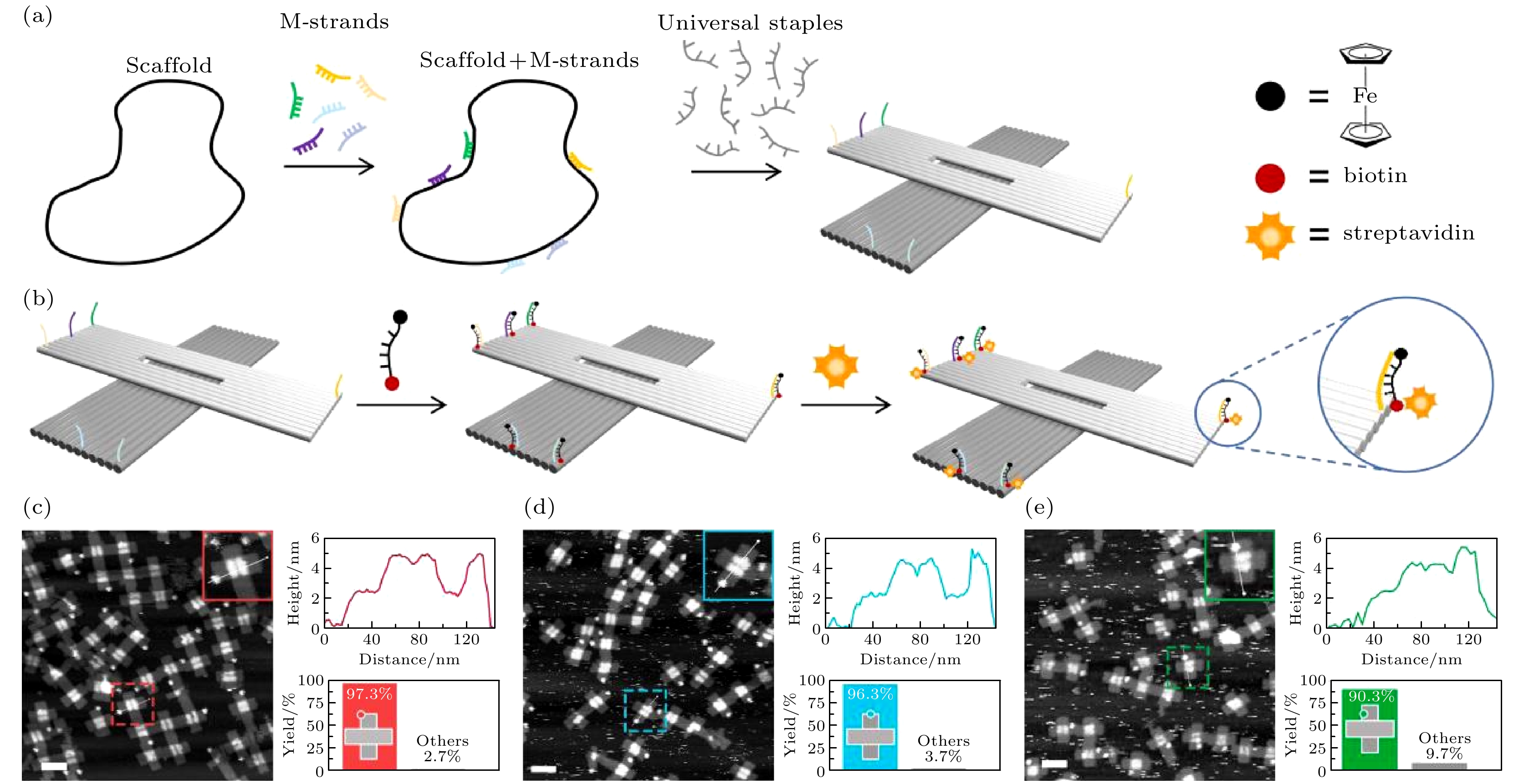
图 1 铁原子阵列的构建 (a), (b) 信息链预置于骨架链上的策略形成DNA折纸并组装铁原子阵列, 通过生物素和链霉亲和素的强结合力将位置显影; (c)—(e) 3个位点单个铁原子图案组装原子力表征图(比例尺: 100 nm)
Fig. 1. Fabrications of iron atoms arrays. (a), (b) The M-strand strategy forms DNA origami and assembles the iron atoms arrays. The position is visualized by the strong binding force of biotin and streptavidin. (c)–(e) The atomic force characterization diagram of the assembly of a single iron atom at three sites (scale bar: 100 nm).
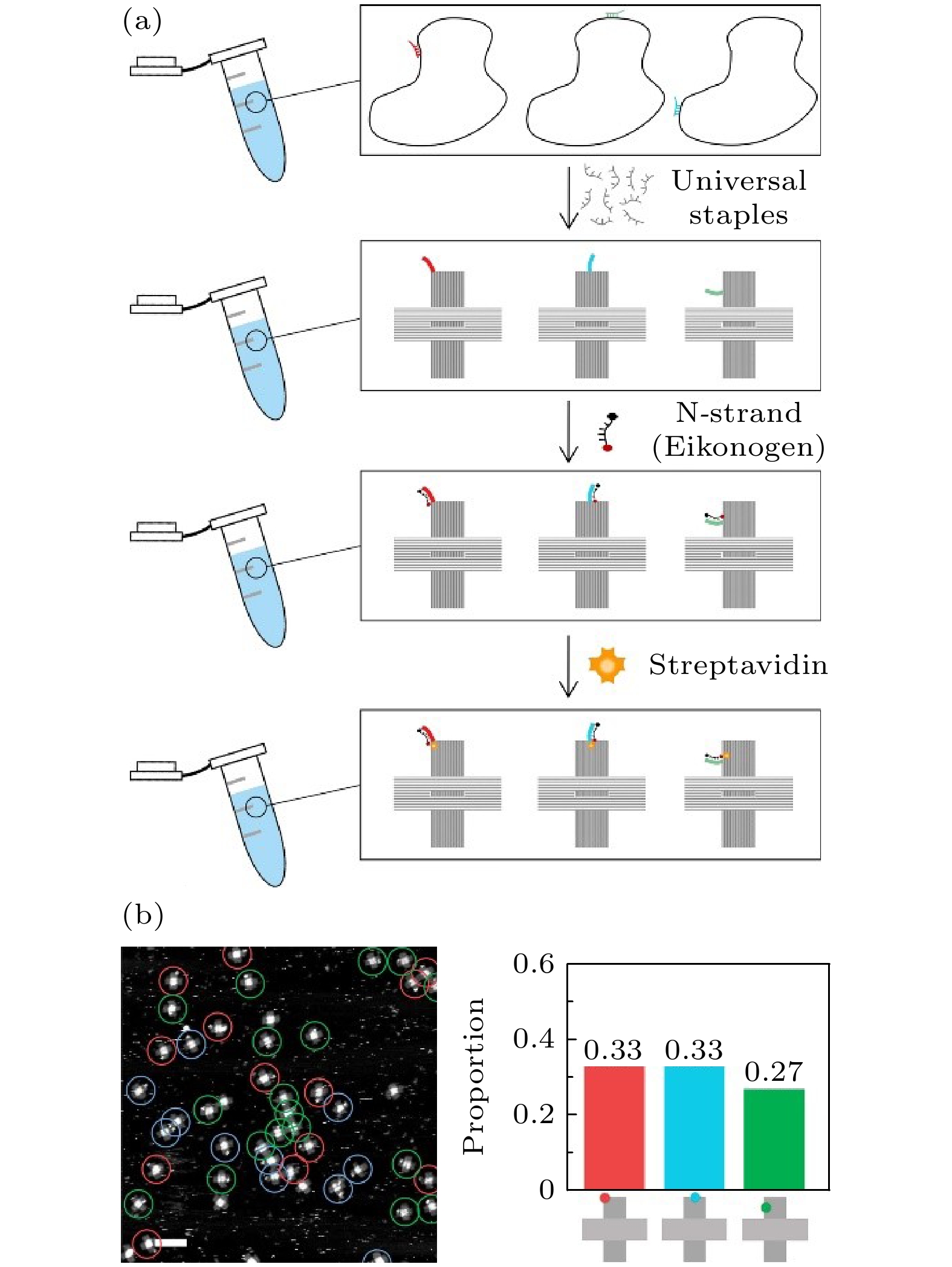
图 2 M链策略“一锅法”制备多种DNA折纸纳米图案 (a) 多种携带不同M链的骨架链混合, 一同退火, 在单个离心管中快速制备多种DNA折纸纳米图案; (b) 原子力表征图及产率统计图(比例尺: 200 nm)
Fig. 2. M-strand strategy to prepare a variety of DNA origami nanopatterns by “one-pot” method: (a) A variety of scaffolds carrying different M-strands are mixed and annealed together to quickly prepare a variety of DNA origami nanopatterns in a single centrifuge tube; (b) AFM diagram and yield statistics (scale bar: 200 nm).
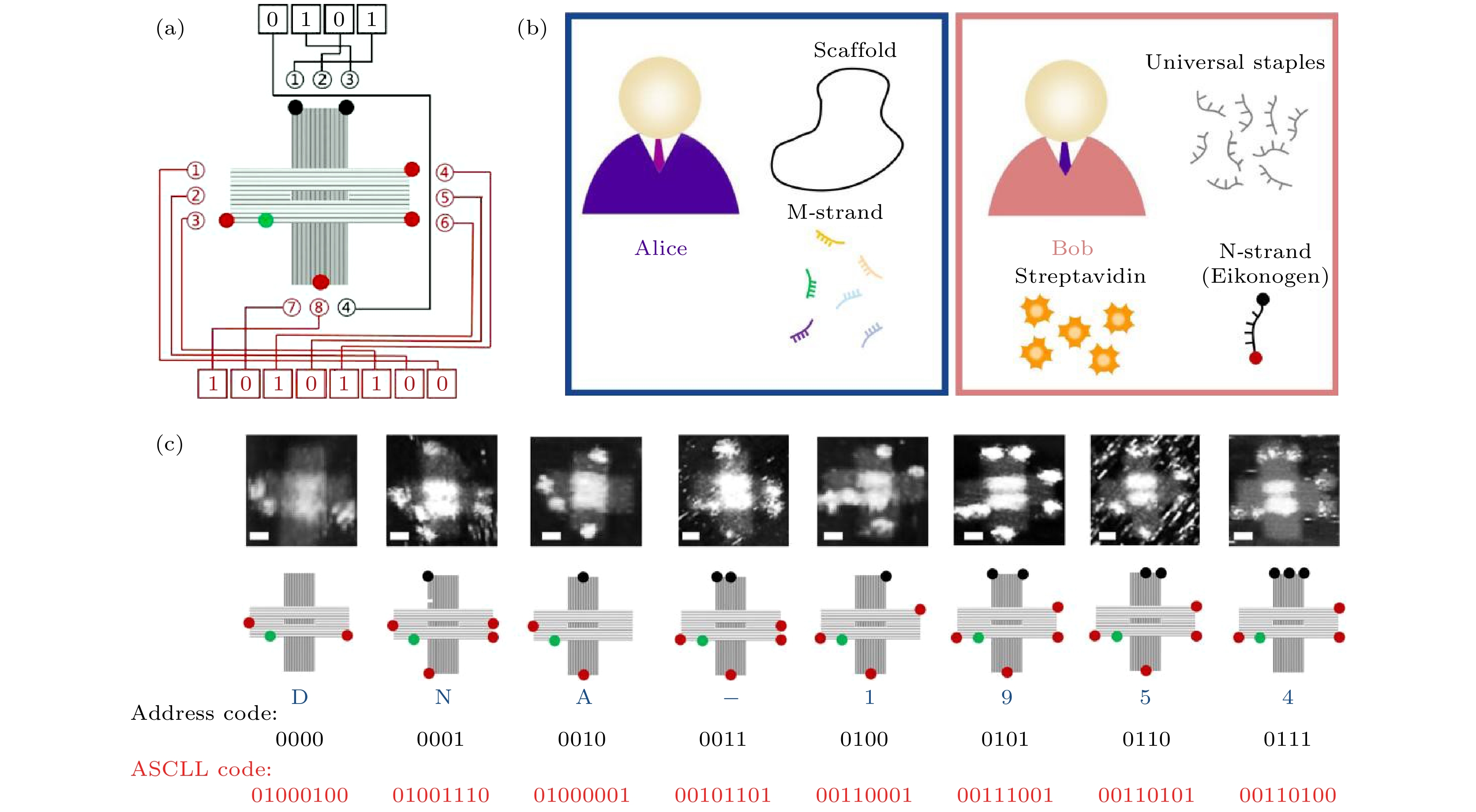
图 3 DNA折纸加密及编码原理示意图 (a) DNA折纸斑点编码原理; (b) 发送者(Alice)和接收者(Bob)通信流程; (c) 文本“DNA-1954”的编码演示(比例尺: 25 nm)
Fig. 3. Schematic illustration of DNA origami encryption and coding principle: (a) Coding principle of DNA origami spot; (b) the communication procedure between the sender (Alice) and the receiver (Bob); (c) coding demonstration of the text “DNA-1954” (scale bar: 25 nm).
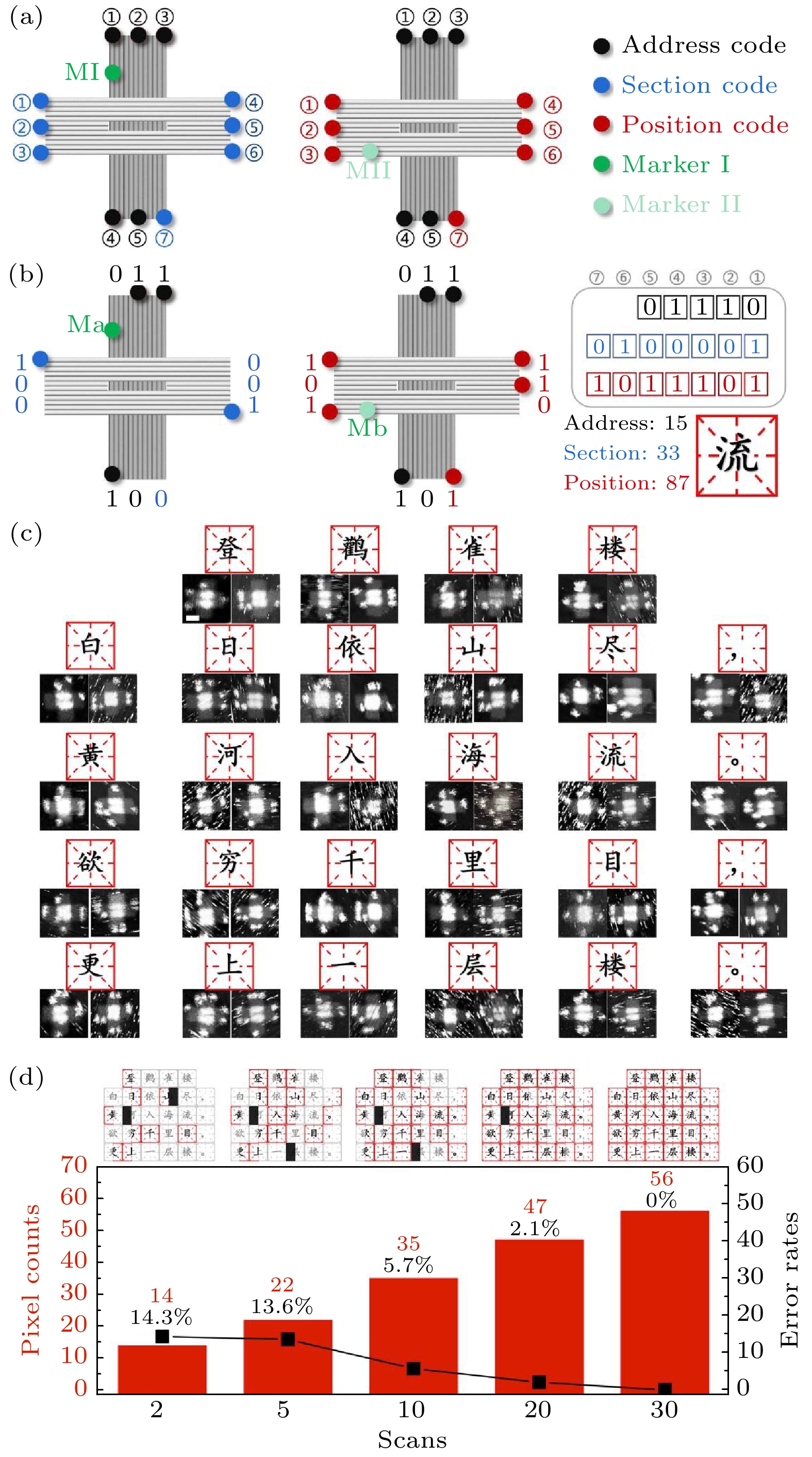
图 4 将汉字在DNA折纸上的加密方案 (a) 区位码在折纸上的编码原理; (b)汉字“流”的编码演示; (c) 28个汉字唐诗文本AFM实验图(比例尺: 40 nm); (d)唐诗随扫描次数收集完成度和错误率图, 正确收集标记为红色, 单个链霉亲和素图案未收集超过20个的标记为白色
Fig. 4. Scheme of encoding Chinese characters on DNA origami: (a) Encoding principle of section and position code on origami; (b) demonstration of Chinese encoding Chinese character “流” on DNA origami (scale bar: 100 nm); (c) AFM experimental graph of 28 Chinese characters Tang poetry text (scale bar: 40 nm); (d) collection completion and error rate graphs of Tang poetry with the number of scans completed and error rate graphs. The correct collection is marked as red, and the single streptavidin pattern which is not collected for more than 20 will be marked as white.
-
[1] Frank-Kamenetskii M, Mrikin S 1995 Annu. Rev. Biochem. 64 65
Google Scholar
[2] Wang J, Yue L, Wang S, Willner I 2018 ACS Nano 12 12324
Google Scholar
[3] Ge Z, Gu H, Li Q, Fan C H 2018 J. Am. Chem. Soc. 140 17808
Google Scholar
[4] Hu Q, Li H, Wang L, Gu H, Fan C H 2019 Chem. Rev. 119 6459
Google Scholar
[5] Rothemund P W 2006 Nature 440 297
Google Scholar
[6] Hong F, Zhang F, Liu Y, Yan H 2017 Chem. Rev. 117 12584
Google Scholar
[7] Qian L, Winfree E, Bruck J 2011 Nature 475 368
Google Scholar
[8] Chao J, Wang J, Wang F, Ouyang X, Kopperger E, Liu H J, Li Q, Shi J, Wang L, Hu J, Wang L, Huang W, Simmel F C, Fan C H 2019 Nat. Mater. 18 273
Google Scholar
[9] Zhang Z, Wang Y, Fan C H, Li C, Li Y, Qian L, Fu Y, Shi Y, Hu J, He L 2010 Adv. Mater. 22 2672
Google Scholar
[10] Wu N, Czajkowsky D M, Zhang J, Qu J, Ye M, Zeng D, Zhou X, Hu J, Shao Z, Li B, Fan C H 2013 J. Am. Chem. Soc. 135 12172
Google Scholar
[11] 贾思思, 晁洁, 樊春海, 柳华杰 2014 化学进展 26 695
Google Scholar
Jia S, Chao J, Fan C H, Liu H J 2014 Prog. Chem. 26 695
Google Scholar
[12] 张祎男, 王丽华, 柳华杰, 樊春海 2017 物理学报 66 147101
Google Scholar
Zhang Y N, Wang L H, Liu H J, Fan C H 2017 Acta Phys. Sin. 66 147101
Google Scholar
[13] Fang W, Jia S, Chao J, Wang L, Duan X, Liu H J, Li Q, Zuo X, Wang L, Liu N, Fan C H 2019 Sci. Adv. 5 eaau4506
Google Scholar
[14] Liu X, Zhang F, Jing X, Pan M, Liu P, Li W, Zhu B, Li J, Chen H, Wang L, Lin J, Liu Y, Zhao D, Yan H, Fan C H 2018 Nature 559 593
Google Scholar
[15] Yao G, Li J, Chao J, Pei H, Liu H J, Zhao Y, Shi J, Huang Q, Wang L, Huang W, Fan C H 2015 Angew. Chem. Int. Ed. Engl. 54 2966
Google Scholar
[16] Maune H T, Han S P, Barish R D, Bockrath M, Goddard W A, Rothemund P W, Winfree E 2010 Nat. Nanotechnol. 5 61
Google Scholar
[17] Ekert A K 1991 Phys. Rev. Lett. 67 661
Google Scholar
[18] Zhan P, Wen T, Wang Z G, He Y, Shi J, Wang T, Liu X, Lu G, Ding B 2018 Angew. Chem. Int. Ed. 57 2846
Google Scholar
[19] Douglas S, Bachelet I, Church J 2012 Science 335 831
Google Scholar
[20] Zhao Y, Shaw A, Zeng X, Benson E, Nyström A, Högberg B 2012 ACS Nano 6 8684
Google Scholar
[21] Zhang Q, Jiang Q, Li N, Dai L, Liu Q, Song L, Wang J, Li Y, Tian J, Ding B, Du Y 2014 ACS Nano 8 6633
Google Scholar
[22] Woods D, Doty D, Myhrvold C, Hui J, Zhou F, Yin P, Winfree E 2019 Nature 567 366
Google Scholar
[23] Ge Z, Liu J, Guo L, Yao G, Li Q, Wang L, Li J, Fan C H 2020 J. Am. Chem. Soc. 142 8800
Google Scholar
[24] Zhang Y N, Wang F, Chao J, Xie M, Liu H J, Pan M, Kopperger E, Liu X, Li Q, Shi J, Wang L, Hu J, Wang L, Simmel F C, Fan C H 2019 Nat. Commun. 10 5469
Google Scholar



 下载:
下载:
计量
- 文章访问数: 10801
- PDF下载量: 296
- 被引次数: 0
