










-
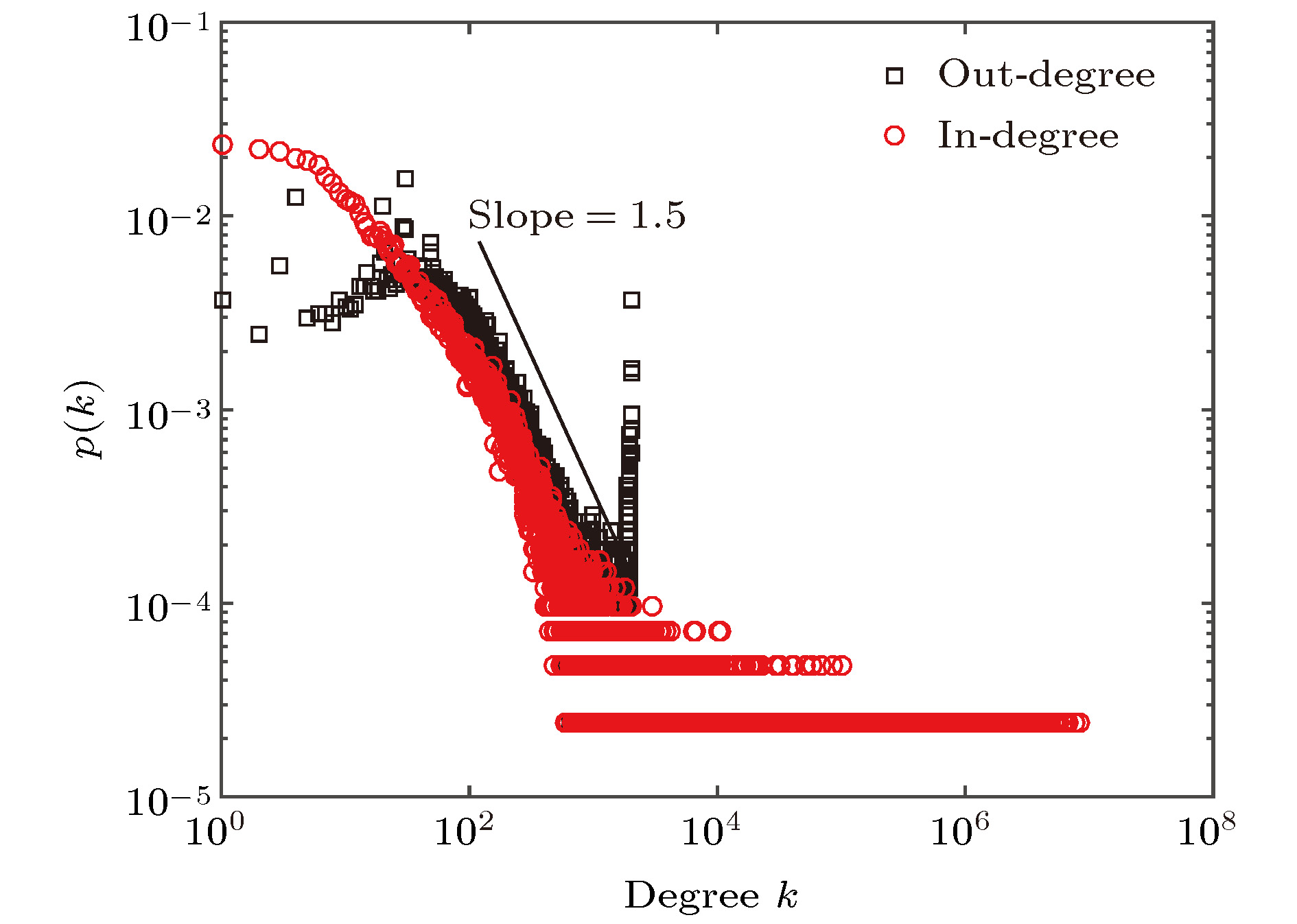
Web 2.0时代, 建模和预测在线信息流行度是信息传播中的重要问题. 本文基于社交网络系统信息传播的机制, 通过假设和简化, 提出了分支过程的概率模型, 来描述在线社交网络信息的流行度动力学过程. 对典型在线社交网络系统的信息流行度数据和网络结构数据进行了分析, 统计结果表明信息流行度衰减遵循幂律分布(幂指数为1.8), 微博网络的入度和出度分布也均服从幂律分布(幂指数为1.5). 模型仿真结果发现, 该模型能够再现真实社交网络数据的若干特征, 且信息流行度与网络结构相关. 对模型方程进行求解得到理论预测的结果与仿真分析和实际数据结果相符合.In the age of Web 2.0, modeling and predicting the popularity of online information was an important issue in information dissemination. Online social medium greatly affects the way we communicate with each other. However, little is known about what fundamental mechanisms drive the dynamical information flow in online social systems. To address this problem, we develop a theoretical probabilistic model based on branching process to characterize the process in which micro-blog information gains its popularity. Firstly, the data of information popularity and network structure of micro-blog network are analyzed. The statistical results show that the attenuation of information popularity follows a scaling law whose exponent is 1.8, and in-degree and out-degree of micro-blog network each also obey a power law distribution whose exponent is 1.5. The results of power law distribution show that there is a high-degree heterogeneity in a micro-blog system. The proportion of micro-blog information with popularity less than 100 is 95.8%, while the amount of micro-blog information with popularity more than 10, 000 is very small. The number of fans (in-degree) less than 100 accounts for 56.4%, while some users have millions of fans.Secondly, according to the design mechanism of the Weibo system, we assume that each user has two lists, i.e. a "home page list" and a "personal page list". Meanwhile, each user has two states at each moment: generating a new message with probability
${\mu} $ to be sent out; 2) or forwarding the information already on the "personal page list" with probability$ (1-{\mu}) $ . Based on the assumptions, the information popularity model is proposed. Finally, the model is simulated. The simulation results show that the model can reproduce some features of real social network data, and the popularity of information is related to the network structure. By solving the model equation, the results of theoretical prediction are consistent with the simulation analyses and actual data.-
Keywords:
- statistical physics /
- branching process /
- complex network /
- information popularity
[1] Wang D, Song C, Barabási A L 2013 Science 342 6154
[2] Sasahara K, Hirata Y, Toyoda M, Kitsuregawa M, Aihara K 2013 PloS one 8 e61823
 Google Scholar
Google Scholar
[3] Quattrociocchi W, Caldarelli G, Scala A 2014 Sci. Rep. 4 4938
[4] Kim Y, Park S, Yook S H 2016 Sci. Rep. 6 23484
Google Scholar
[5] Song B, Jiang G P, Song Y R, Xia L L 2015 Chin. Phys. B 24 100101
Google Scholar
[6] Wang J R, Wang J P, He Zhen, Xu H T 2015 Chin. Phys. B 24 060101
Google Scholar
[7] 闵磊, 刘智, 唐向阳, 陈矛 2015 物理学报 64 088901
Google Scholar
Min L, Liu Z, Tang X Y, Chen M, Liu S Y 2015 Acta Phys. Sin. 64 088901
Google Scholar
[8] 王金龙, 刘方爱, 朱振方 2015 物理学报 64 050501
Google Scholar
Wang J L, Liu F A, Zhu Z F 2015 Acta Phys. Sin. 64 050501
Google Scholar
[9] 李勇军, 尹超, 于会, 刘尊 2016 物理学报 65 020501
Google Scholar
Li Y J, Yin C, Yu H, Liu Z 2016 Acta Phys. Sin. 65 020501
Google Scholar
[10] Gleeson J P, O’sullivan K P, Banos R A, Moreno Y 2016 Phys. Rev. X 6 021019
[11] Zapperi S, Lauritsen K B, Stanley H E 1995 Phys. Rev. Lett. 75 4071
Google Scholar
[12] Iribarren J L, Moro E 2011 Phy. Rev. E 84 046116
Google Scholar
[13] Xu Y, Guo L P, Ding N, Wang Y G 2010 Chin. Phys. Lett. 27 078901
Google Scholar
[14] Zhu J F, Han X P, Wang B H 2010 Chin. Phys. Lett. 27 068902
Google Scholar
[15] Li J J, Wu L R, Qi J Y, Sun Q M 2017 Chin. Phys. Lett. 34 068901
Google Scholar
[16] 杨李 宋玉蓉 李因伟 2018 物理学报 67 190502
Google Scholar
Yang L, Song Y R, Li Y W 2018 Acta Phys. Sin. 67 190502
Google Scholar
[17] Cetin U, Bingol H O 2014 Phys. Rev. E 90 032801
Google Scholar
[18] Weng L, Flammini A, Vespignani A, Menczer F 2012 Sci. Rep. 2 335
Google Scholar
[19] Gleeson J P, Ward J A, O’sullivan K P, Lee W T 2014 Phys. Rev. Lett. 112 048701
Google Scholar
[20] Yan Q, Yi L L, Wu L R 2012 Physica A 391 1540
Google Scholar
[21] Yan Q, Wu L R, Zheng L 2013 Physica A 392 1712
Google Scholar
[22] Miotto J M, Altmann E G 2014 PloS one 91 e111506
[23] Sinatra R, Wang D S, Deville P, Song C Y, Barabási A L 2016 Science 354 6312
-
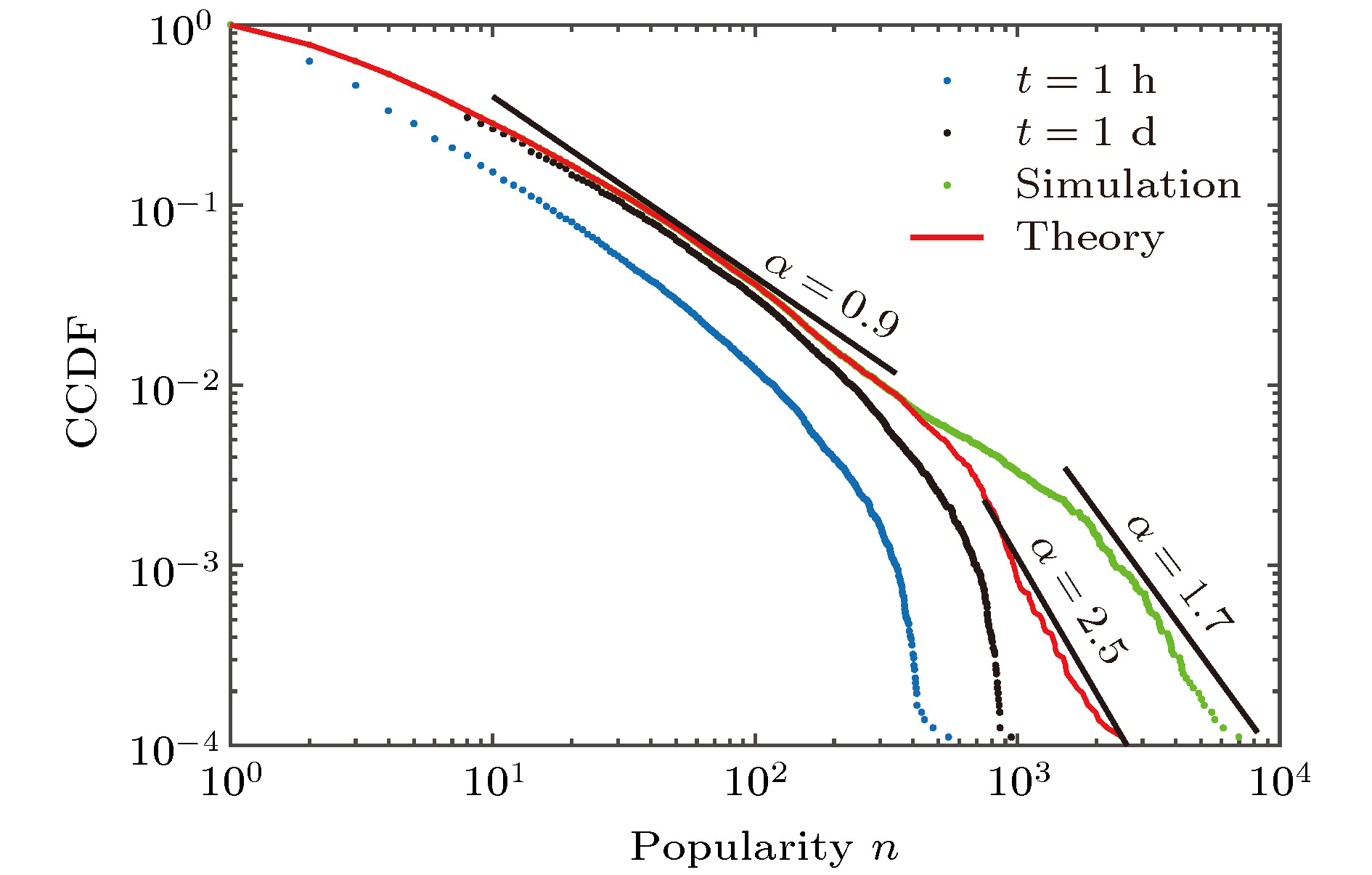
图 5 微博信息流行度的互补累积概率分布(CCDF)
Fig. 5. Complementary cumulative distribution functions (CCDFs)—the fraction of micro-blogs with popularity
$ \geqslant n$ .表 1 一个时间步节点(用户)“微博首页”的结果
Table 1. Single time-step outcomes of user’s list.
列表S 概率 ${G_{jk}}\left( {t,\varOmega ;x} \right)$ (a)被新收到的信息所占据 $k\Delta t$ 1 (b)创造了一条新的信息 ${\mu} \Delta t$ 1 (c)以概率$1 - {\mu} $转发信息 $(1 - {\mu} )\Delta t$ $x{G_{jk}}\left( {t - \Delta t,\varOmega ;x} \right){\left[ {G\left( {t - \Delta t,\varOmega ;x} \right)} \right]^k}$ (d)保持原样 $1 - \left( {k + 1} \right)\Delta t$ ${G_{jk}}\left( {t - \Delta t,\varOmega ;x} \right)$  下载: 导出CSV
下载: 导出CSV
-
[1] Wang D, Song C, Barabási A L 2013 Science 342 6154
[2] Sasahara K, Hirata Y, Toyoda M, Kitsuregawa M, Aihara K 2013 PloS one 8 e61823
Google Scholar
[3] Quattrociocchi W, Caldarelli G, Scala A 2014 Sci. Rep. 4 4938
[4] Kim Y, Park S, Yook S H 2016 Sci. Rep. 6 23484
Google Scholar
[5] Song B, Jiang G P, Song Y R, Xia L L 2015 Chin. Phys. B 24 100101
Google Scholar
[6] Wang J R, Wang J P, He Zhen, Xu H T 2015 Chin. Phys. B 24 060101
Google Scholar
[7] 闵磊, 刘智, 唐向阳, 陈矛 2015 物理学报 64 088901
Google Scholar
Min L, Liu Z, Tang X Y, Chen M, Liu S Y 2015 Acta Phys. Sin. 64 088901
Google Scholar
[8] 王金龙, 刘方爱, 朱振方 2015 物理学报 64 050501
Google Scholar
Wang J L, Liu F A, Zhu Z F 2015 Acta Phys. Sin. 64 050501
Google Scholar
[9] 李勇军, 尹超, 于会, 刘尊 2016 物理学报 65 020501
Google Scholar
Li Y J, Yin C, Yu H, Liu Z 2016 Acta Phys. Sin. 65 020501
Google Scholar
[10] Gleeson J P, O’sullivan K P, Banos R A, Moreno Y 2016 Phys. Rev. X 6 021019
[11] Zapperi S, Lauritsen K B, Stanley H E 1995 Phys. Rev. Lett. 75 4071
Google Scholar
[12] Iribarren J L, Moro E 2011 Phy. Rev. E 84 046116
Google Scholar
[13] Xu Y, Guo L P, Ding N, Wang Y G 2010 Chin. Phys. Lett. 27 078901
Google Scholar
[14] Zhu J F, Han X P, Wang B H 2010 Chin. Phys. Lett. 27 068902
Google Scholar
[15] Li J J, Wu L R, Qi J Y, Sun Q M 2017 Chin. Phys. Lett. 34 068901
Google Scholar
[16] 杨李 宋玉蓉 李因伟 2018 物理学报 67 190502
Google Scholar
Yang L, Song Y R, Li Y W 2018 Acta Phys. Sin. 67 190502
Google Scholar
[17] Cetin U, Bingol H O 2014 Phys. Rev. E 90 032801
Google Scholar
[18] Weng L, Flammini A, Vespignani A, Menczer F 2012 Sci. Rep. 2 335
Google Scholar
[19] Gleeson J P, Ward J A, O’sullivan K P, Lee W T 2014 Phys. Rev. Lett. 112 048701
Google Scholar
[20] Yan Q, Yi L L, Wu L R 2012 Physica A 391 1540
Google Scholar
[21] Yan Q, Wu L R, Zheng L 2013 Physica A 392 1712
Google Scholar
[22] Miotto J M, Altmann E G 2014 PloS one 91 e111506
[23] Sinatra R, Wang D S, Deville P, Song C Y, Barabási A L 2016 Science 354 6312




 下载:
下载:



计量
- 文章访问数: 13601
- PDF下载量: 81
- 被引次数: 0
