










-
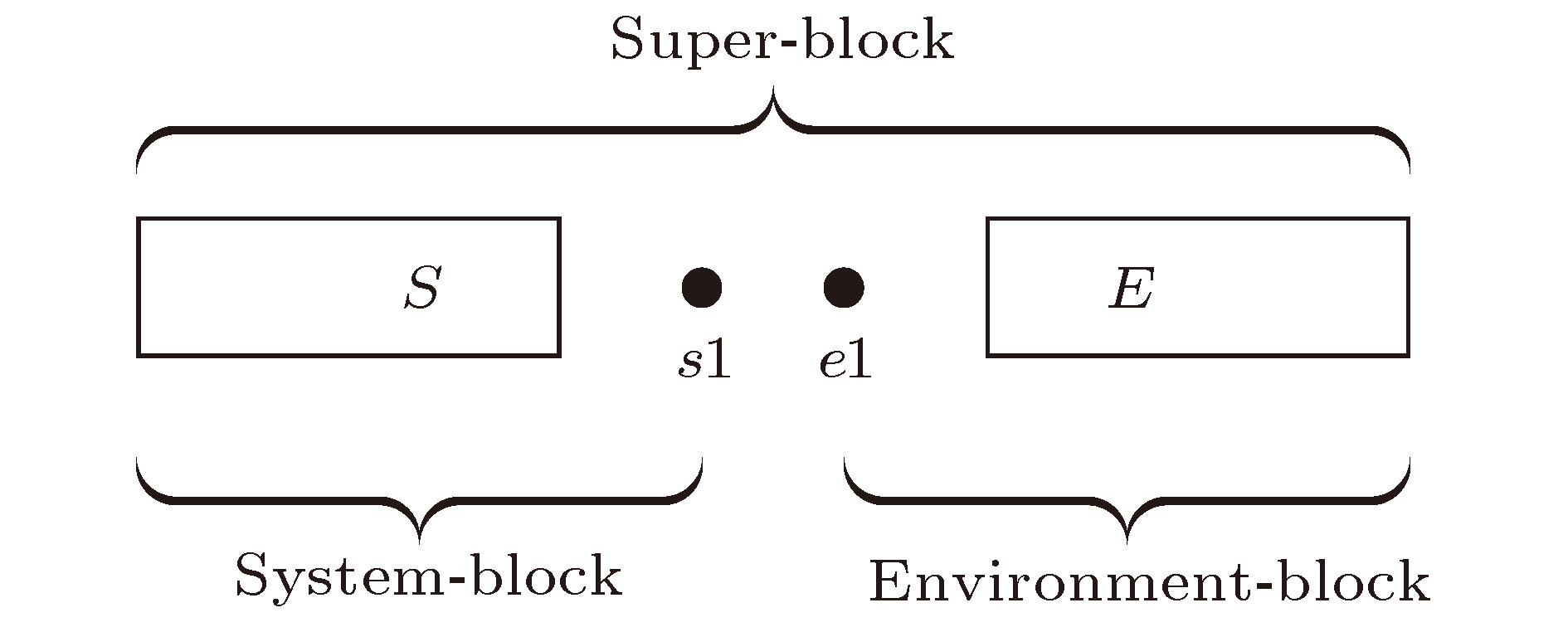
密度矩阵重正化群方法(DMRG)在求解一维强关联格点模型的基态时可以获得较高的精度, 在应用于二维或准二维问题时, 要达到类似的精度通常需要较大的计算量与存储空间. 本文提出一种新的 DMRG异构并行策略, 可以同时发挥计算机中央处理器(CPU)和图形处理器(GPU)的计算性能. 针对最耗时的哈密顿量对角化部分, 实现了数据的分布式存储, 并且给出了CPU和GPU之间的负载平衡策略. 以费米Hubbard模型为例, 测试了异构并行程序在不同DMRG保留状态数下的运行表现, 并给出了相应的性能基准. 应用于4腿梯子时, 观测到了高温超导中常见的电荷密度条纹, 此时保留状态数达到104, 使用的GPU显存小于12 GB.Density matrix renormalization group (DMRG), as a numerical method of solving the ground state of one-dimensional strongly-correlated lattice model with very high accuracy, requires expensive computational and memory cost when applied to two- and quasi-two-dimensional problems. The number of DMRG kept states is generally very large to achieve a reliable accuracy for these applications, which results in numerous matrix and vector operations and unbearably consuming time in the absence of the proper parallelization. However, due to its sequential nature, the parallelization of DMRG algorithm is usually not straightforward. In this work, we propose a new hybrid parallelization strategy for the DMRG method. It takes advantage of the computing capability of both central processing unit (CPU) and graphics processing unit (GPU) of the computer. In order to achieve as many as DMRG kept states within a limited GPU memory, we adopt the four-block formulation of the Hamiltonian rather than the two-block formulation. The later consumes much more memories, which has been used in another pioneer work on the hybrid parallelization of the DMRG algorithm, and only a small number of DMRG kept states are available. Our parallel strategy focuses on the diagonalization of the Hamiltonian, which is the most time-consuming part of the whole DMRG procedure. A hybrid parallelization strategy of diagonalization method is implemented, in which the required data for diagonalization are distributed on both the host and GPU memory, and the data exchange between them is negligible in our data partitioning scheme. The matrix operations are also shared on both CPU and GPU when the Hamiltonian acts on a wave function, while the distribution of these operations is determined by a load balancing strategy. Taking fermionic Hubbard model for example, we examine the running performance of the hybrid parallelization strategy with different DMRG kept states and provide corresponding performance benchmark. On a 4-leg ladder, we employ the conserved quantities with U(1) symmetry of the model and a good-quantum number based task scheduling to further reduce the GPU memory cost. We manage to obtain a moderate speedup of the hybrid parallelization for a wide range of DMRG kept states. In our example, the ground state energy with high accuracy is obtained by the extrapolation of the results, with different numbers of states kept, and we show charge stripes which are usually experimentally observed in high-temperature superconductors. In this case, we keep 104 DMRG states and the GPU memory cost is less than 12 Gigabytes.
-
Keywords:
- density matrix renormalization group /
- strongly correlated lattice model /
- hybrid parallelization
[1] White S R 1992 Phys. Rev. Lett. 69 2863
 Google Scholar
Google Scholar
[2] White S R 1993 Phys. Rev. B 48 10345
Google Scholar
[3] Schollwöck U 2005 Rev. Mod. Phys. 77 259
Google Scholar
[4] Schollwöck U 2011 Annals of Physics 326 96
Google Scholar
[5] Xiang T 1996 Phys. Rev. B 53 R10445
[6] White S R, Martin R L 1999 J. Chem. Phys. 110 4127
Google Scholar
[7] Luo H G, Qin M P, Xiang T 2010 Phys. Rev. B 81 235129
Google Scholar
[8] Yang J, Hu W, Usvyat D, Matthews D, Schütz M, Chan G K L 2014 Science 345 640
Google Scholar
[9] Cazalilla M A, Marston J B 2002 Phys. Rev. Lett. 88 256403
Google Scholar
[10] Luo H G, Xiang T, Wang X Q 2003 Phys. Rev. Lett. 91 049701
Google Scholar
[11] White S R, Feiguin A E 2004 Phys. Rev. Lett. 93 076401
Google Scholar
[12] Cheng C, Mondaini R, Rigol M 2018 Phys. Rev. B 98 121112
Google Scholar
[13] Zheng B X, Chung C M, Corboz P, Ehlers G, Qin M P, Noack R M, Shi H, White S R, Zhang S, Chan G K L 2017 Science 358 1155
Google Scholar
[14] Huang E W, Mendl C B, Liu S, Johnston S, Jiang H C, Moritz B, Devereaux T P 2017 Science 358 1161
Google Scholar
[15] Dagotto E 1994 Rev. Mod. Phys. 66 763
Google Scholar
[16] Keimer B, Kivelson S A, Norman M R, Uchida S, Zaanen J 2015 Nature 518 179
Google Scholar
[17] Fradkin E, Kivelson S A, Tranquada J M 2015 Rev. Mod. Phys. 87 457
Google Scholar
[18] Yan S, Huse D A, White S R 2011 Science 332 1173
Google Scholar
[19] Savary L, Balents L 2017 Rep. Prog. Phys. 80 016502
[20] Alvarez G 2012 Comput. Phys. Commun. 183 2226
[21] Tzeng Y C 2012 Phys. Rev. B 86 024403
Google Scholar
[22] Legeza O, Röder J, Hess B A 2003 Phys. Rev. B 67 125114
Google Scholar
[23] Legeza O, Sólyom J 2003 Phys. Rev. B 68 195116
Google Scholar
[24] White S R 1996 Phys. Rev. Lett. 77 3633
Google Scholar
[25] Hubig C, McCulloch I P, Schollwöck U, Wolf F A 2015 Phys. Rev. B 91 155115
Google Scholar
[26] White S R 2005 Phys. Rev. B 72 180403
Google Scholar
[27] Stoudenmire E M, White S R 2013 Phys. Rev. B 87 155137
Google Scholar
[28] Hager G, Jeckelmann E, Fehske H, Wellein G 2004 J. Comput. Phys. 194 795
Google Scholar
[29] Chan G K L 2004 J. Chem. Phys. 120 3172
Google Scholar
[30] Nemes C, Barcza G, Nagy Z, Örs Legeza, Szolgay P 2014 Comput. Phys. Commun. 185 1570
Google Scholar
[31] Siro T, Harju A 2012 Comput. Phys. Commun. 183 1884
Google Scholar
[32] Lutsyshyn Y 2015 Comput. Phys. Commun. 187 162
Google Scholar
[33] Yu J, Hsiao H C, Kao Y J 2011 Comput. Fluids 45 55
Google Scholar
[34] Ehlers G, White S R, Noack R M 2017 Phys. Rev. B 95 125125
Google Scholar
[35] Davidson E R 1975 J. Comput. Phys. 17 87
Google Scholar
[36] Sadkane M, Sidje R B 1999 Numer. Algorithms 20 217
Google Scholar
[37] Tranquada J M, Sternlieb B J, Axe J D, Nakamura Y, Uchida S 1995 Nature 375 561
Google Scholar
[38] Comin R, Damascelli A 2016 Annu. Rev. Condens. Matter Phys. 7 369
Google Scholar
-
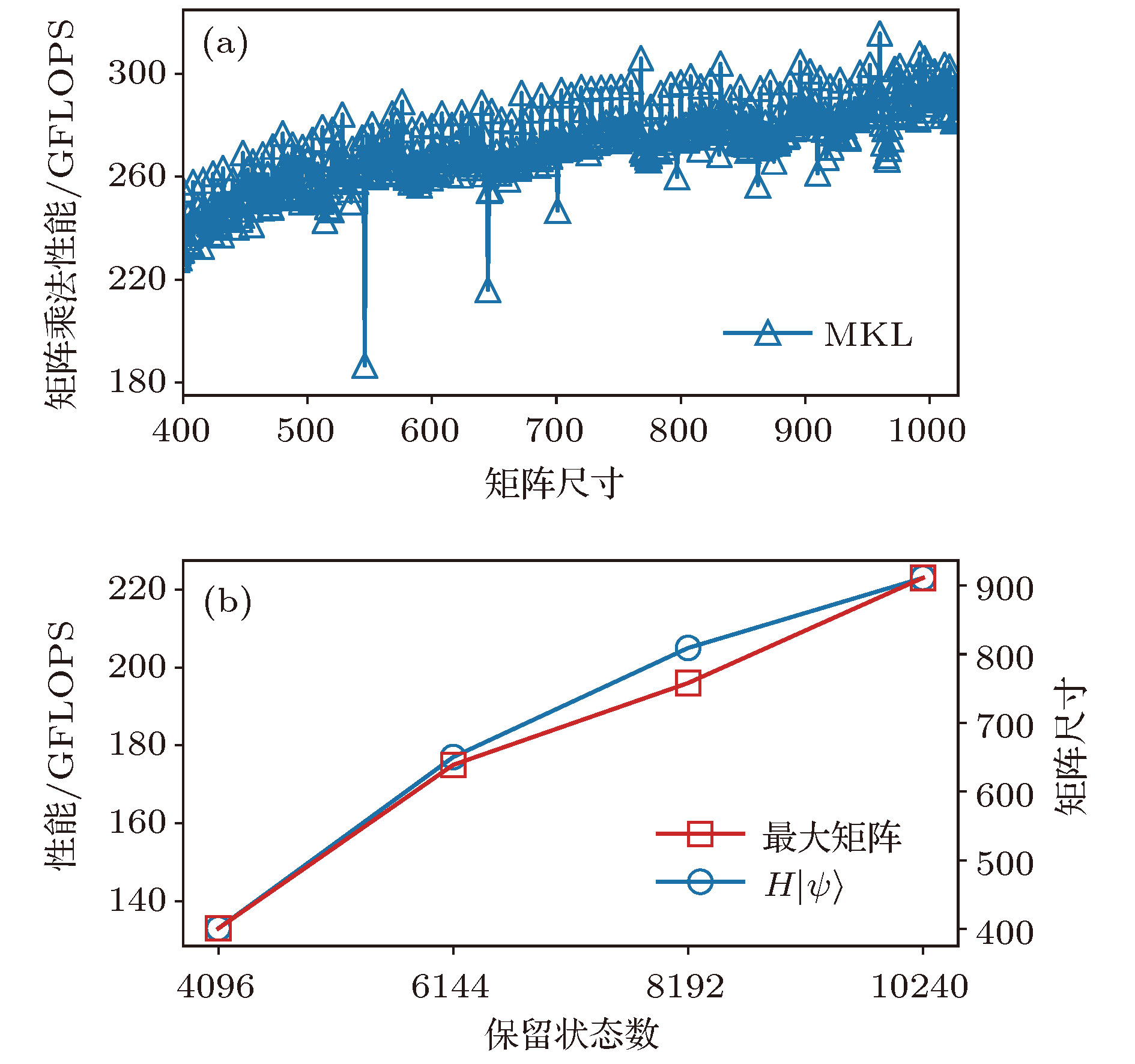
图 2 CPU中作用哈密顿量在波函数上的性能 (a)矩阵乘法的浮点性能; (b)作用哈密顿量于波函数的性能, 及矩阵乘法中的最大矩阵尺寸
Fig. 2. Performance of acting the Hamiltonian on the wave function in CPU: (a) The matrix multiplication performance; (b) the performance of acting the Hamiltonian on the wave function, and the maximum matrix size of the matrix multiplications.
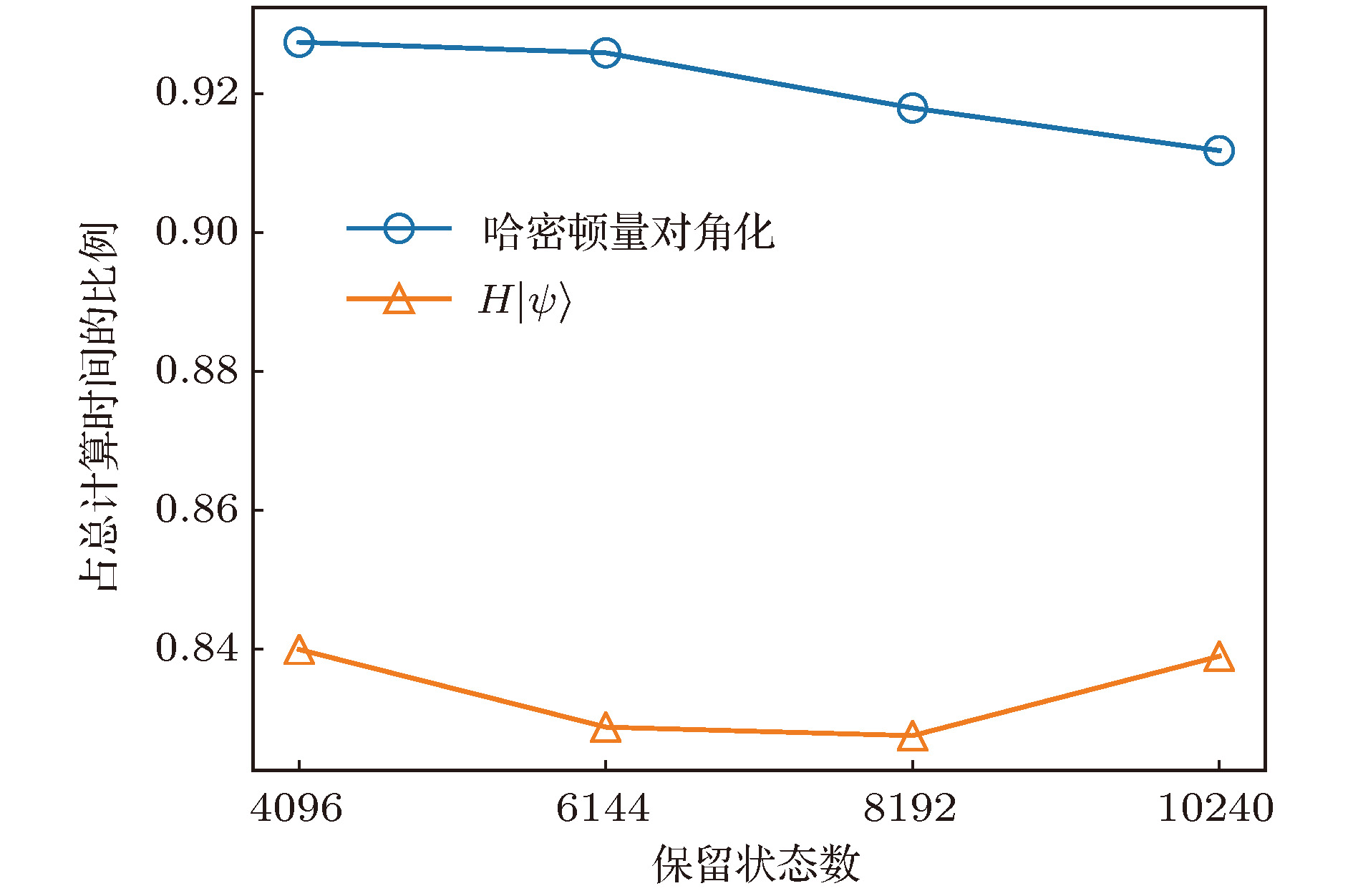
图 3 对角化哈密顿量和作用哈密顿量到波函数操作占总计算时间的比例
Fig. 3. Time ratio of diagonalization of the Hamiltonian and acting the Hamiltonian on the wave function to the total time cost.
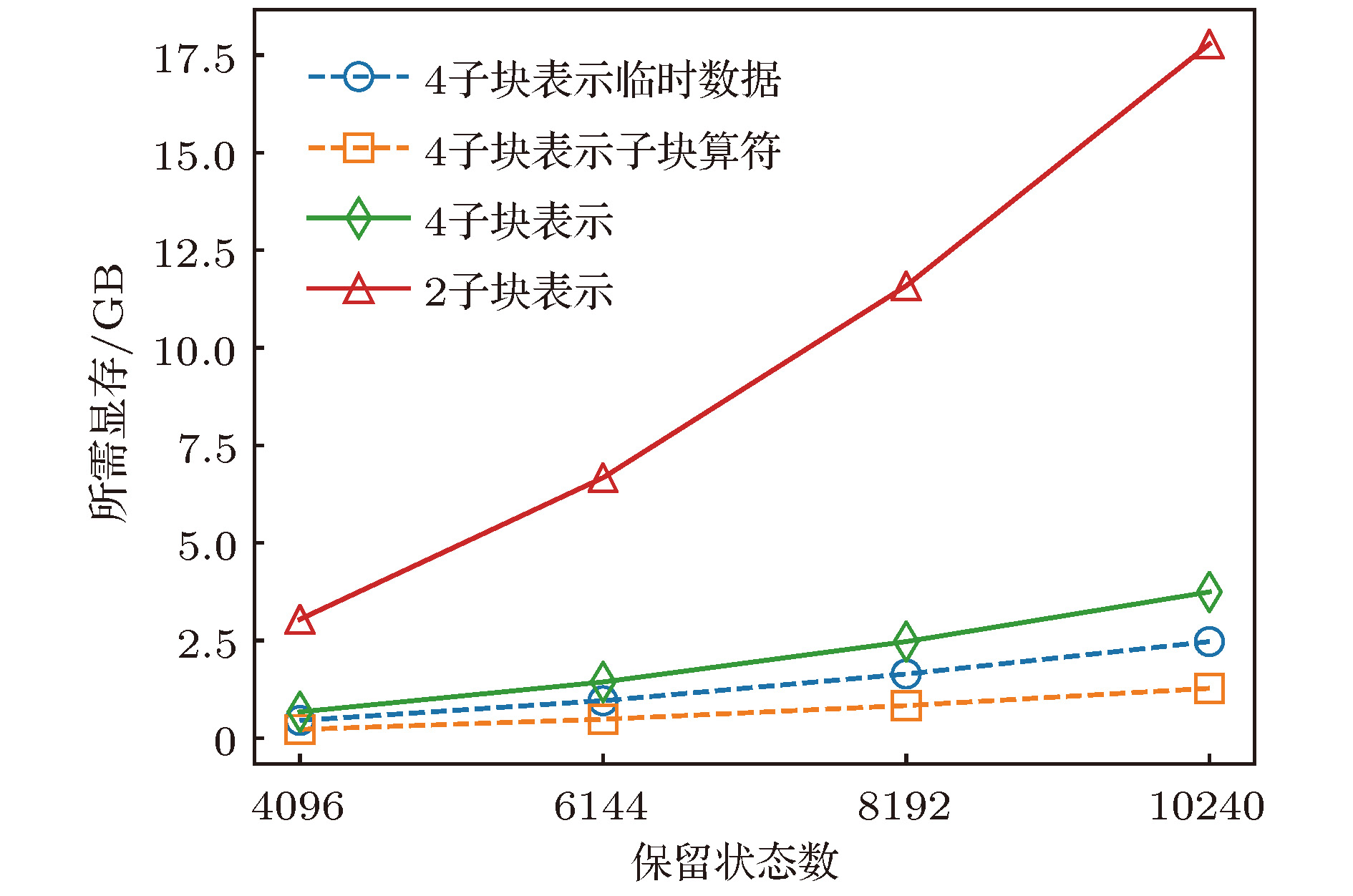
图 4 存储临时数据, 子块算符需要的GPU显存
Fig. 4. The GPU memory cost of temporary data and sub-block operators.
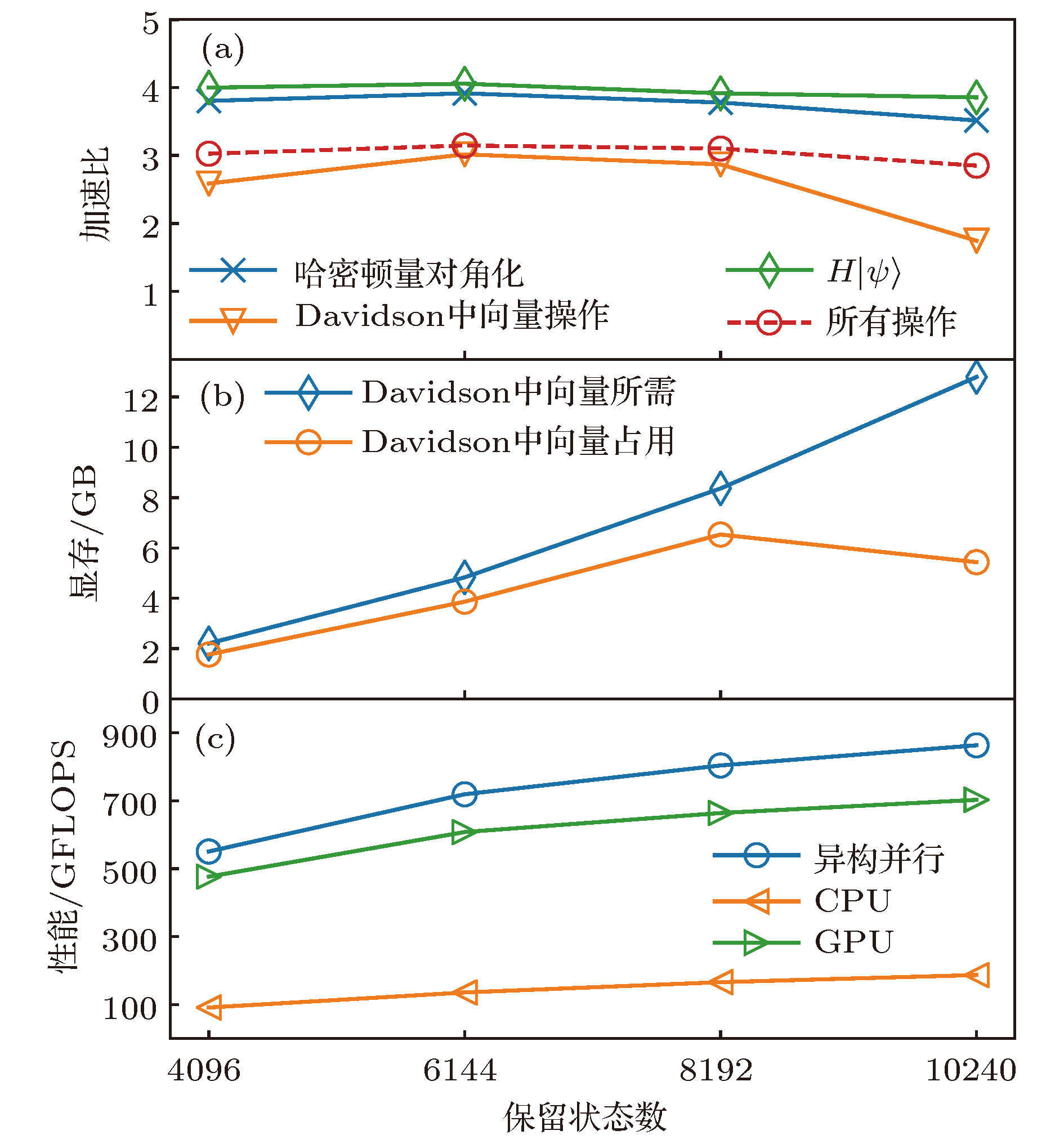
图 5 异构并行的性能 (a)加速比; (b) Davidson方法中的向量占用GPU显存; (c)作用哈密顿量到波函数部分的性能
Fig. 5. Performance of hybrid parallel strategy: (a) The speedup; (b) the GPU memory cost of vectors in Davidson; (c) the performance of
$H\left|{\psi}\right\rangle$ 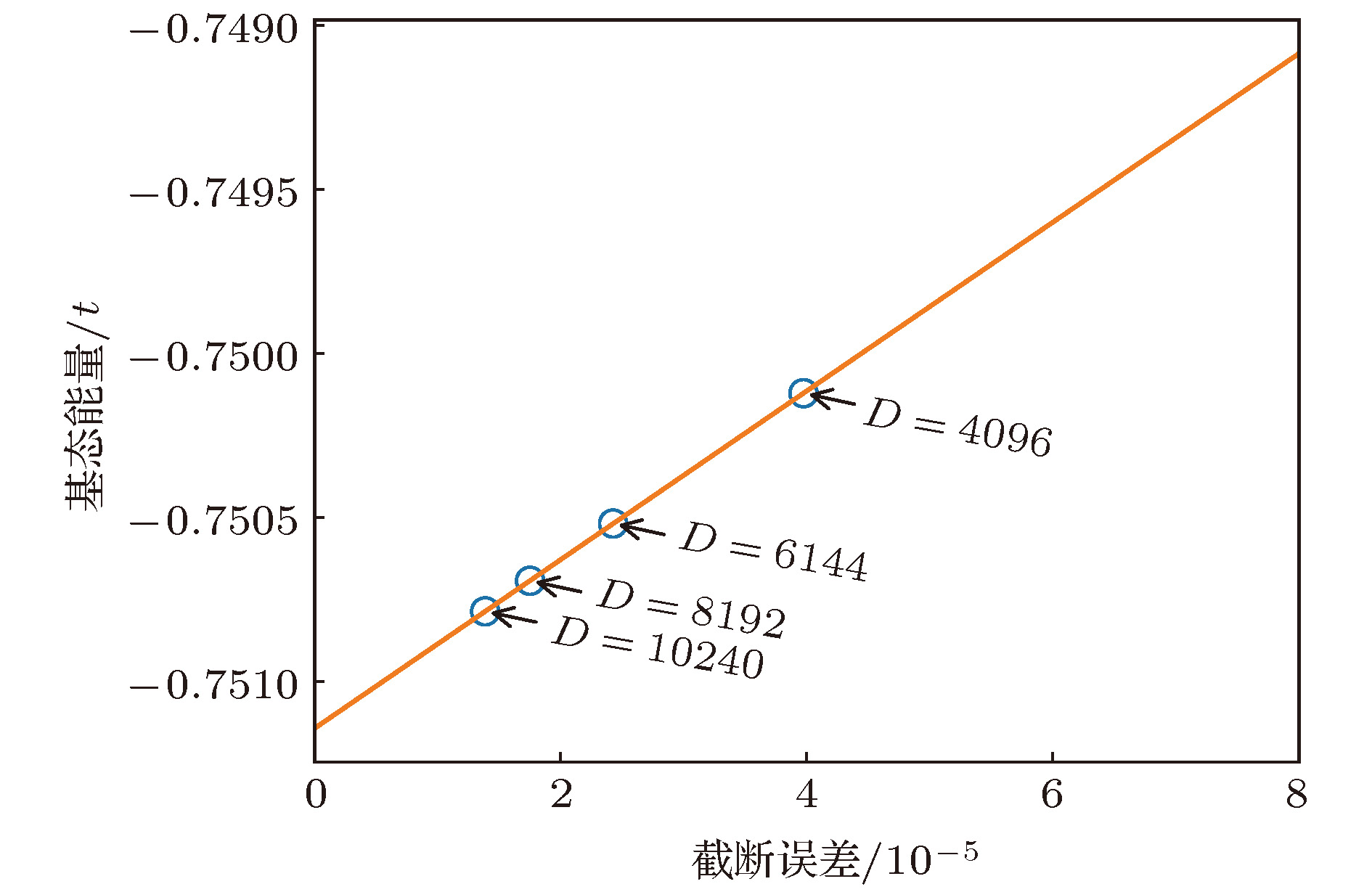
图 6 基态能量关于截断误差的函数(直线表示对基态能量的线性外推, 直至截断误差为0)
Fig. 6. Groundstate energy as a function of truncation error. The straight line gives a linear extrapolation of the ground energy until 0 truncation-error.
-
[1] White S R 1992 Phys. Rev. Lett. 69 2863
Google Scholar
[2] White S R 1993 Phys. Rev. B 48 10345
Google Scholar
[3] Schollwöck U 2005 Rev. Mod. Phys. 77 259
Google Scholar
[4] Schollwöck U 2011 Annals of Physics 326 96
Google Scholar
[5] Xiang T 1996 Phys. Rev. B 53 R10445
[6] White S R, Martin R L 1999 J. Chem. Phys. 110 4127
Google Scholar
[7] Luo H G, Qin M P, Xiang T 2010 Phys. Rev. B 81 235129
Google Scholar
[8] Yang J, Hu W, Usvyat D, Matthews D, Schütz M, Chan G K L 2014 Science 345 640
Google Scholar
[9] Cazalilla M A, Marston J B 2002 Phys. Rev. Lett. 88 256403
Google Scholar
[10] Luo H G, Xiang T, Wang X Q 2003 Phys. Rev. Lett. 91 049701
Google Scholar
[11] White S R, Feiguin A E 2004 Phys. Rev. Lett. 93 076401
Google Scholar
[12] Cheng C, Mondaini R, Rigol M 2018 Phys. Rev. B 98 121112
Google Scholar
[13] Zheng B X, Chung C M, Corboz P, Ehlers G, Qin M P, Noack R M, Shi H, White S R, Zhang S, Chan G K L 2017 Science 358 1155
Google Scholar
[14] Huang E W, Mendl C B, Liu S, Johnston S, Jiang H C, Moritz B, Devereaux T P 2017 Science 358 1161
Google Scholar
[15] Dagotto E 1994 Rev. Mod. Phys. 66 763
Google Scholar
[16] Keimer B, Kivelson S A, Norman M R, Uchida S, Zaanen J 2015 Nature 518 179
Google Scholar
[17] Fradkin E, Kivelson S A, Tranquada J M 2015 Rev. Mod. Phys. 87 457
Google Scholar
[18] Yan S, Huse D A, White S R 2011 Science 332 1173
Google Scholar
[19] Savary L, Balents L 2017 Rep. Prog. Phys. 80 016502
[20] Alvarez G 2012 Comput. Phys. Commun. 183 2226
[21] Tzeng Y C 2012 Phys. Rev. B 86 024403
Google Scholar
[22] Legeza O, Röder J, Hess B A 2003 Phys. Rev. B 67 125114
Google Scholar
[23] Legeza O, Sólyom J 2003 Phys. Rev. B 68 195116
Google Scholar
[24] White S R 1996 Phys. Rev. Lett. 77 3633
Google Scholar
[25] Hubig C, McCulloch I P, Schollwöck U, Wolf F A 2015 Phys. Rev. B 91 155115
Google Scholar
[26] White S R 2005 Phys. Rev. B 72 180403
Google Scholar
[27] Stoudenmire E M, White S R 2013 Phys. Rev. B 87 155137
Google Scholar
[28] Hager G, Jeckelmann E, Fehske H, Wellein G 2004 J. Comput. Phys. 194 795
Google Scholar
[29] Chan G K L 2004 J. Chem. Phys. 120 3172
Google Scholar
[30] Nemes C, Barcza G, Nagy Z, Örs Legeza, Szolgay P 2014 Comput. Phys. Commun. 185 1570
Google Scholar
[31] Siro T, Harju A 2012 Comput. Phys. Commun. 183 1884
Google Scholar
[32] Lutsyshyn Y 2015 Comput. Phys. Commun. 187 162
Google Scholar
[33] Yu J, Hsiao H C, Kao Y J 2011 Comput. Fluids 45 55
Google Scholar
[34] Ehlers G, White S R, Noack R M 2017 Phys. Rev. B 95 125125
Google Scholar
[35] Davidson E R 1975 J. Comput. Phys. 17 87
Google Scholar
[36] Sadkane M, Sidje R B 1999 Numer. Algorithms 20 217
Google Scholar
[37] Tranquada J M, Sternlieb B J, Axe J D, Nakamura Y, Uchida S 1995 Nature 375 561
Google Scholar
[38] Comin R, Damascelli A 2016 Annu. Rev. Condens. Matter Phys. 7 369
Google Scholar

 下载:
下载:

计量
- 文章访问数: 19915
- PDF下载量: 134
- 被引次数: 0
