











-
For the dynamic reconstruction of the chaotic dynamical system, a method of identifying an exponential weighted online sequential extreme learning machine with kernel(EW-KOSELM) is proposed. The kernel recursive least square (KRLS) algorithm is directly extended to an online sequential ELM framework, and weakens the effect of old data by introducing a forgetting factor. Meanwhile, the proposed algorithm can deal with the ever-increasing computational difficulties inherent in online kernel learning algorithms based on the ‘fixed-budget’ memory technique. The employed EW-KOSELM identification method is firstly applied to the numerical example of Duffing-Ueda oscillator for chaotic dynamical system based on simulated data, the qualitative and quantitative analysis for various validation tests of the dynamical properties of the original system as well as the identification model are carried out. A set of qualitative validation criteria is implemented by comparing chaotic attractors i.e. embedding trajectories, computing the corresponding Poincare mapping, plotting the bifurcation diagram, and plotting the steady-state trajectory i.e. the limit cycle between the original system and the identification model. Simultaneously, the quantitative validation criterion which includes computing the largest positive Lyapunov exponent and the correlation dimension of the chaotic attractors is also calculated to measure the closeness i.e. the approximation error between the original system and the identification model. The employed method is further applied to a practical implementation example of Chua's circuit based on the experimental data which are generated by sampling and recording the measured voltage across a capacitor, the inductor current from the double-scroll attractor, the measured voltage across a capacitor from the Chua's spiral attractor and an experimental time series from a chaotic circuit. The digital filtering technique is then used as a preprocessing approach, on the basis of wavelet denoising the measured data with lower signal-noise ratio (SNR) which can produce the double-scroll attractor or the spiral attractor, the reconstruction attractor of the identification model is compared with the reconstruction attractor from the experimental data for original system. The above experimental results confirm that the EW-FB-KOSELM identification method has a better performance of dynamic reconstruction, which can produce an accurate nonlinear model of process exhibiting chaotic dynamics. The identification model is dynamically equivalent or system approximation to the original system.
-
Keywords:
- dynamic reconstruction /
- chaotic system /
- kernel method /
- exponential weighted online sequential extreme learning machine
[1] Chen G R, Dong X N 1998 From Chaos to Order: Methodologies, Perspectives and Applications (Singapore: World Scientific) pp21-134
[2] [3] Aguirre L A, Letellier C 2009 Math. Probl. Eng. 2009 1
 Google Scholar
Google Scholar
[4] Ahmad T A, Sundarapandian V 2015 Chaos Modeling and Control Systems Design (Berlin: Springer-Verlag) pp59-72
[5] [6] Mattera D, Haykin S 1999 Advances in Kernel Methods: Support vector learning (Cambridge: MIT Press) p211
[7] Ishii S, Sato M A 2001 Neural Networks 14 1239
Google Scholar
[8] Zhang Z, Wang T, Liu X 2014 Neurocomputing 131 368
Google Scholar
[9] 李瑞国, 张宏立, 范文慧, 王雅 2015 物理学报 64 200506
Google Scholar
Li R G, Zhang H L, Fan W H, Wang Y 2015 Acta Phys. Sin. 64 200506
Google Scholar
[10] 王新迎, 韩敏 2015 物理学报 64 070504
Google Scholar
Wang X Y, Han M 2015 Acta Phys. Sin. 64 070504
Google Scholar
[11] Wen S, Zeng Z, Huang T, Chen Y 2013 Phys. Lett. A 377 2016
Google Scholar
[12] Miranian A, Abdollahzade M 2013 IEEE Trans. Neural Netw. Learn. Syst. 24 207
Google Scholar
[13] Shaw P K, Saha D, Ghosh S, Janaki M S, Lyengar A S 2015 Chaos Soliton. Fract. 78 285
Google Scholar
[14] Billings S A, Coca D 1999 Int. J. Bifurcat.Chaos 9 1263
Google Scholar
[15] Sanchez L, Infante S 2013 Chil. J. Stat. 4 35
[16] Aguirre L A, Teixeira B O S, Torres L A B 2005 Phys. Rev. E 72 026226
Google Scholar
[17] 李军, 董海鹰 2008 物理学报 57 4756
Google Scholar
Li J, Dong H Y 2008 Acta Phys. Sin. 57 4756
Google Scholar
[18] Huang G B, Zhu Q Y, Siew C K 2006 Neurocomputing 70 489
Google Scholar
[19] Liang N Y, Huang G B, Saratchandran P, Sundararajan N 2006 IEEE Trans. Neural Netw. 17 1411
Google Scholar
[20] Scardapane S, Comminiello D, Scarpiniti M, Uncini A 2015 IEEE Trans. Neural Netw. Learn. Syst. 26 2214
[21] Vaerenbergh S V, Santamaria I, Liu W, Principe J C 2010 The 35th IEEE International Conference on Acoustics Speech & Signal Processing Dallas, Texas, USA, March 14-19, 2010 p1882
[22] Liu W, Principe J C, Haykin S 2010 Kernel Adaptive Filtering: A Comprehensive Introduction pp108-110
[23] Engel Y, Mannor S, Meir R 2004 IEEE Trans. Signal Process. 52 2275
Google Scholar
[24] se Kruif B J, de Vries T J A 2003 IEEE Trans. Neural Netw. 14 696
Google Scholar
[25] Ueda Y 1985 Int. J. Nonlin. Mech. 20 481
Google Scholar
[26] Yang Z, Gao Y, Gao Y, Zhang J 2009 Chin. Phys. Lett. 26 060506
Google Scholar
[27] Odavic J, Mali P, Tekic J, Pantic M, Pavkov-Hrvojevic M 2017 Commun. Nonlinear Sci. Numer. Simul. 47 100
Google Scholar
[28] Suykens J A K, Vandewalle J 1995 IEEE Trans. Circ. Syst. Fund. Theor. Appl. 42 499
Google Scholar
[29] Cannas B, Cincotti S, Marchesi M, Pilo F 2001 Chaos Soliton. Fract. 12 2109
Google Scholar
[30] Aguirre L A, Rodrigues G G, Mendes E M 1997 Int. J. Bifurcat. Chaos 7 1411
Google Scholar
[31] Kennedy M P 1992 Frequenz 46 66
Google Scholar
[32] Timmer J, Rust H, Horbelt W, Voss H U 2000 Phys. Lett. A 274 123
Google Scholar
-
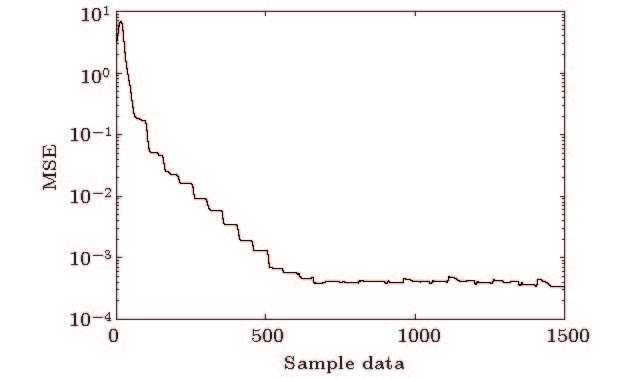
图 1 算法的均方误差收敛曲线
Figure 1. Convergence curve of MSE for FB-EW-KOSELM algorithm.
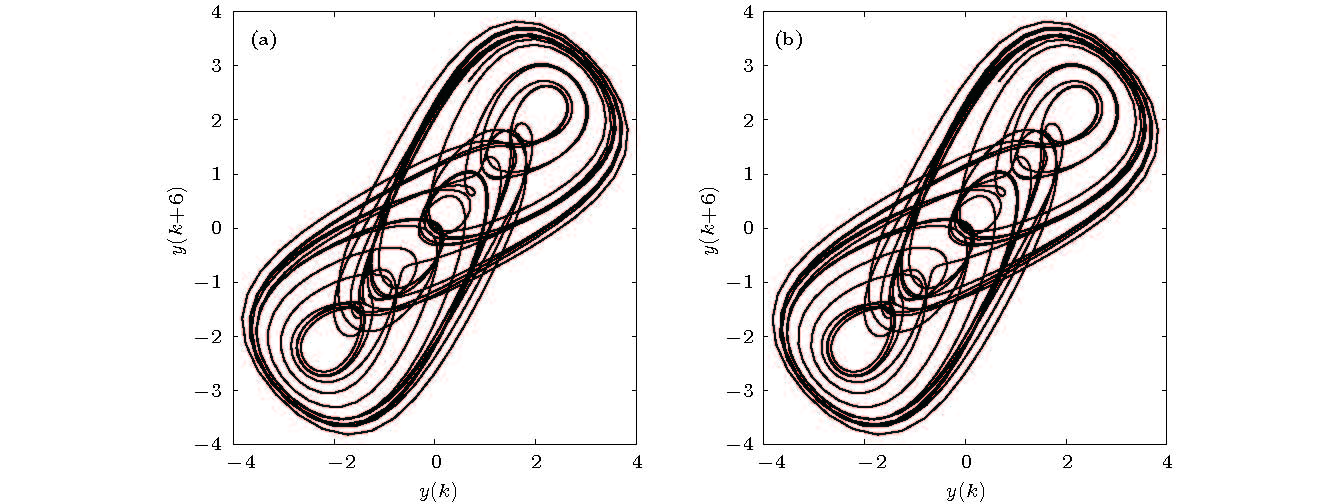
图 2 Duffing吸引子(F = 11) (a)原模型; (b)辨识模型
Figure 2. Duffing attractor for F = 11 plotted using: (a)The original noise-free data; (b) the model predicted output.
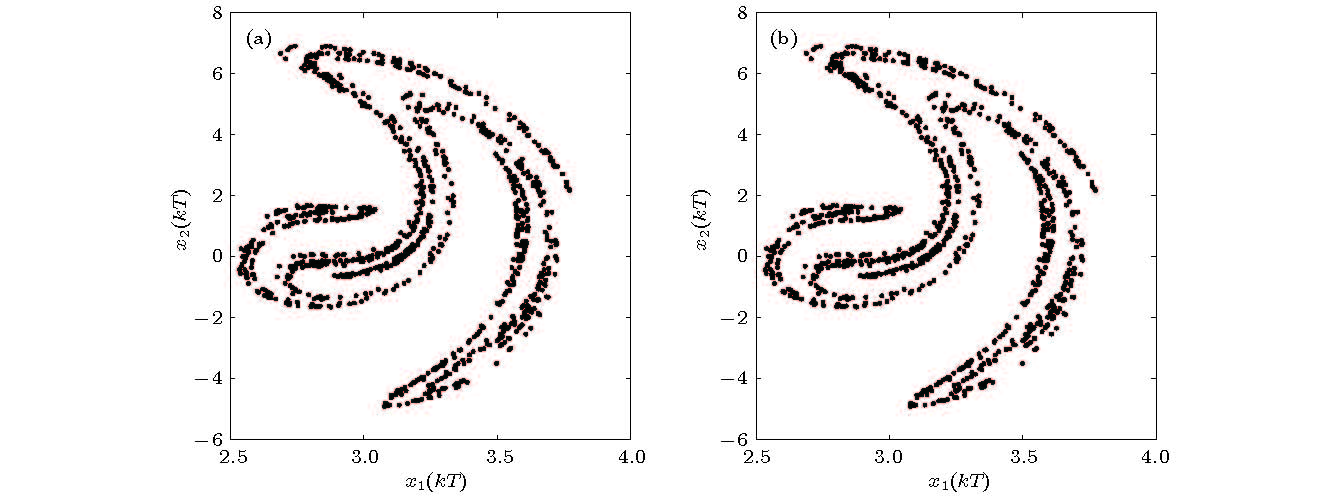
图 3 庞加莱映射(F = 11) (a)原模型; (b)辨识模型
Figure 3. The Poincare map(F = 11) for (a) the original system, (b) the identification model.
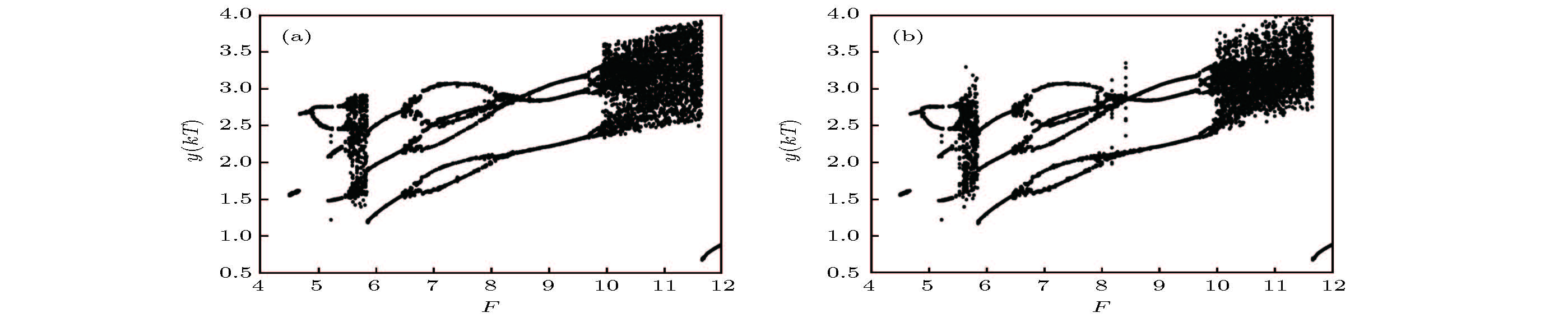
图 4 Duffing-Ueda振子的分岔图 (a)原模型; (b)辨识模型
Figure 4. Bifurcation diagram 4.5 ≤ F ≤ 12: (a) Original system; (b) identification model.
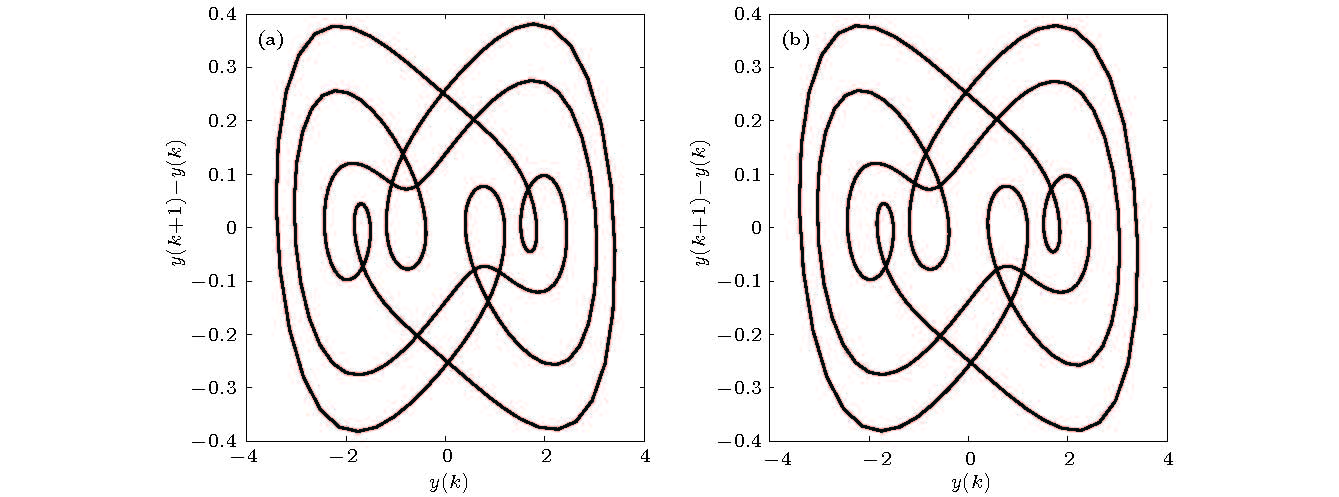
图 5 F = 8.5时Duffing-Ueda振子的极限环 (a)原模型; (b)辨识模型
Figure 5. Limit cycle for F = 8.5: (a) Original system; (b) identification model.
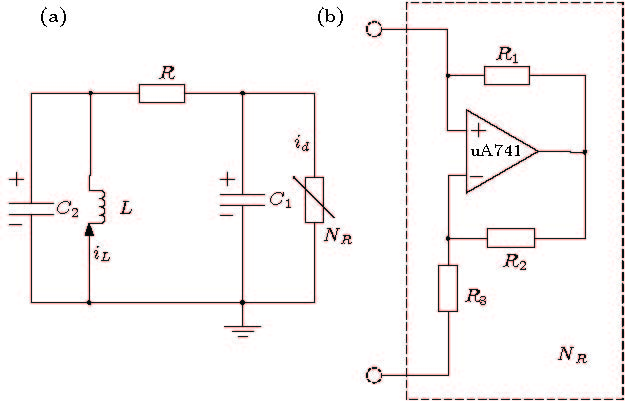
图 6 (a)蔡氏电路; (b)蔡氏二极管(非线性电阻的配置)
Figure 6. (a)Chua’s circuit ; (b) Chua’s diode (nonlinear resistor implementation).
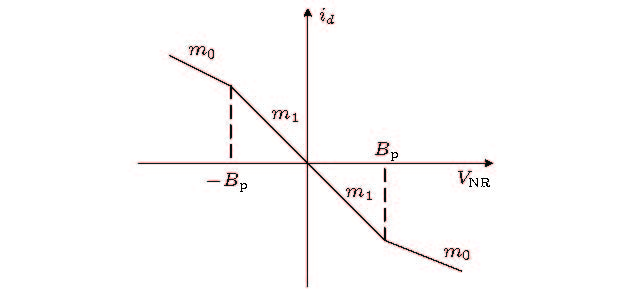
图 7 蔡氏二极管的伏安特性曲线
Figure 7. Volt-ampere characteristic curve of Chua’s diode.
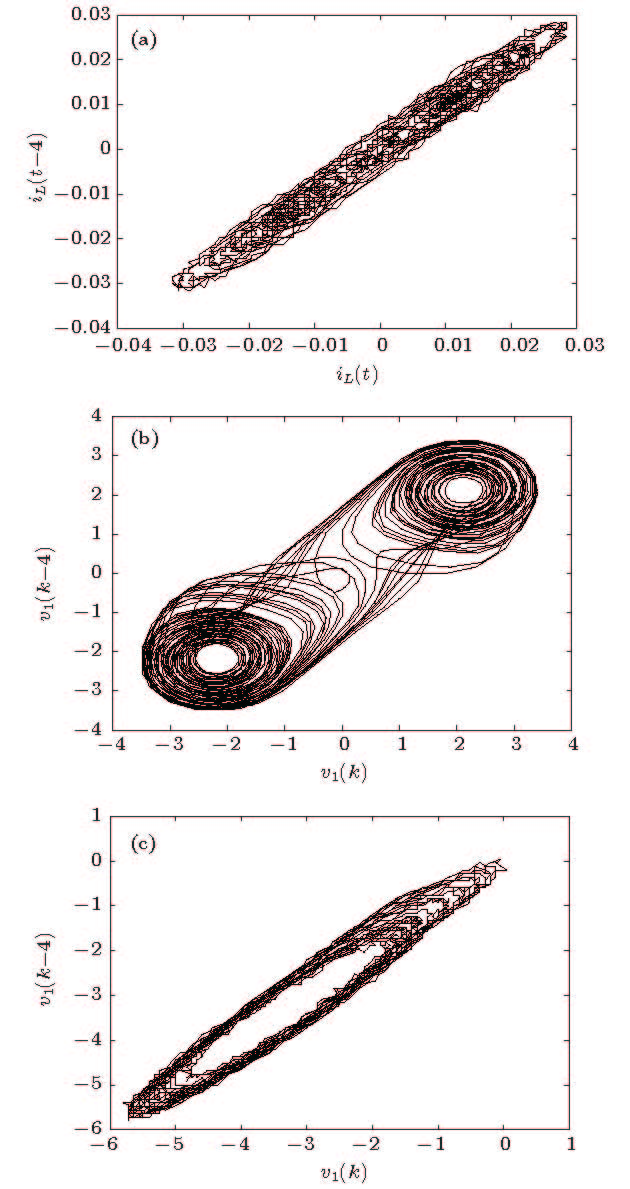
图 8 基于实测数据的蔡氏电路吸引子
Figure 8. Measured data on the attractor of Chua’s circuit: (a) Projection of the double scroll attractor, measures of
${i_L}$ ; (b) measures of${v_1}$ ; (c) projection of the spiral attractor, measures of${v_1}$ .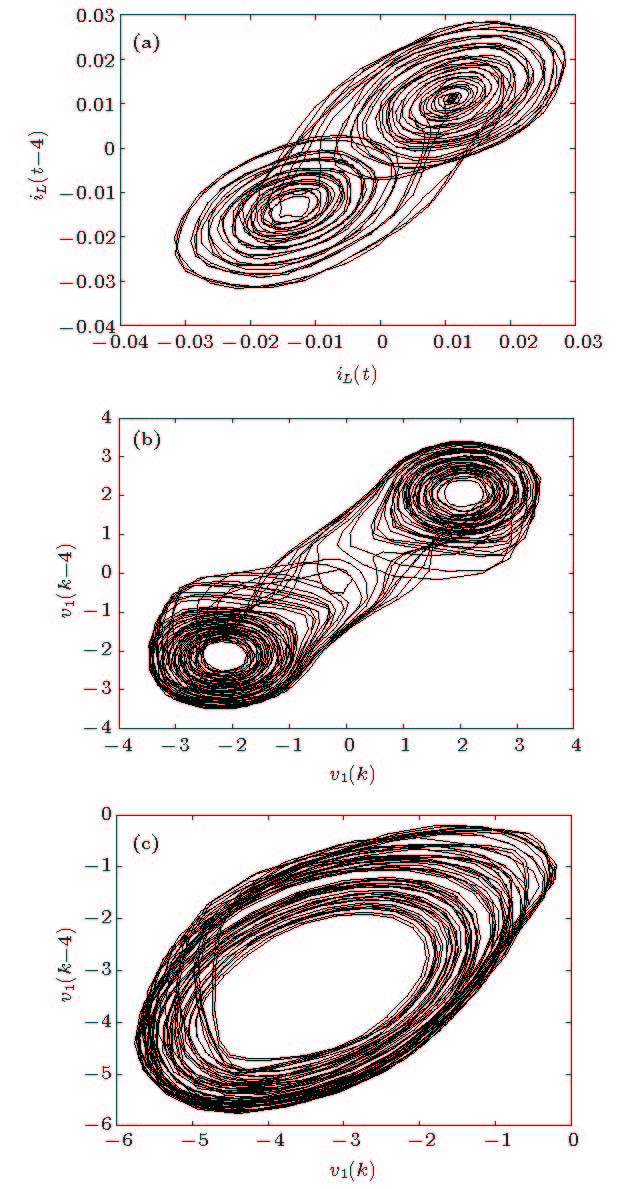
图 9 基于模型预测输出的蔡氏电路重构吸引子 (a)双涡卷吸引子iL; (b) 双涡卷吸引子v1; (c)螺旋吸引子v1
Figure 9. Chua's attractor reconstructed from the model predicted output: (a) iL on the double scroll attractor; (b)v1 on the double scroll attractor; (c) v1 on the spiral attractor
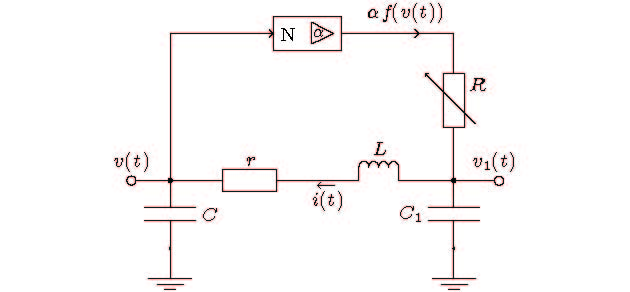
图 10 混沌电路的构成
Figure 10. Block diagram of the chaotic circuit.
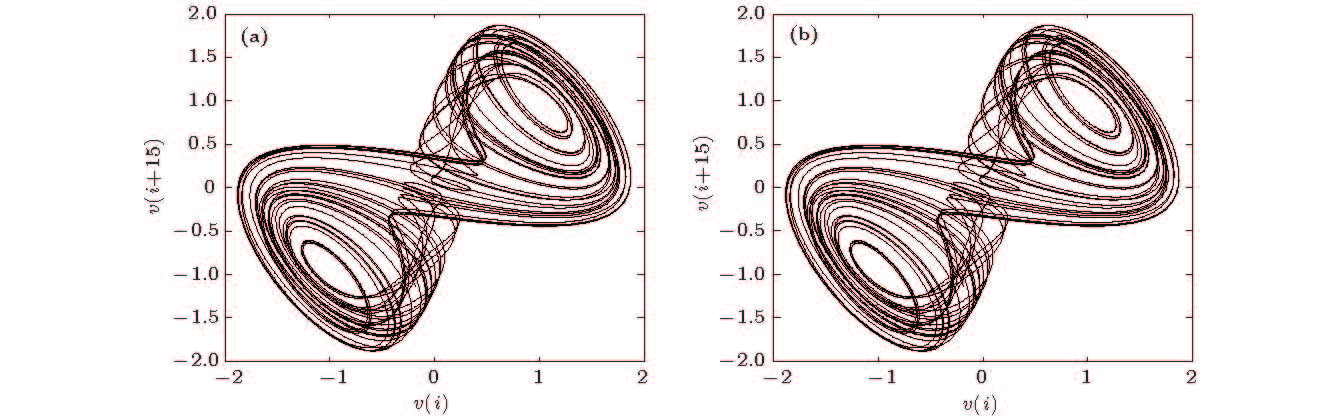
图 11 重构吸引子 (a)原模型; (b)辨识模型
Figure 11. Reconstructed attractor: (a) The original noise-free data; (b) the model predicted output.
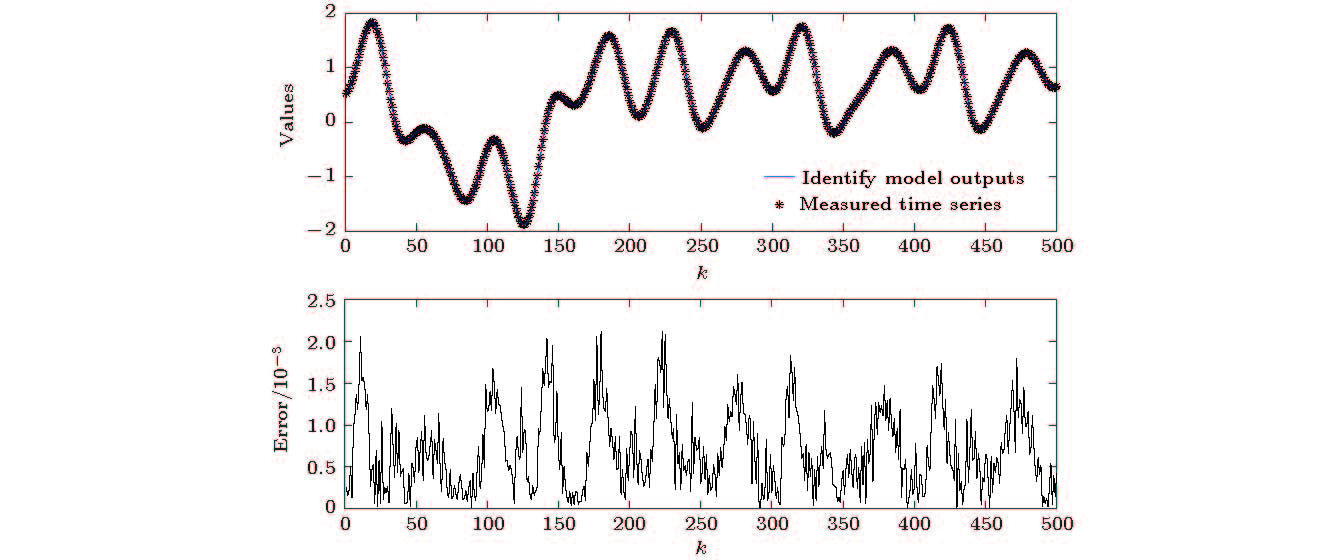
图 12 (a)辨识模型输出与实测时间序列值输出结果; (b)辨识误差
Figure 12. (a) Identify model outputs and measured time series values; (b) the error between the model output and the measured value.
-
[1] Chen G R, Dong X N 1998 From Chaos to Order: Methodologies, Perspectives and Applications (Singapore: World Scientific) pp21-134
[2] [3] Aguirre L A, Letellier C 2009 Math. Probl. Eng. 2009 1
Google Scholar
[4] Ahmad T A, Sundarapandian V 2015 Chaos Modeling and Control Systems Design (Berlin: Springer-Verlag) pp59-72
[5] [6] Mattera D, Haykin S 1999 Advances in Kernel Methods: Support vector learning (Cambridge: MIT Press) p211
[7] Ishii S, Sato M A 2001 Neural Networks 14 1239
Google Scholar
[8] Zhang Z, Wang T, Liu X 2014 Neurocomputing 131 368
Google Scholar
[9] 李瑞国, 张宏立, 范文慧, 王雅 2015 物理学报 64 200506
Google Scholar
Li R G, Zhang H L, Fan W H, Wang Y 2015 Acta Phys. Sin. 64 200506
Google Scholar
[10] 王新迎, 韩敏 2015 物理学报 64 070504
Google Scholar
Wang X Y, Han M 2015 Acta Phys. Sin. 64 070504
Google Scholar
[11] Wen S, Zeng Z, Huang T, Chen Y 2013 Phys. Lett. A 377 2016
Google Scholar
[12] Miranian A, Abdollahzade M 2013 IEEE Trans. Neural Netw. Learn. Syst. 24 207
Google Scholar
[13] Shaw P K, Saha D, Ghosh S, Janaki M S, Lyengar A S 2015 Chaos Soliton. Fract. 78 285
Google Scholar
[14] Billings S A, Coca D 1999 Int. J. Bifurcat.Chaos 9 1263
Google Scholar
[15] Sanchez L, Infante S 2013 Chil. J. Stat. 4 35
[16] Aguirre L A, Teixeira B O S, Torres L A B 2005 Phys. Rev. E 72 026226
Google Scholar
[17] 李军, 董海鹰 2008 物理学报 57 4756
Google Scholar
Li J, Dong H Y 2008 Acta Phys. Sin. 57 4756
Google Scholar
[18] Huang G B, Zhu Q Y, Siew C K 2006 Neurocomputing 70 489
Google Scholar
[19] Liang N Y, Huang G B, Saratchandran P, Sundararajan N 2006 IEEE Trans. Neural Netw. 17 1411
Google Scholar
[20] Scardapane S, Comminiello D, Scarpiniti M, Uncini A 2015 IEEE Trans. Neural Netw. Learn. Syst. 26 2214
[21] Vaerenbergh S V, Santamaria I, Liu W, Principe J C 2010 The 35th IEEE International Conference on Acoustics Speech & Signal Processing Dallas, Texas, USA, March 14-19, 2010 p1882
[22] Liu W, Principe J C, Haykin S 2010 Kernel Adaptive Filtering: A Comprehensive Introduction pp108-110
[23] Engel Y, Mannor S, Meir R 2004 IEEE Trans. Signal Process. 52 2275
Google Scholar
[24] se Kruif B J, de Vries T J A 2003 IEEE Trans. Neural Netw. 14 696
Google Scholar
[25] Ueda Y 1985 Int. J. Nonlin. Mech. 20 481
Google Scholar
[26] Yang Z, Gao Y, Gao Y, Zhang J 2009 Chin. Phys. Lett. 26 060506
Google Scholar
[27] Odavic J, Mali P, Tekic J, Pantic M, Pavkov-Hrvojevic M 2017 Commun. Nonlinear Sci. Numer. Simul. 47 100
Google Scholar
[28] Suykens J A K, Vandewalle J 1995 IEEE Trans. Circ. Syst. Fund. Theor. Appl. 42 499
Google Scholar
[29] Cannas B, Cincotti S, Marchesi M, Pilo F 2001 Chaos Soliton. Fract. 12 2109
Google Scholar
[30] Aguirre L A, Rodrigues G G, Mendes E M 1997 Int. J. Bifurcat. Chaos 7 1411
Google Scholar
[31] Kennedy M P 1992 Frequenz 46 66
Google Scholar
[32] Timmer J, Rust H, Horbelt W, Voss H U 2000 Phys. Lett. A 274 123
Google Scholar

 DownLoad:
DownLoad:



Catalog
Metrics
- Abstract views: 15771
- PDF Downloads: 99
- Cited By: 0
