










-
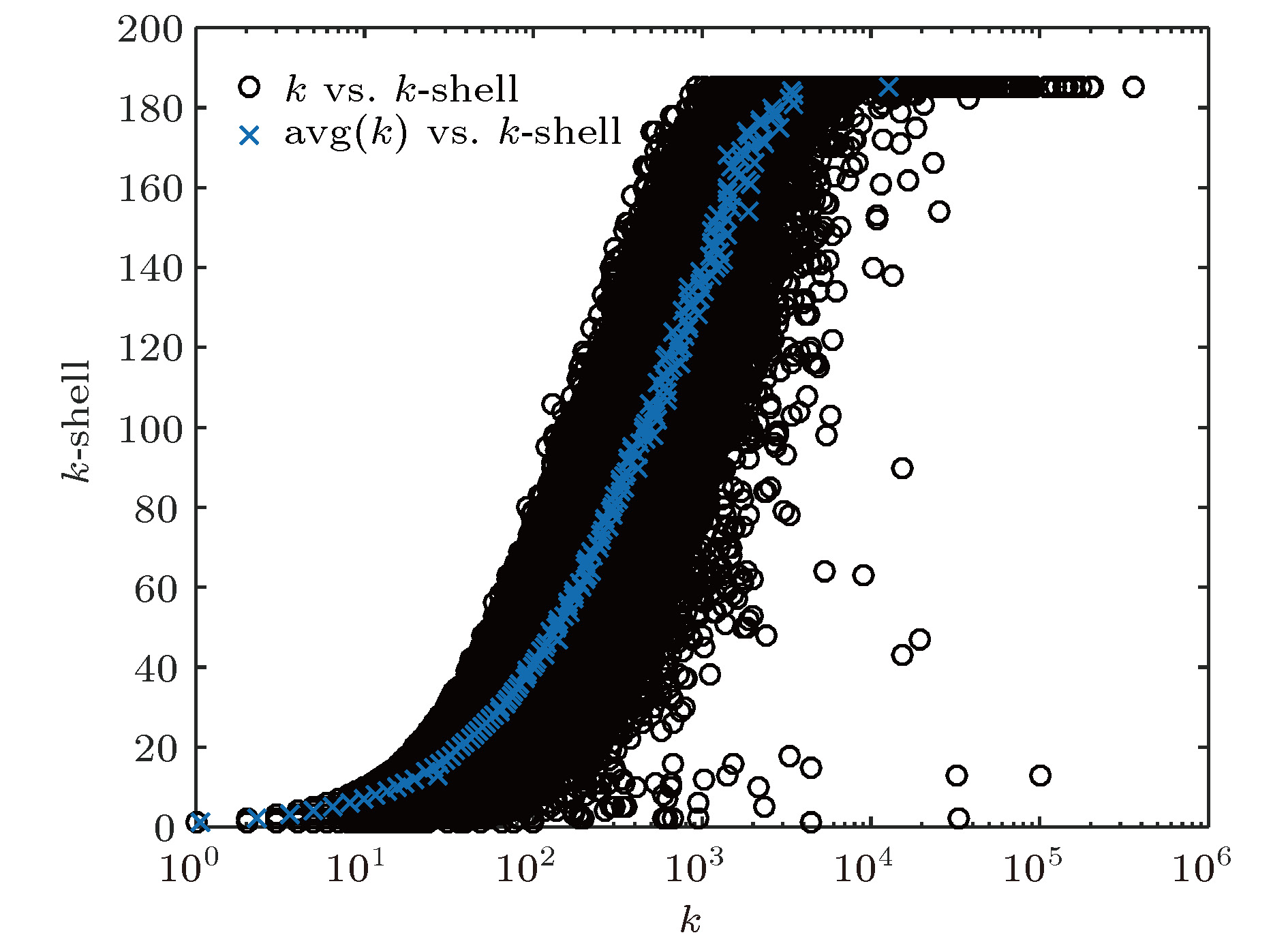
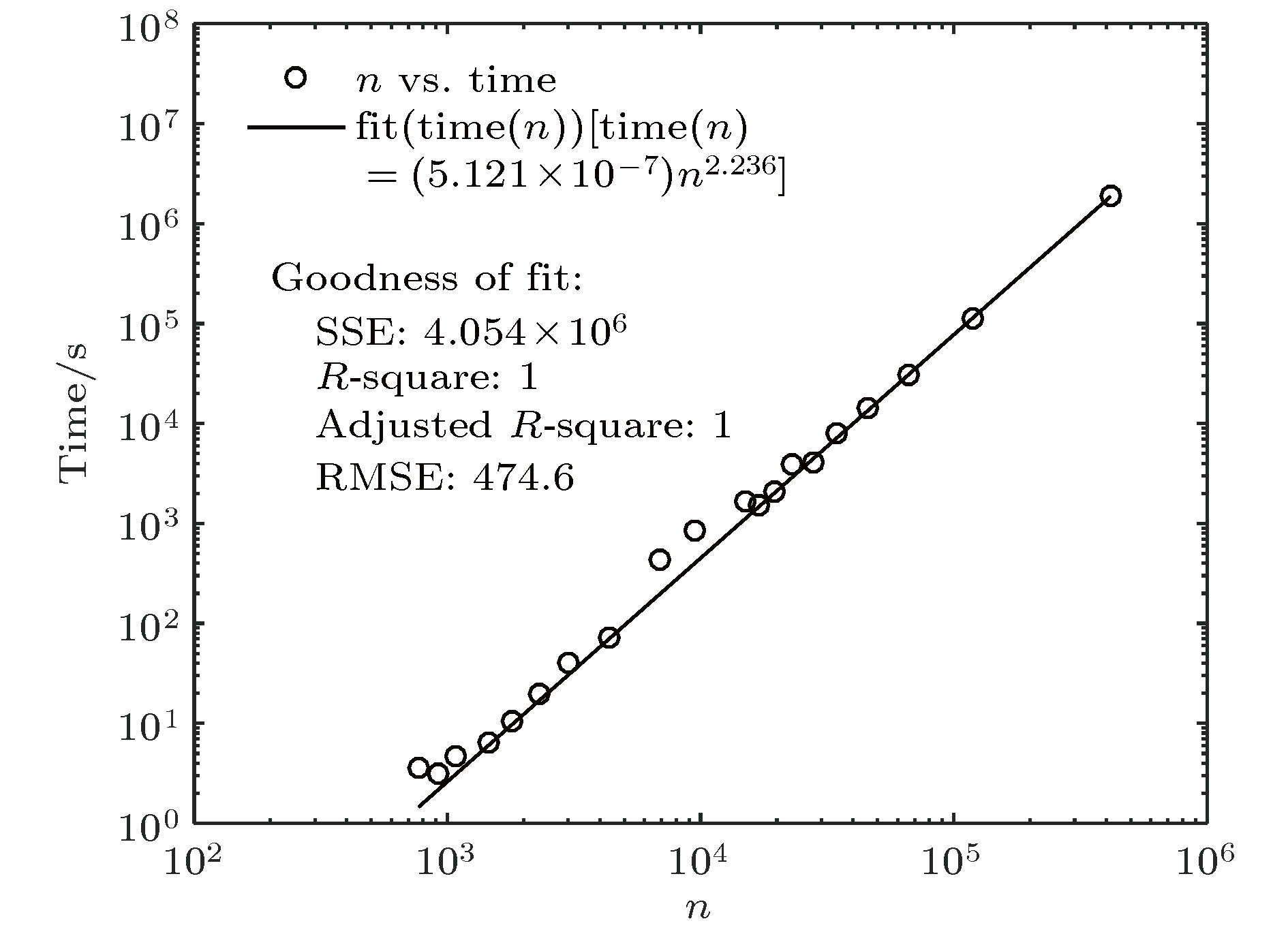
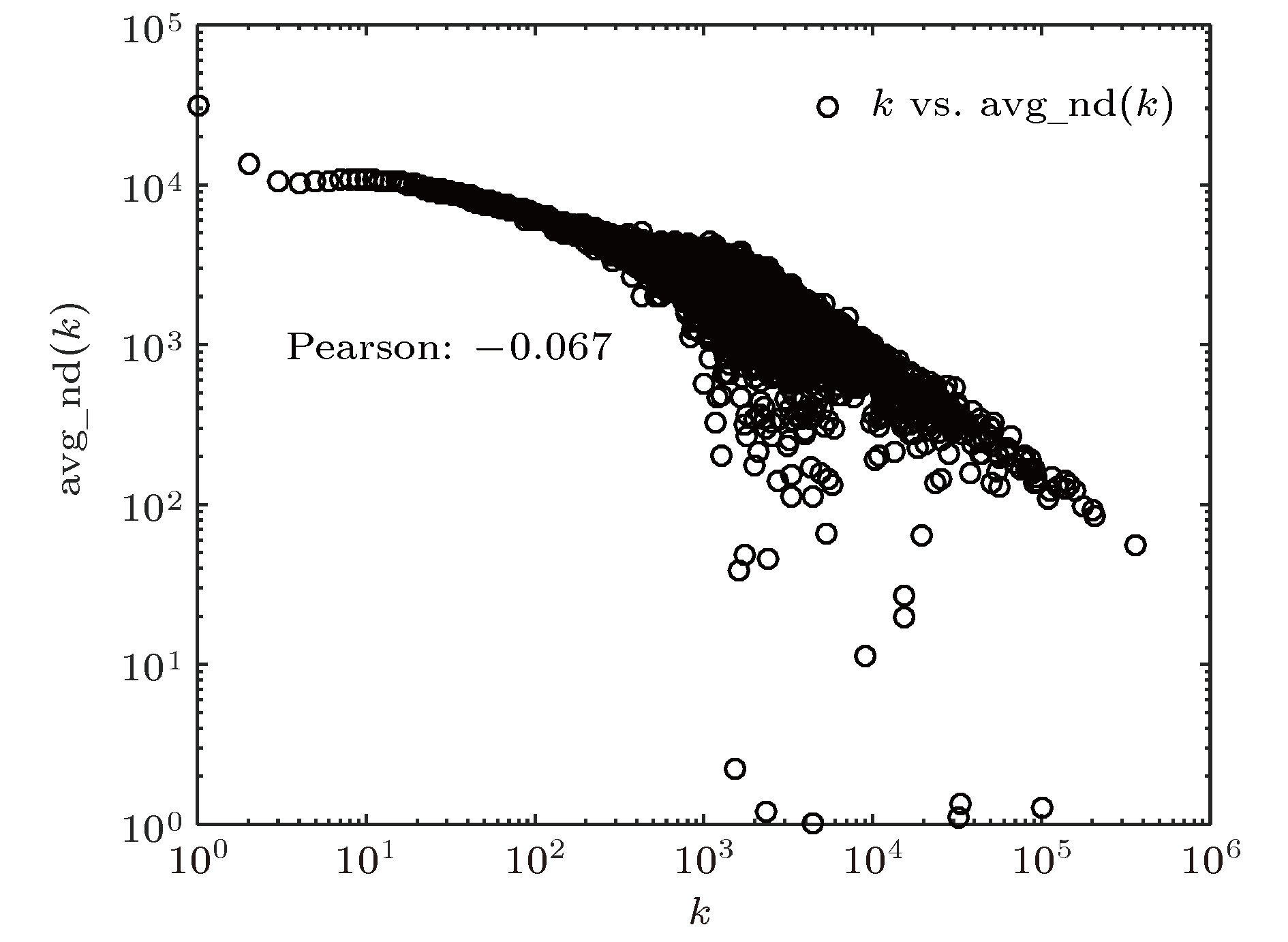
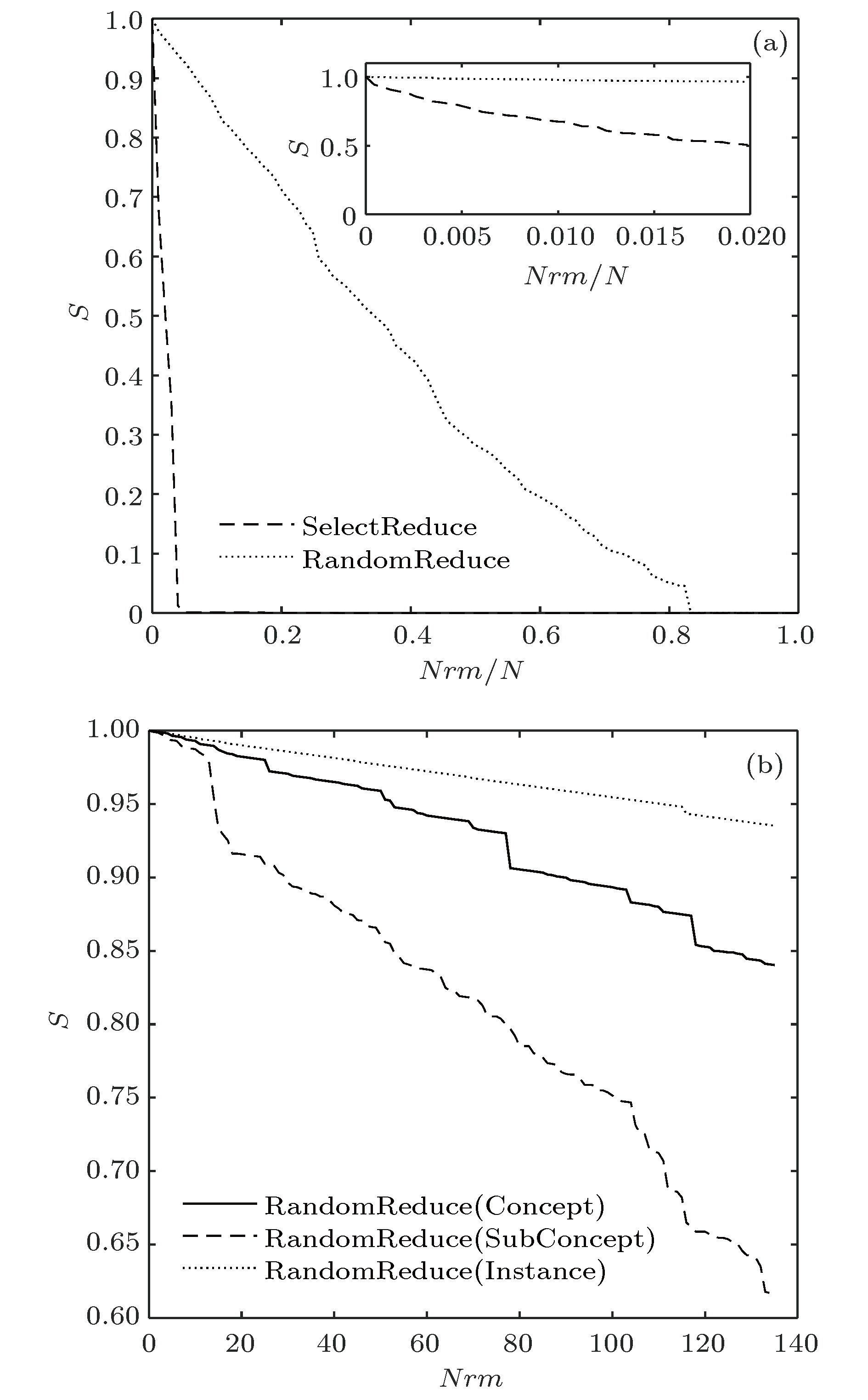
知识图谱是人工智能研究的新热点, 用于解决智能检索、自动回答等应用问题. 概念图谱是微软发布的大型知识图谱, 本文以概念图谱为研究对象构建了概念图谱网络, 并对其特性进行了分析. 为解决概念图谱海量数据带来的计算困难, 提出一种适合概念图谱的最大子网构建方法和一种网络近似平均路径的计算方法; 对不同度值给出了不同的聚类系数求解方法, 并通过Map/Reduce模式进行提速. 结果表明: 概念图谱网络具有无标度和极端小世界网络的特征; 平均路径长度随网络规模增加而减小并趋于4这一定值, 网络的“菱形”结构能很好地解释这一现象; 概念图谱网络是异构的, 相邻节点的度负相关; k-shell分解表明子概念占核心层节点的99.5%, 在概念图谱中起重要的连接作用; 子概念的缺失对概念图谱的完整性影响最大、概念其次、实例最小; 82%的实例节点度为1, 40%的概念节点度为1, 实例比概念更不易因一词多义而引起理解歧义.Knowledge graph is a hot topic in artificial intelligence area and has been widely adopted in intelligent search and question-and-answer system. Knowledge graph can be regarded as a complex network system and analyzed by complex network theory, which studies the interaction or relationship between various factors and basic characteristics of complex system. Its characteristics and their physical meanings are very helpful in understanding the nature of the knowledge graph. Concept graph is a large-scaled knowledge graph published by Microsoft. In this paper, we construct a huge complex network according to Microsoft’s concept graph. Its complex network characteristics, such as degree distribution, average shortest distance, clustering coefficient and degree correlation, are calculated and analyzed. The concept graph is not a connected network and its scale is very large; an approach is proposed to extract its largest connected subnet. The method has obvious advantages in both time complexity and space complexity. In this paper, we also present a method of calculating the approximate average shortest path of the largest connected subnet. The method estimates the maximum and minimum value of the shortest distance between nodes according to the distance between the central node and the network layer that the node belongs to and the distance between different layers. In order to calculate the clustering coefficient, different methods are introduced for nodes with different degree values and Map/Reduce idea is adopted to reduce the time cost. The experimental results show that the largest subnet of the concept graph is an ultra-small world network with the characteristics of scale-free. The average shortest path length decreases towards 4 with the network size increasing, which can be easily explained by the diamond-shaped network structure. The concept graph is a disassortative network where low degree nodes tend to connect to high degree nodes. The subConcepts account for 99.5% of nodes in the innermost k-core after k-shell decomposition. It shows that the subConcepts play an important role in the connectivity of network. The absence of subConcept affects the complexness of concept graph most, the concept next, and the instance least. The 82% instance nodes and 40% concept nodes of the concept graph each have a degree value of 1. It is believed that compared with the concept words, the instance words do not lead to the ambiguity in the understanding of natural language, caused by polysemy.
[1] Wang Z Y, Wang H X, Wen J R, Xiao Y H 2015 ACM International Conference on Information and Knowledge Management Melbourne, Australia, October 18−23, 2015 p653
[2] Hagberg A A, Schult D A, Swart P J 2008Proceedings of the 7th Python in Science Conference Pasadena, CA USA, August 19–24, 2008 p11
[3] Watts D J, Strogatz S H 1998 Nature 393 440
 Google Scholar
Google Scholar
[4] Barabási A L, Albert R 1999 Science 286 509
Google Scholar
[5] 刘志宏, 曾勇, 吴宏亮, 马建峰 2014 计算机研究与发展 51 2788
Google Scholar
Liu Z H, Zeng Y, Wu H L, Ma J F 2014 Journal of Computer Research and Development 51 2788
Google Scholar
[6] An H Z, Zhong W Q, Chen Y R, Li H J, Gao X Y 2014 Energy 74 254
Google Scholar
[7] Almog A, Squartini T, Garlaschelli D 2015 New J. Phys. 17 013009
Google Scholar
[8] 邢雪, 于德新, 田秀娟, 王世广 2017 物理学报 66 230501
Google Scholar
Xing X, Yu D X, Tian X J, Wang S G 2017 Acta Phys. Sin. 66 230501
Google Scholar
[9] Colombo A, Campos G R D, Rossa F D 2017 IEEE Trans. Autom. Control 62 4933
[10] Wan X, Li Q M, Yuan J F, Schonfeld P M 2015 Accid. Anal. Prev. 82 90
Google Scholar
[11] 叶堃晖, 袁欣 2018 资源开发与市场 34 59
Google Scholar
Ye K H, Yuan X 2018 Resources Development & Market 34 59
Google Scholar
[12] Hu Y H, Zhu D L 2009 Physica A 388 2061
Google Scholar
[13] Pien K C, Han K, Shang W L, Majumdar A 2015 Transportmetrica A 11 772
[14] Albert R, Jeong H, Barabási A L 2000 Nature 406 378
Google Scholar
[15] Broder A, Kumar R, Maghoul F, Raghavan P, Rajagopalan S, Stata R, Tomkins A, Wiener J 2000 Comput. Netw. 33 309
Google Scholar
[16] Albert R, Jeong H, Barabási A L 1999 Nature 401 130
Google Scholar
[17] Aiello W, Chung F, Lu L Y 2001 42nd Annual Symposium on Foundations of Computer Science Las Vegas, NV, USA October 14–17, 2001 p510
[18] Aiello W, Chung F, Lu L Y 2000 Proceedings of the Thirty-second Annual ACM Symposium on Theory of Computing Portland, Oregon, USA, May 21–23, 2000 p171
[19] Rattigan M, Maier M, Jensen D 2006 Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining Philadelphia, PA, USA, August 20–23, 2006 p357
[20] Fiedor P 2015 Acta Phys. Pol. A 127 863
Google Scholar
[21] Wang G J, Xie C, Stanley H E 2018 Comput. Econ. 51 607
Google Scholar
[22] 邱路, 贾天明, 杨会杰 2016 物理学报 65 198901
Google Scholar
Qiu L, Jia T M, Yang H J 2016 Acta Phys. Sin. 65 198901
Google Scholar
[23] 孙延风, 王朝勇 2018 物理学报 67 148901
Google Scholar
Sun Y F, Wang C Y 2018 Acta Phys. Sin. 67 148901
Google Scholar
[24] 阮逸润, 老松杨, 王俊德, 白亮, 陈立栋 2017 物理学报 66 038902
Google Scholar
Ruan Y R, Lao S Y, Wang J D, Bai L, Chen L D 2017 Acta Phys. Sin. 66 038902
Google Scholar
[25] Kitsak M, Gallos L K, Havlin S, Liljeros F, Muchnik L, Stanley H E, Makse H A 2010 Nat. Phys. 6 888
Google Scholar
[26] Li Q, Zhou T, Lu L Y, Chen D B 2014 Physica A 404 47
Google Scholar
[27] Ruan Y R, Lao S Y, Xiao Y D, Wang J D, Bai L 2016 Chin. Phys. Lett. 33 028901
Google Scholar
[28] 孔江涛, 黄健, 龚建兴, 李尔玉 2018 物理学报 67 098901
Google Scholar
Kong J T, Huang J, Gong J X, Li E Y 2018 Acta Phys. Sin. 67 098901
Google Scholar
[29] 韩定定, 姚青青, 陈趣, 钱江海 2017 物理学报 66 248901
Google Scholar
Han D D, Yao Q Q, Chen Q, Qian J H 2017 Acta Phys. Sin. 66 248901
Google Scholar
[30] Niu R W, Pan G J 2016 Chin. Phys. Lett. 33 068901
Google Scholar
[31] Jiang J, Zhang R, Guo L, Li W, Cai X 2016 Chin. Phys. Lett. 33 108901
Google Scholar
[32] 唐晋韬, 王挺, 王戟 2011 软件学报 22 2279
Tang J Y, Wang T, Wang W 2011 Journal of Software 22 2279
[33] NetworkX Developers https://networkx.github.io/documenta- tion/networkx1.9/modules/networkx/algorithms/components /connected.html#connected_component_subgraphs [2014-6-21]
[34] Newman M E J 2003 Phys. Rev. E 67 026126
Google Scholar
[35] Holme P, Kim B J, Yoon C N, Yoon C N, Han S K 2002 Phys. Rev. E 65 056109
Google Scholar
-
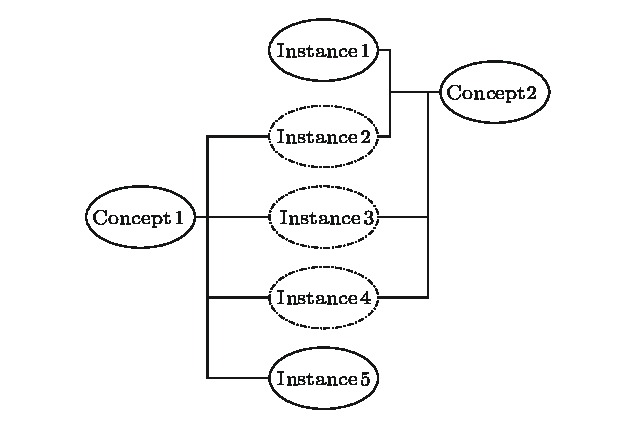
图 2 导致节点的邻居节点集合冗余的网络结构
Fig. 2. Network structure leading to the overlap of neighbor node sets.
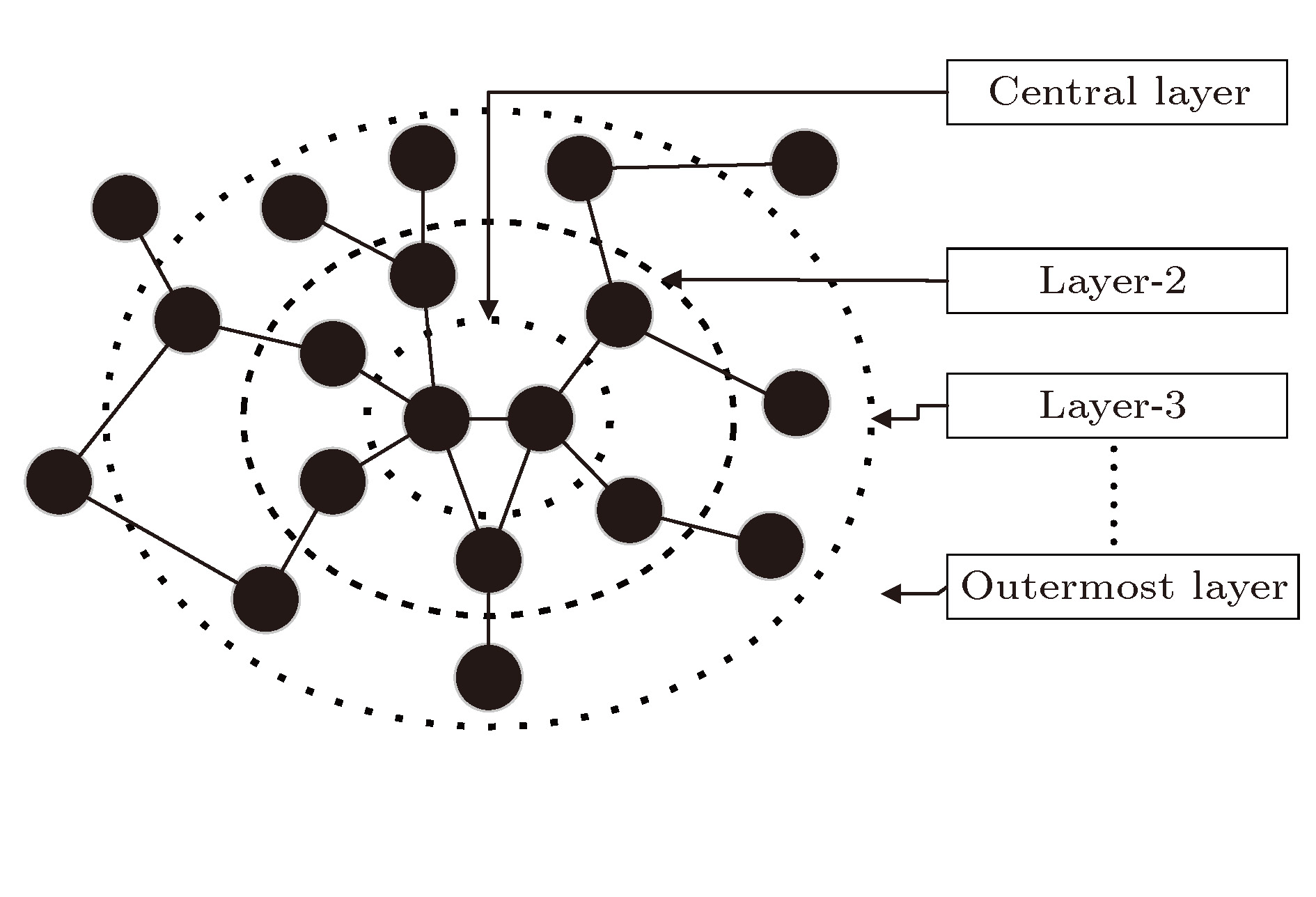
图 3 最大连通子网的分层逻辑结构
Fig. 3. Hierarchical logical structure of the largest connected subnet.
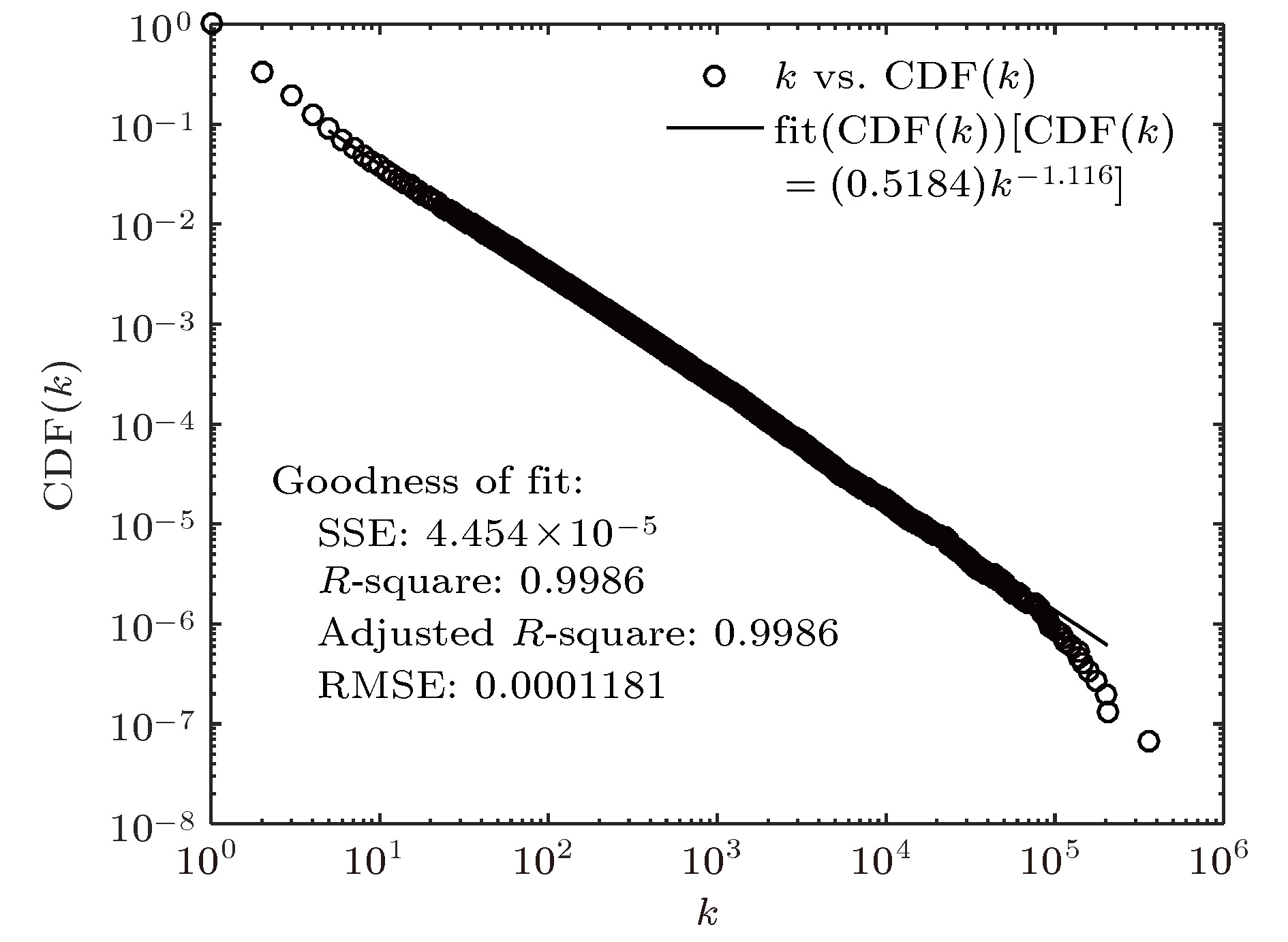
图 4 概念图谱最大连通子网累积度分布
Fig. 4. Cumulative degree distribution of the largest connected subnet.

图 8 度值对应的平均聚类系数分布
Fig. 8. Average clustering coefficient distribution corresponding to degree.
表 1 概念图谱网络的节点度分布
Table 1. Degree distribution of the concept graph network.
k Concept k Instance k SubConcept Quantity Proportion Quantity Proportion Quantity Proportion 1 2061496 0.464809 1 9610146 0.831317 1 18 1.91208 × 10–5 2 1165725 0.262838 2 1014355 0.087746 2 140735 0.149498132 3 538652 0.121451 3 312310 0.027016 3 186330 0.197932191 4 252438 0.056918 4 156703 0.013555 4 125273 0.133073361 5 130975 0.029531 5 96100 0.008313 5 78365 0.083244546 6 74760 0.016856 6 64809 0.005606 6 52113 0.055357915 7 46336 0.010447 7 46409 0.004015 7 37615 0.039957169 8 31509 0.007104 8 34801 0.00301 8 29314 0.031139292 9 22506 0.005074 9 27177 0.002351 9 23419 0.024877229 10 16510 0.003723 10 21928 0.001897 10 19484 0.020697208 11 12921 0.002913 11 18095 0.001565 11 16465 0.017490224 12 10012 0.002257 12 14935 0.001292 12 14188 0.015071443 13 8188 0.001846 13 12688 0.001098 13 12491 0.013268776 $\vdots$ $\vdots$ $\vdots$ $\vdots$ $\vdots$ $\vdots$ $\vdots$ $\vdots$ $\vdots$ 32773 1 2.25 × 10–7 6716 1 8.65 × 10–8 364276 1 1.06227 × 10–6 Total 4435143 1 Total 11560144 1 Total 941383 1  下载: 导出CSV
下载: 导出CSV
表 2 最大子网提取算法时间复杂度对比表
Table 2. Time complexity of the subset extraction algorithms.
Algorithm Parameters Time complexity Time cost NetworkX — — — 15 d以上 SNEBF m = 15 114 834 n = 33 377 320 m × 2n = 15 114 834 × 2n 约5.22 a SNESO nl = 12 n = 33 377 320 nl × 3.2n = 19.2 × 2n 3.49 min (实际运算3.80 min)
下载: 导出CSV
表 3 算法空间复杂度和实际内存消耗对比表
Table 3. Space complexity of the algorithms.
Algorithm Parameters Space complexity Memory cost NetworkX — — 40 GB ESNSO SubNeti, NeighborsSet, MaxSubNet 31724479 5.23 GB
下载: 导出CSV
表 4 概念图谱最大子网度分布分析
Table 4. Degree distribution analysis of the largest connected subnet.
k Concept Instance SubConcept Total Quantity Percentage Quantity Percentage Quantity Percentage Quantity 1 1468308 40.3 8636049 82.0 0 0.0 10104357 2 1014641 27.9 968156 9.2 138875 14.8 2121672 3 503109 13.8 309716 2.9 185665 19.8 998490 4 242308 6.7 156248 1.5 125045 13.3 523601 5 127833 3.5 96027 0.9 78311 8.3 302171 6 73429 2.0 64778 0.6 52090 5.6 190297 7 45834 1.3 46398 0.4 37604 4.0 129836 8 31237 0.9 34799 0.3 29301 3.1 95337 9 22401 0.6 27173 0.3 23417 2.5 72991 10 16439 0.5 21925 0.2 19488 2.1 57852 11 12880 0.4 18095 0.2 16464 1.8 47439 12 9981 0.3 14934 0.1 14187 1.5 39102 13 8169 0.2 12688 0.1 12503 1.3 33360 $\vdots$ $\vdots$ $\vdots$ $\vdots$ $\vdots$ $\vdots$ $\vdots$ $\vdots$ Total 3639631 ··· 10536663 ··· 938540 ··· 15114838
下载: 导出CSV
表 5 核心层中度值最高的20个节点
Table 5. Top 20 nodes with the highest degree in core.
node k node k factor 364343 Event 113364 feature 204130 company 110609 issue 202331 program 93963 product 174283 technique 92341 item 159164 application 90644 area 144595 organization 90605 topic 137781 Name 87637 service 137398 Case 85863 activity 124670 method 84157 information 114500 project 82122
下载: 导出CSV
表 6 部分阈值网络及节点数
Table 6. Threshold networks and the number of nodes.
t n e t n e t n e t n e 10 415491 936536 60 27654 66704 150 9492 19845 600 1788 2637 20 119367 303323 70 23089 54533 200 6850 13315 700 1453 2059 30 66272 169774 80 19567 45510 300 4336 7566 800 1076 1487 40 45410 114629 90 17042 38921 400 3013 4920 900 922 1222 50 34467 85085 100 15086 33983 500 2318 3577 1000 770 994
下载: 导出CSV
表 7 子网结构与节点数量
Table 7. Subnet structure and quantity of nodes.
Layer Quantity Layer Quantity Layer Quantity Layer Quantity 1 2 4 4639826 7 11921 10 73 2 553406 5 639119 8 1609 11 16 3 9202185 6 66347 9 327 12 3
下载: 导出CSV
表 8 不同阈值网络的层次结构及各层的节点数
Table 8. Layer structure and node number in each layer.
Layer t = 10 t = 20 t = 30 t = 50 t = 100 t = 200 t = 300 t = 500 t = 1000 1 2 2 2 2 2 2 2 2 2 2 26993 10212 6226 3409 1534 748 456 258 88 3 223659 65471 34244 16456 6445 2437 1305 558 103 4 131967 36095 21646 12077 5712 2829 1722 832 205 5 28219 6590 3563 2037 1116 656 661 438 108 6 3745 821 505 418 206 129 157 187 128 7 766 143 74 55 62 41 30 29 89 8 98 25 12 11 7 4 3 13 29 9 27 6 — 2 2 3 — 1 13 10 12 2 — — — 1 — — 5 11 3 — — — — — — — —
下载: 导出CSV
表 9 部分度的节点数与该度值的所有节点的邻点平均度
Table 9. Part of Nk and knn(k).
k Nk knn(k) k Nk knn(k) 1 10104357 31235.02 159164 1(item) 122.577 2 2121672 13384.27 174283 1(product) 98.812 3 998490 10435.94 202331 1(issue) 91.266 4 523601 10231.12 204130 1(feature) 85.926 5 302171 10388.98 364343 1(factor) 56.088 $\vdots$ $\vdots$ $\vdots$ $\vdots$ $\vdots$ $\vdots$
下载: 导出CSV
-
[1] Wang Z Y, Wang H X, Wen J R, Xiao Y H 2015 ACM International Conference on Information and Knowledge Management Melbourne, Australia, October 18−23, 2015 p653
[2] Hagberg A A, Schult D A, Swart P J 2008Proceedings of the 7th Python in Science Conference Pasadena, CA USA, August 19–24, 2008 p11
[3] Watts D J, Strogatz S H 1998 Nature 393 440
Google Scholar
[4] Barabási A L, Albert R 1999 Science 286 509
Google Scholar
[5] 刘志宏, 曾勇, 吴宏亮, 马建峰 2014 计算机研究与发展 51 2788
Google Scholar
Liu Z H, Zeng Y, Wu H L, Ma J F 2014 Journal of Computer Research and Development 51 2788
Google Scholar
[6] An H Z, Zhong W Q, Chen Y R, Li H J, Gao X Y 2014 Energy 74 254
Google Scholar
[7] Almog A, Squartini T, Garlaschelli D 2015 New J. Phys. 17 013009
Google Scholar
[8] 邢雪, 于德新, 田秀娟, 王世广 2017 物理学报 66 230501
Google Scholar
Xing X, Yu D X, Tian X J, Wang S G 2017 Acta Phys. Sin. 66 230501
Google Scholar
[9] Colombo A, Campos G R D, Rossa F D 2017 IEEE Trans. Autom. Control 62 4933
[10] Wan X, Li Q M, Yuan J F, Schonfeld P M 2015 Accid. Anal. Prev. 82 90
Google Scholar
[11] 叶堃晖, 袁欣 2018 资源开发与市场 34 59
Google Scholar
Ye K H, Yuan X 2018 Resources Development & Market 34 59
Google Scholar
[12] Hu Y H, Zhu D L 2009 Physica A 388 2061
Google Scholar
[13] Pien K C, Han K, Shang W L, Majumdar A 2015 Transportmetrica A 11 772
[14] Albert R, Jeong H, Barabási A L 2000 Nature 406 378
Google Scholar
[15] Broder A, Kumar R, Maghoul F, Raghavan P, Rajagopalan S, Stata R, Tomkins A, Wiener J 2000 Comput. Netw. 33 309
Google Scholar
[16] Albert R, Jeong H, Barabási A L 1999 Nature 401 130
Google Scholar
[17] Aiello W, Chung F, Lu L Y 2001 42nd Annual Symposium on Foundations of Computer Science Las Vegas, NV, USA October 14–17, 2001 p510
[18] Aiello W, Chung F, Lu L Y 2000 Proceedings of the Thirty-second Annual ACM Symposium on Theory of Computing Portland, Oregon, USA, May 21–23, 2000 p171
[19] Rattigan M, Maier M, Jensen D 2006 Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining Philadelphia, PA, USA, August 20–23, 2006 p357
[20] Fiedor P 2015 Acta Phys. Pol. A 127 863
Google Scholar
[21] Wang G J, Xie C, Stanley H E 2018 Comput. Econ. 51 607
Google Scholar
[22] 邱路, 贾天明, 杨会杰 2016 物理学报 65 198901
Google Scholar
Qiu L, Jia T M, Yang H J 2016 Acta Phys. Sin. 65 198901
Google Scholar
[23] 孙延风, 王朝勇 2018 物理学报 67 148901
Google Scholar
Sun Y F, Wang C Y 2018 Acta Phys. Sin. 67 148901
Google Scholar
[24] 阮逸润, 老松杨, 王俊德, 白亮, 陈立栋 2017 物理学报 66 038902
Google Scholar
Ruan Y R, Lao S Y, Wang J D, Bai L, Chen L D 2017 Acta Phys. Sin. 66 038902
Google Scholar
[25] Kitsak M, Gallos L K, Havlin S, Liljeros F, Muchnik L, Stanley H E, Makse H A 2010 Nat. Phys. 6 888
Google Scholar
[26] Li Q, Zhou T, Lu L Y, Chen D B 2014 Physica A 404 47
Google Scholar
[27] Ruan Y R, Lao S Y, Xiao Y D, Wang J D, Bai L 2016 Chin. Phys. Lett. 33 028901
Google Scholar
[28] 孔江涛, 黄健, 龚建兴, 李尔玉 2018 物理学报 67 098901
Google Scholar
Kong J T, Huang J, Gong J X, Li E Y 2018 Acta Phys. Sin. 67 098901
Google Scholar
[29] 韩定定, 姚青青, 陈趣, 钱江海 2017 物理学报 66 248901
Google Scholar
Han D D, Yao Q Q, Chen Q, Qian J H 2017 Acta Phys. Sin. 66 248901
Google Scholar
[30] Niu R W, Pan G J 2016 Chin. Phys. Lett. 33 068901
Google Scholar
[31] Jiang J, Zhang R, Guo L, Li W, Cai X 2016 Chin. Phys. Lett. 33 108901
Google Scholar
[32] 唐晋韬, 王挺, 王戟 2011 软件学报 22 2279
Tang J Y, Wang T, Wang W 2011 Journal of Software 22 2279
[33] NetworkX Developers https://networkx.github.io/documenta- tion/networkx1.9/modules/networkx/algorithms/components /connected.html#connected_component_subgraphs [2014-6-21]
[34] Newman M E J 2003 Phys. Rev. E 67 026126
Google Scholar
[35] Holme P, Kim B J, Yoon C N, Yoon C N, Han S K 2002 Phys. Rev. E 65 056109
Google Scholar

 下载:
下载:

计量
- 文章访问数: 24683
- PDF下载量: 192
- 被引次数: 0
