










-
近年来, 随着国际核军控形势的变化, 包含防扩散、防核恐及核安保的多边国际军控合作越来越受到重视. 核取证技术作为防扩散、防核恐及核安保的一项核心技术, 在对涉核非法活动的威慑、阻止以及响应方面具有重要作用, 值得深入研究. 目前针对核取证技术的研究较多, 主要集中于材料的表征和数据的解读. 其中解读作为核取证研究技术中最重要的一环, 所面对的对象是多种多样的, 包括铀矿石、黄饼、核燃料、乏燃料等, 而其中乏燃料由于其潜在的威胁越来越受到重视. 本文聚焦于在核取证场景中利用多元统计分析方法进行乏燃料鉴别的研究, 主要是利用因子分析、判别分析和回归分析方法对乏燃料组分进行分析, 研究各方法的适用范围, 并为未来可能的利用数据库进行乏燃料鉴别的工作提供理论依据与可行方案, 为相关核取证溯源工作的顺利开展提供支撑.In recent years, as the international situation about nuclear arms control changes, the multilateral international arms control cooperation including non-proliferation, nuclear terrorism and nuclear security has drawn more and more attention. As a key technology, nuclear forensics plays a significant role in the deterrence, prevention and response to illegitimate nuclear activities, for which it needs studying in depth. At present, there are plenty of researches into nuclear forensics, mostly focusing on the characterization of materials and the interpretation of data. As one of the most important aspects of nuclear forensics research, the interpretation is faced with a variety of different objects, including uranium ore, yellow cake, nuclear fuel, spent nuclear fuel and so on, among which spent nuclear fuel has attracted more and more attention due to its potential threats. In this paper, we primarily focus on the development of multivariate statistical analysis with an aim to interpret the comparative signatures of spent nuclear fuel. A database is established with uranium and plutonium isotopic compositions of spent nuclear fuel samples through simulation. These samples are of different reactor types, initial fuel enrichments and burn-ups. Subsequently, multivariate analysis, including factor analysis, discriminant analysis and regression analysis, are used to the database to validate the feasibility of the identification work. First of all, dimension reduction and visualization work is carried out to determine the possibility for classification by factor analysis. Afterwards, some known samples are assumed to be unknown to further study the possible capabilities of quantitative attribution by conducting factor analysis, including the determination of initial fuel enrichment and burn-up. To eliminate the errors in the identification work and to achieve better outcomes, the discriminant analysis and regression analysis are used to the database to assist with the identification of the reactor type, initial fuel enrichment and burn-up. As revealed by the study, factor analysis is more suitable for the dimension reduction and visualization work, disciminant analysis is more suitable for the identification of reactor type, and regression analysis is more suitable for the identification of initial fuel enrichment and burn-up. Upon the comparison drawn of the three different multivariate analysis methods, a framework for identification process is established to provide a theoretical basis and feasible scheme for the possible identification work of spent nuclear fuel with database, and facilitate the related nuclear forensics work.
-
Keywords:
- multivariate analysis /
- nuclear forensics /
- nuclear security
[1] IAEA 2012 Nuclear Forensics Support: Reference Manual (Vienna: IAEA) pp3−34
[2] [3] Robel M, Kristo M J, Heller M A 2009 Institute of Nuclear Materials Management Annual Meeting Tucson, USA, July 12−16, 2009 p414001
[4] IAEA 2015 Nuclear Forensics in Support of Investigations Implement Guide (Vienna: IAEA) pp27−28
[5] 苏佳杭 2014 2014国际军备控制与裁军 (北京: 世界知识出版社) 第29页
Su J H 2014 2014 International Arms Control and Disarmament (Beijing: World Affairs Press) p29 (in Chinese)
[6] Croff A 1983 Nucl. Technol. 62 335
 Google Scholar
Google Scholar
[7] Nicolaou G 2006 J. Environ. Radioact. 86 313
Google Scholar
[8] Nicolaou G 2008 J. Environ. Radioact. 99 1708
Google Scholar
[9] Nicolaou G 2008 J. Radioanal. Nucl. Chem. 279 503
Google Scholar
[10] Nicolaou G 2014 Ann. Nucl. Energy 72 130
[11] Robel M, Kristo M J 2008 J. Environ. Radioact. 99 1789
[12] Jones A, Turner P, Zimmerman C, Goulermas J Y 2014 Anal. Chem. 86 5399
Google Scholar
[13] Dayman K, Coble J, Orton C, Schwantes J 2014 Nucl. Instrum. Meth. Phys. Res., Sect. A 735 624
Google Scholar
[14] Coble J, Orton C, Schwantes J 2017 Nucl. Instrum. Methods Phys. Res. Sect. A 850 18
Google Scholar
[15] Belkin M, Niyogi P 2003 P. Neural Comput. 15 1373
Google Scholar
[16] Breiman L 2001 Mach. Learn. 45 5
Google Scholar
[17] Parzen E 1962 Ann. Math. Stat. 33 1065
Google Scholar
[18] Pan Z W 2008 J. Complexity 24 606
Google Scholar
[19] Raymenm M, Sanschagrin P, Punch W, Venkataraman S, Goodman E, Kuhn L 1997 Am. J. Mol. Biol. 265 445
Google Scholar
[20] Kowalski B, Bender C 1972 Anal. Chem. 44 1405
Google Scholar
[21] Cover T, Hart P 1967 IEEE Trans. Inf. Theory 13 21
Google Scholar
[22] Yi T, Lander E 1993 Am. J. Mol. Biol. 232 1117
Google Scholar
[23] Wu W, Mallet Y, Walczak B, Penninckx W, Masssart D, Heuerding S 1996 Anal. Chim. Acta 329 257
Google Scholar
[24] Maraini F, Balestrieri F, Bucci R, Magrí A, Marini D 2004 Chemom. Intell. Lab. Syst. 73 85
Google Scholar
[25] Fisher R 1936 Ann. Hum. Genet. 7 178
[26] Hui X, Sun J 2006 Lecture Notes in Artificial Intelligence (Berlin: Spring-Verlag) p274
[27] Cortes C, Vapnik V 1995 Int. J. Mach. Learn. Cybern. 20 273
[28] 高惠璇 2005 应用多元统计分析 (北京: 北京大学出版社) 第293−321页
Gao H X 2005 Applied Multivariate Statistical Analysis (Beijing: Peking University Press) pp293−321 (in Chinese)
[29] 徐雪峰, 付元光, 朱剑钰, 李瑞, 田东风, 伍钧, 李凯波 2017 物理学报 66 082801
Google Scholar
Xu X F, Fu Y G, Zhu J Y, Li R, Tian D F, Wu J, Li K B 2017 Acta Phys. Sin. 66 082801
Google Scholar
[30] 师学明, 张本爱 2010 核动力工程 31 1
Shi X M, Zhang B A 2010 Nucl. Power Eng. 31 1
[31] Su J H, Wu J, Hu S D 2019 Ann. Nucl. Energ. 126 43
Google Scholar
-
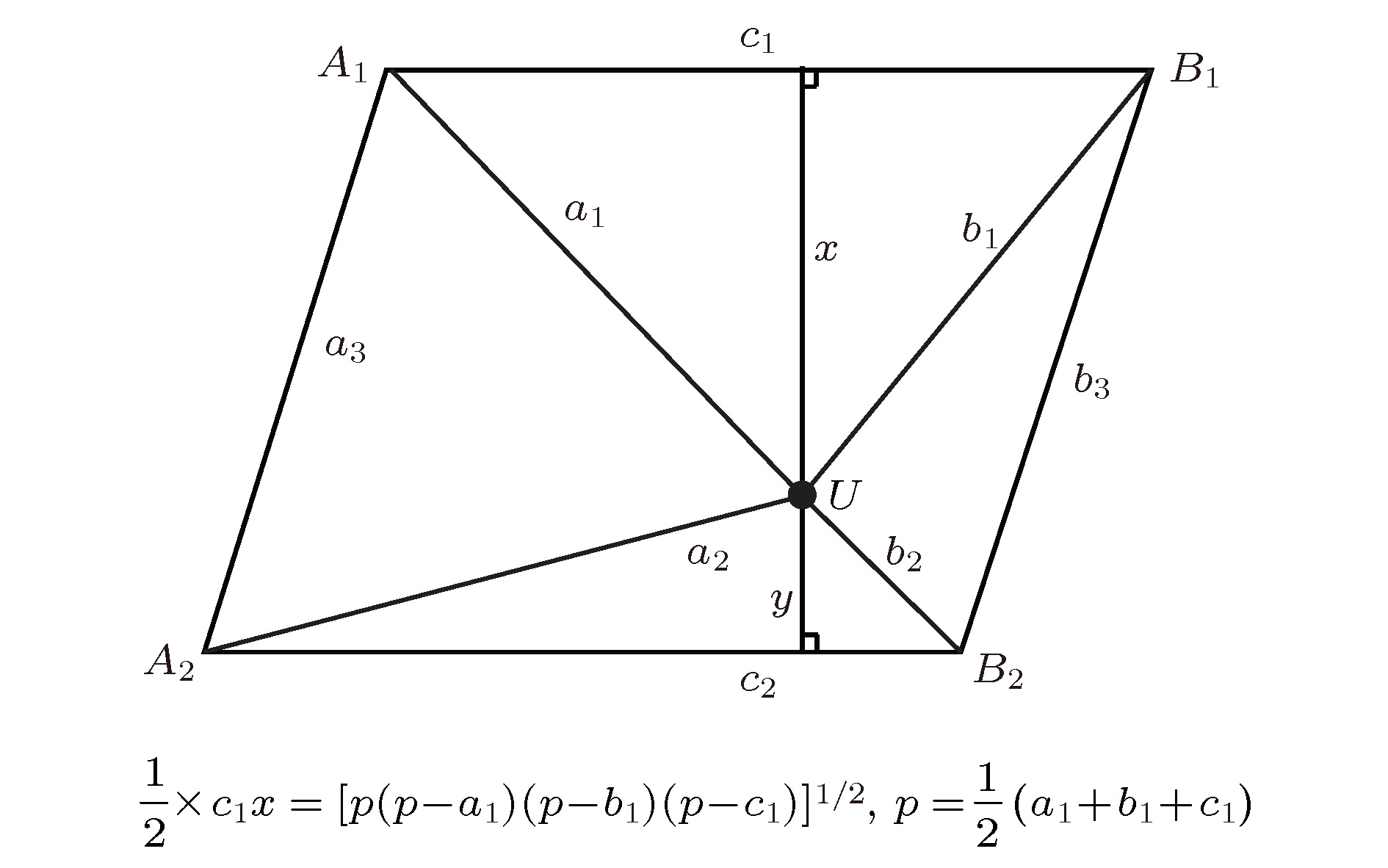
图 2 海伦公式示意图(U点为未知样品点, A1, A2, B1, B2为已知样品点)
Fig. 2. Diagram for Heron’s formula (U stands for unknown sample, A1, A2, B1, B2 stand for known samples).
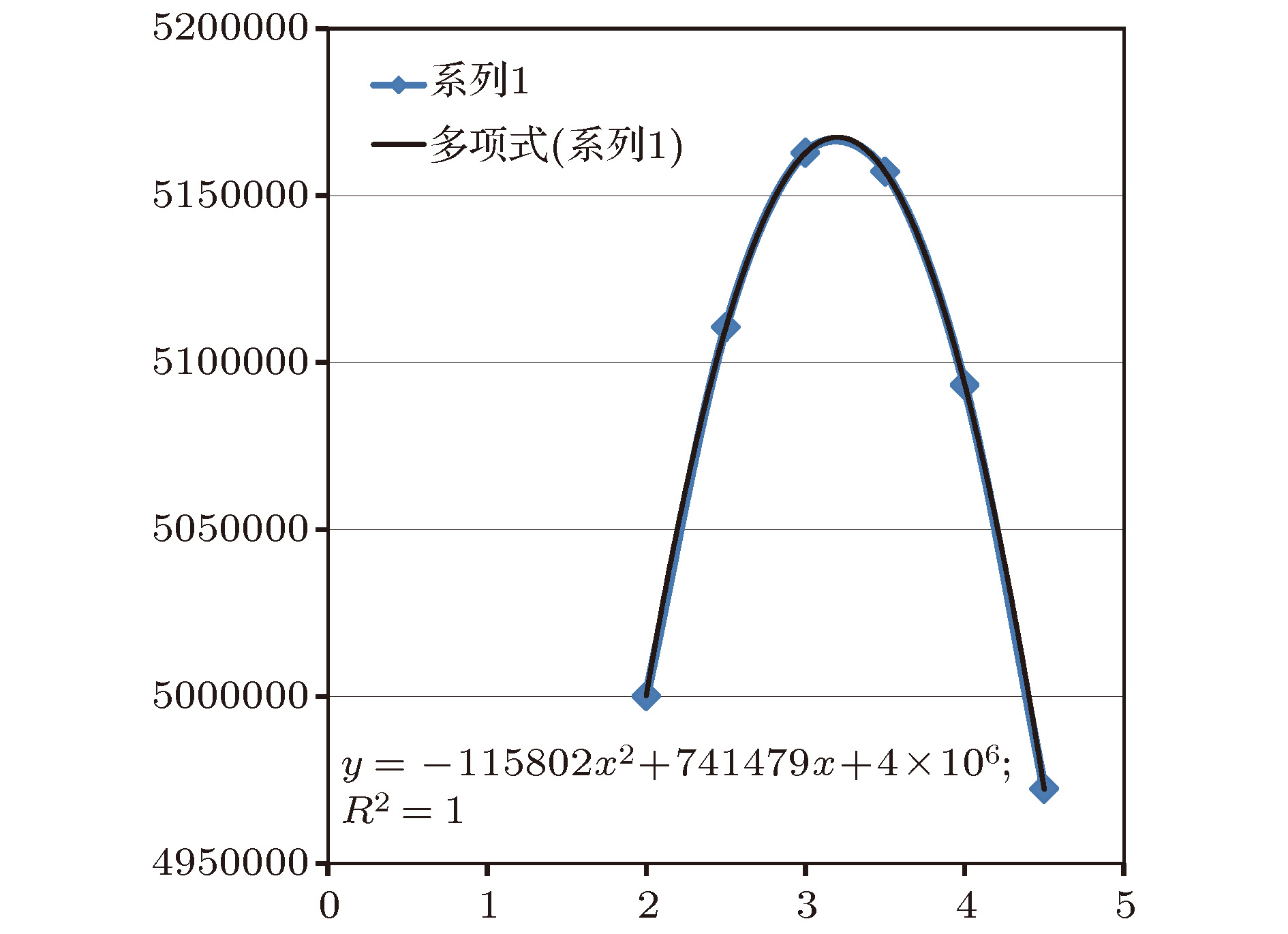
图 3 对未知样品1的各线性函数值的多项式拟合
Fig. 3. The Polynomial fitting of the linear function values of unknown sample 1.
表 1 反应堆模拟的输入参数
Table 1. Input parameters for reactor simulation.
堆型 初始装料 丰度 燃耗/GWd·tU-1 PWR UO2 2%—4.5% 5—50 PWR MOX 天然铀, 4%—5%裂变钚 30—50 CANDU UO2 0.711% 0.3, 2—8 CANDU UO2 1.2% 5—20 LMFBR MOX 80%的贫化铀(0.2%以下), 12%的Pu-239, 8%的Pu-240 50—100 MAGNOX (HTGR) UO2 0.711% 1—10 GCR (HTGR) UO2 1%—4% 1—20 HTGR UO2 10%—30% 5—30  下载: 导出CSV
下载: 导出CSV
表 2 未知乏燃料的输入参数
Table 2. Input parameters for unknown spent nuclear fuel.
未知样品 模拟参数 堆型 初始装料 燃耗/GWd·tU–1 1 PWR UO2, 3.2% 23 2 PWR MOX, 4.7% 裂变钚 38 3 HTGR UO2, 18% 27
下载: 导出CSV
表 3 因子分析鉴别结果
Table 3. Result of identification by using factor analysis.
未知样品 模拟参数 预测参数 相对误差 堆型 初始装料 燃耗/GWd·tU–1 堆型 初始装料 燃耗/GWd·tU–1 初始装料 燃耗/GWd·tU–1 1 PWR UO2, 3.2% 23 PWR 3.197% 23.104 0.5% 2.08% 2 PWR MOX, 4.7%裂变钚 38 PWR 4.686% 38.324 2.78% 6.49% 3 HTGR UO2, 18% 27 HTGR 17.855% 27.328 2.91% 6.55%
下载: 导出CSV
表 4 反应堆类型判断结果
Table 4. Result for the determination of reactor type.
未知样品 分类 概率 真实 预测 1(PWR UO2) 2(PWR MOX) 3(CANDU) 4(LMFBR) 5(MAGNOX) 6(GCR) 7(HTGR) Uk1 1 1 0.9852 0 0.0148 0 0 0 0 Uk2 2 2 0 1 0 0 0 0 0 Uk3 7 7 0 0 0 0 0 0 1
下载: 导出CSV
表 5 线性判别分析与因子分析结果比较
Table 5. The comparation of the results from discrimination analysis and factor analysis.
未知样品 模拟参数 因子分析结果 线性判别分析结果 初始装料 燃耗/GWd·tU–1 初始装料 燃耗/GWd·tU–1 初始装料 燃耗/GWd·tU–1 1 UO2, 3.2% 23 3.197% 23.104 3.201% 23.0361 2 MOX, 4.7%裂变钚 38 4.686% 38.324 4.703% 37.9312 3 UO2,18% 27 17.855% 27.328 18.003% 27.9196
下载: 导出CSV
表 6 利用线性回归分析进行初始装料与燃耗的鉴别分析的结果
Table 6. Results for the determination of initial enrichment of uranium and burn-up by linear regression analysis.
未知样品 模拟参数 因子分析结果 线性判别分析结果 线性回归分析结果 初始装料 燃耗/GWd·tU–1 初始装料 燃耗/GWd·tU–1 初始装料 燃耗/GWd·tU–1 初始装料 燃耗/GWd·tU–1 1 UO2, 3.2% 23 3.197% 23.104 3.201% 23.0361 3.2005% 23.022 2 MOX, 4.7%裂变钚 38 4.686% 38.324 4.703% 37.9312 4.6993% 38.019 3 UO2, 18% 27 17.855% 27.328 18.003% 27.9196 18.001% 26.991
下载: 导出CSV
-
[1] IAEA 2012 Nuclear Forensics Support: Reference Manual (Vienna: IAEA) pp3−34
[2] [3] Robel M, Kristo M J, Heller M A 2009 Institute of Nuclear Materials Management Annual Meeting Tucson, USA, July 12−16, 2009 p414001
[4] IAEA 2015 Nuclear Forensics in Support of Investigations Implement Guide (Vienna: IAEA) pp27−28
[5] 苏佳杭 2014 2014国际军备控制与裁军 (北京: 世界知识出版社) 第29页
Su J H 2014 2014 International Arms Control and Disarmament (Beijing: World Affairs Press) p29 (in Chinese)
[6] Croff A 1983 Nucl. Technol. 62 335
Google Scholar
[7] Nicolaou G 2006 J. Environ. Radioact. 86 313
Google Scholar
[8] Nicolaou G 2008 J. Environ. Radioact. 99 1708
Google Scholar
[9] Nicolaou G 2008 J. Radioanal. Nucl. Chem. 279 503
Google Scholar
[10] Nicolaou G 2014 Ann. Nucl. Energy 72 130
[11] Robel M, Kristo M J 2008 J. Environ. Radioact. 99 1789
[12] Jones A, Turner P, Zimmerman C, Goulermas J Y 2014 Anal. Chem. 86 5399
Google Scholar
[13] Dayman K, Coble J, Orton C, Schwantes J 2014 Nucl. Instrum. Meth. Phys. Res., Sect. A 735 624
Google Scholar
[14] Coble J, Orton C, Schwantes J 2017 Nucl. Instrum. Methods Phys. Res. Sect. A 850 18
Google Scholar
[15] Belkin M, Niyogi P 2003 P. Neural Comput. 15 1373
Google Scholar
[16] Breiman L 2001 Mach. Learn. 45 5
Google Scholar
[17] Parzen E 1962 Ann. Math. Stat. 33 1065
Google Scholar
[18] Pan Z W 2008 J. Complexity 24 606
Google Scholar
[19] Raymenm M, Sanschagrin P, Punch W, Venkataraman S, Goodman E, Kuhn L 1997 Am. J. Mol. Biol. 265 445
Google Scholar
[20] Kowalski B, Bender C 1972 Anal. Chem. 44 1405
Google Scholar
[21] Cover T, Hart P 1967 IEEE Trans. Inf. Theory 13 21
Google Scholar
[22] Yi T, Lander E 1993 Am. J. Mol. Biol. 232 1117
Google Scholar
[23] Wu W, Mallet Y, Walczak B, Penninckx W, Masssart D, Heuerding S 1996 Anal. Chim. Acta 329 257
Google Scholar
[24] Maraini F, Balestrieri F, Bucci R, Magrí A, Marini D 2004 Chemom. Intell. Lab. Syst. 73 85
Google Scholar
[25] Fisher R 1936 Ann. Hum. Genet. 7 178
[26] Hui X, Sun J 2006 Lecture Notes in Artificial Intelligence (Berlin: Spring-Verlag) p274
[27] Cortes C, Vapnik V 1995 Int. J. Mach. Learn. Cybern. 20 273
[28] 高惠璇 2005 应用多元统计分析 (北京: 北京大学出版社) 第293−321页
Gao H X 2005 Applied Multivariate Statistical Analysis (Beijing: Peking University Press) pp293−321 (in Chinese)
[29] 徐雪峰, 付元光, 朱剑钰, 李瑞, 田东风, 伍钧, 李凯波 2017 物理学报 66 082801
Google Scholar
Xu X F, Fu Y G, Zhu J Y, Li R, Tian D F, Wu J, Li K B 2017 Acta Phys. Sin. 66 082801
Google Scholar
[30] 师学明, 张本爱 2010 核动力工程 31 1
Shi X M, Zhang B A 2010 Nucl. Power Eng. 31 1
[31] Su J H, Wu J, Hu S D 2019 Ann. Nucl. Energ. 126 43
Google Scholar

 下载:
下载:

计量
- 文章访问数: 12027
- PDF下载量: 58
- 被引次数: 0
