










-
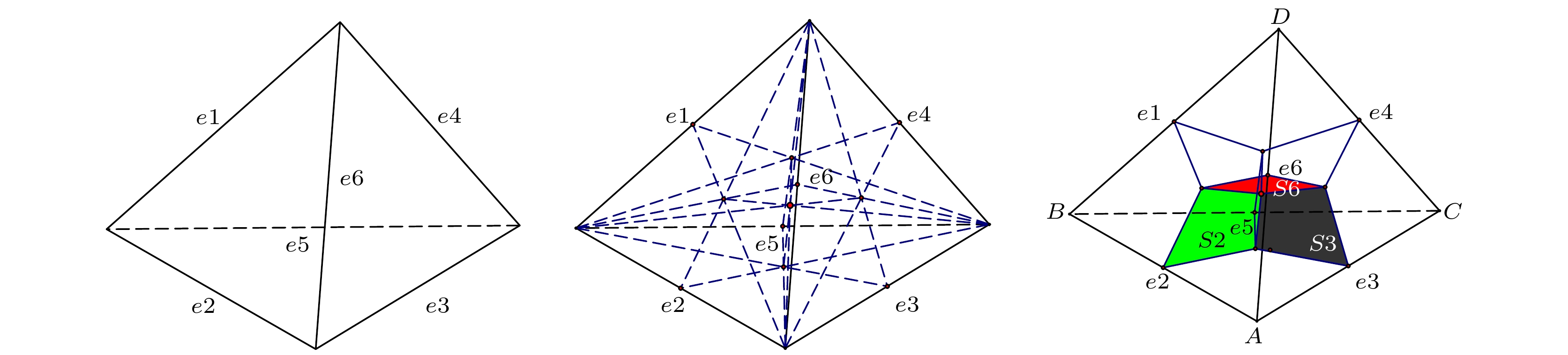
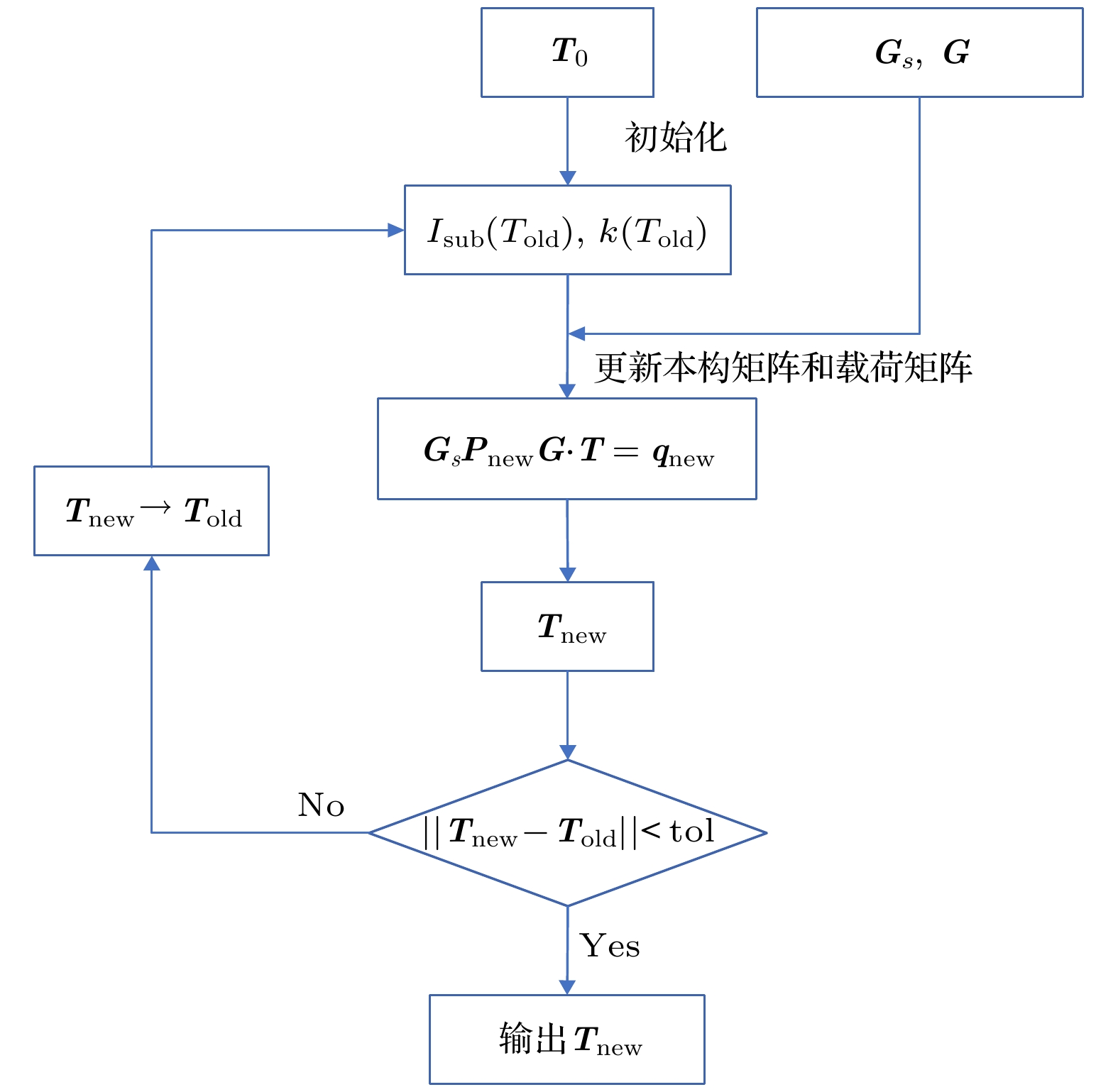
随着三维集成微系统集成度和功率密度的提高, 同时考察电设计与热管理的多场耦合分析势在必行. 本文面向三维集成微处理器系统, 通过改进的对偶单元法(dual cell method, DCM)实现了系统的快速电热分析. 该方法通过引入泄漏功率、材料系数随温度的耦合, 相比于传统有限元法在更新以及组装本构矩阵上有更大的优势. 仿真验证表明, 本文所采用的算法相比传统有限元法仿真速度提升了约30%. 在考虑了材料系数以及泄露功率热耦合因素后, 系统热点温度相对于考虑耦合前上升了20.8 K. 最后采用本文所提出算法对三维集成微处理器系统进行布局研究, 比较了硅通孔阵列常规布局和集中布局在处理器核心下方两种布局方式对上下层芯片热点温度的影响, 研究了功率不均匀分配对两种布局的影响.With the improvement of the integration and power density of three-dimensional integrated microsystem, it is imperative to simultaneously investigate the multi-field coupling analysis of electrical design and thermal management. This paper is to investigate a three-dimensional integrated microprocessor system and realize the rapid electrothermal analysis of the system through an improved dual cell method (DCM). This method decomposes the constitutive matrix into a constant matrix and a temperature-dependent matrix by introducing the coupling of leakage power and material coefficients with temperature. In the calculation, only the temperature-dependent matrix needs to be updated and assembled, which makes the calculation speed faster than the traditional finite element method. The simulation results show that the speed of the proposed algorithm is improved by about 30% compared with that of the traditional finite element method. After considering the thermal coupling factors of material coefficient and leakage power, the hot spot temperature of the system increases by 20.8 K compared with before coupling. Finally, the algorithm proposed in this paper is used to study the layout of three-dimensional integrated microprocessor system. The influence of TSV array conventional layout and centralized layout under the processor core(core-layout) on the hot spot temperature of upper and lower chips are compared, and the influences of uneven power distribution on the two layouts are studied. The results show that compared with the conventional layout of TSV array, the core-layout can reduce the hot spot temperature of processor, but it will aggravate the hot spot problem of DRAM at the same time. And when the power is not evenly distributed on the four cores, the hot spot of DRAM under the core-layout will be more seriously affected. In conclusion, the algorithm model proposed in this paper can quickly analyze the electrothermal coupling problem of 3D integrated microsystem, realize the hot spot prediction of the system, and provide theoretical guidance for designing the chip layout of 3D integrated microsystem.
-
Keywords:
- three-dimensional integrated microsystem /
- dual cell method /
- electrothermal coupling /
- finite element method
[1] Benkart P, Kaiser A, Munding A, Bschorr M, Pfleiderer H J, Kohn E, Heittmann A, Huebner H, Ramacher U 2005 IEEE Des. Test Comput. 22 512
 Google Scholar
Google Scholar
[2] P op, E 2010 Nano Res. 3 147
Google Scholar
[3] Li S, Ahn J H, Strong R D, Brockman J B, Tullsen D M, Jouppi N P 2010 2009 42nd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO) New York, United states, December 12–16, 2009 p469
[4] Wang X P, Yin W Y, He S 2010 IEEE Trans. Electron Devices 57 1382
Google Scholar
[5] 冯永平, 崔俊芝, 邓明香 2009 物理学报 58 327
Google Scholar
Feng Y P, Cui J Z, Deng M X 2009 Acta Phys. Sin. 58 327
Google Scholar
[6] Xie J Y, Swaminathan M 2014 IEEE Trans. Compon. Pack. Manuf. Technol. 4 588
Google Scholar
[7] Lu T J, Jin J M 2014 IEEE Trans. Compon. Pack. Manuf. Technol. 4 1684
Google Scholar
[8] Sai M P D, Yu H, Shang Y, Tan C S 2013 IEEE Trans. Comput-Aided Des. Integr. Circuits Syst. 32 1734
Google Scholar
[9] 王存海, 郑树, 张欣欣 2020 物理学报 69 034401
Google Scholar
Wang C H, Zheng S, Zhang X X 2020 Acta Phys. Sin. 69 034401
Google Scholar
[10] Wang D W, Zhao W S, Chen W C, Zhu G D, Xie H, Gao P Q, Yin W Y 2019 IEEE Trans. Electron Devices 66 5117
Google Scholar
[11] 柴泾睿 2019 博士学位论文 (西安: 西安电子科技大学)
Chai J R 2019 Ph. D. Dissertation (Xi'an: Xidian University) (in Chinese)
[12] Lin S G, Chrysler R, Mahajan V K.De K, Banerjee K 2007 IEEE Trans. Electron Devices 54 3342
Google Scholar
[13] Lin S G, Chrysler R, Mahajan V K.De K, Banerjee K 2007 IEEE Trans. Electron Devices 54 3351
Google Scholar
[14] Pi Y D, Wang N Y, Chen J, Miao M, Jin Y F, Wang W 2018 Int. J. Heat Mass Transfer 120 361
Google Scholar
[15] Chai J R, Dong G, Yang Y T 2019 IEEE Trans. Electron Devices 66 1032
Google Scholar
[16] Wang H, Wan J C, Tan S, Zhang C, Tang H, Yuan Y, Huang K H, Zhang Z H 2018 IEEE Trans. Comput. 67 617
Google Scholar
[17] Alotto P, Freschi F, Repetto M, Rosso C 2013 The Cell Method for Electrical Engineering and Multiphysics Problems (Berlin-Heidelberg: Springer-Verlag) pp11−113
[18] Tonti E 2001 CMES-Comput. Model. Eng. Sci. 2 237
Google Scholar
[19] Freschi F, Giaccone L, Repetto M 2008 Compel-Int. J. Comput. Math. Electr. Electron. Eng. 27 1343
Google Scholar
[20] Alotto P, Freschi F, Repetto M 2010 IEEE Trans. Magn. 46 2959
Google Scholar
[21] Zhang Y, Sarvey T E, Bakir M S 2014 2014 International 3D Systems Integration Conference (3DIC) Kinsdale, Ireland, December 1–3, 2014 p14
[22] Ma H, Yu D Q, Wang J 2014 Microelectron. Reliab. 54 425
Google Scholar
[23] Tavakkoli F, Ebrahimi S, Wang S, Vafai K 2016 Int. J. Heat Mass Transfer 97 337
Google Scholar
[24] Ren Z, Alqahtani A, Bagherzadeh N, Lee J 2020 IEEE Trans. Compon. Pack. Manuf. Technol. 4 599
Google Scholar
-
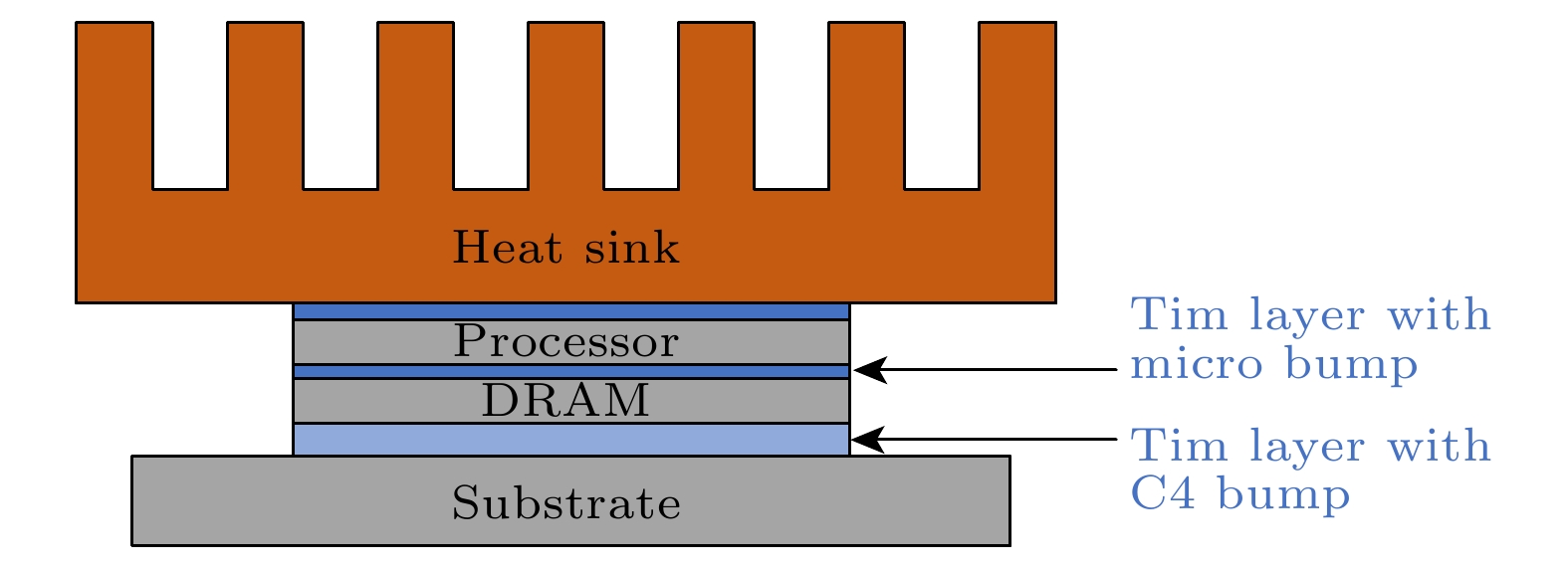
图 4 三维集成微处理器系统结构示意图
Fig. 4. Schematic diagram of the three-dimensional integrated microprocessor system.
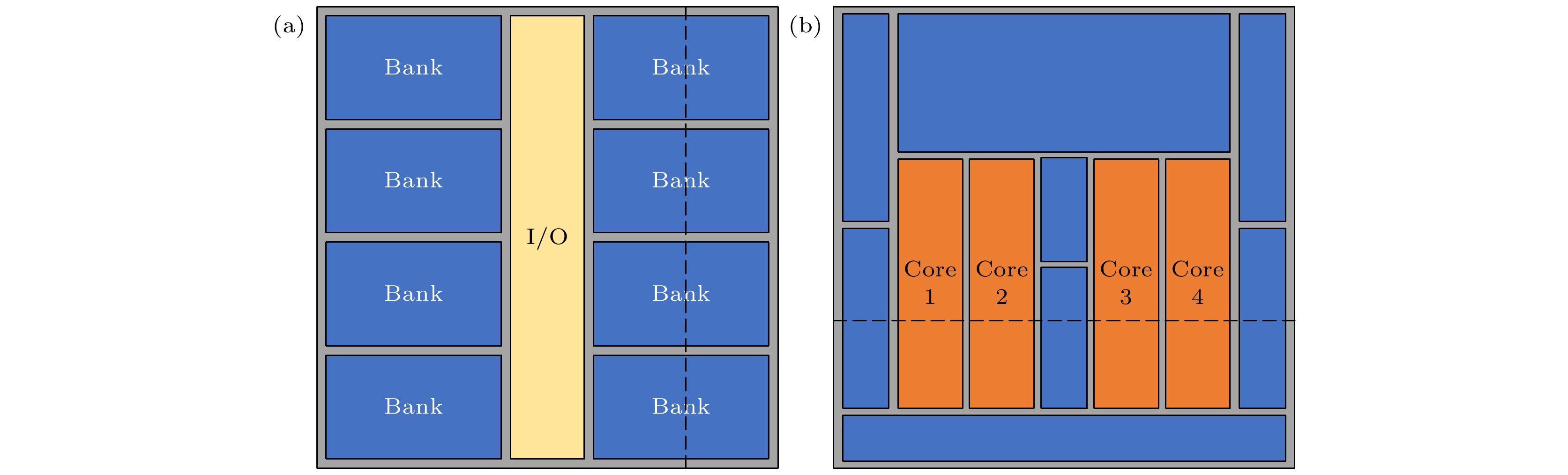
图 5 工作区域分布图 (a) DRAM芯片; (b) Intel i7处理器芯片
Fig. 5. Work area distribution map: (a) DRAM; (b) processor.
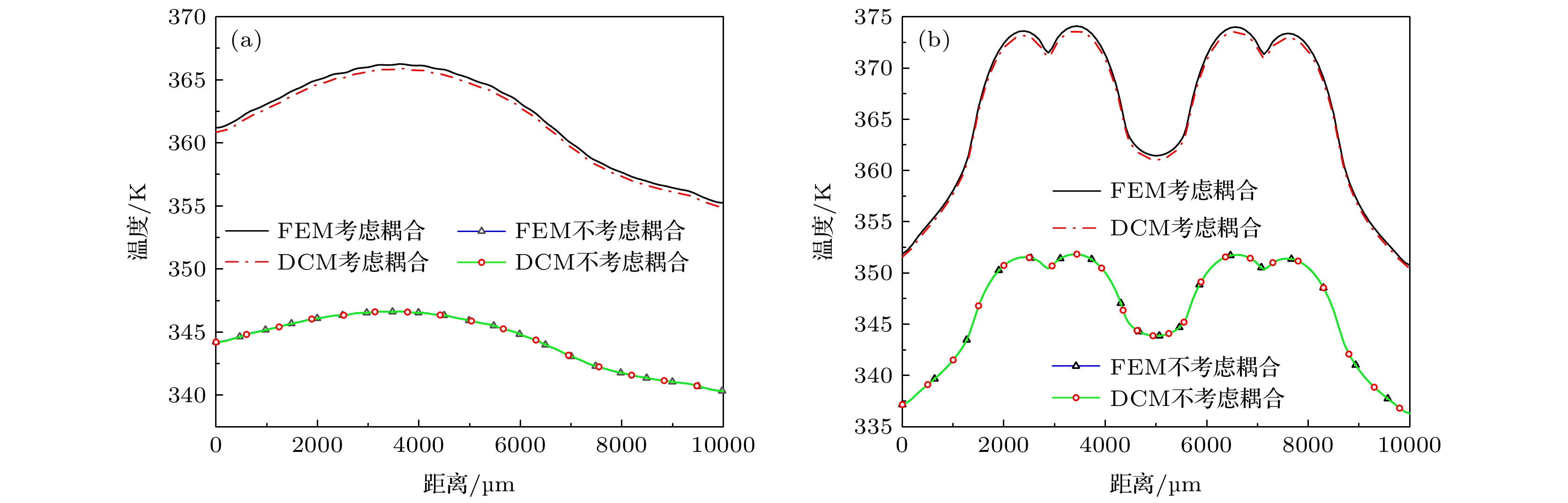
图 6 不考虑耦合与考虑耦合时芯片温度分布 (a) DRAM; (b) 处理器
Fig. 6. Chip temperature distribution without considering coupling and considering coupling: (a) DRAM; (b)processor.
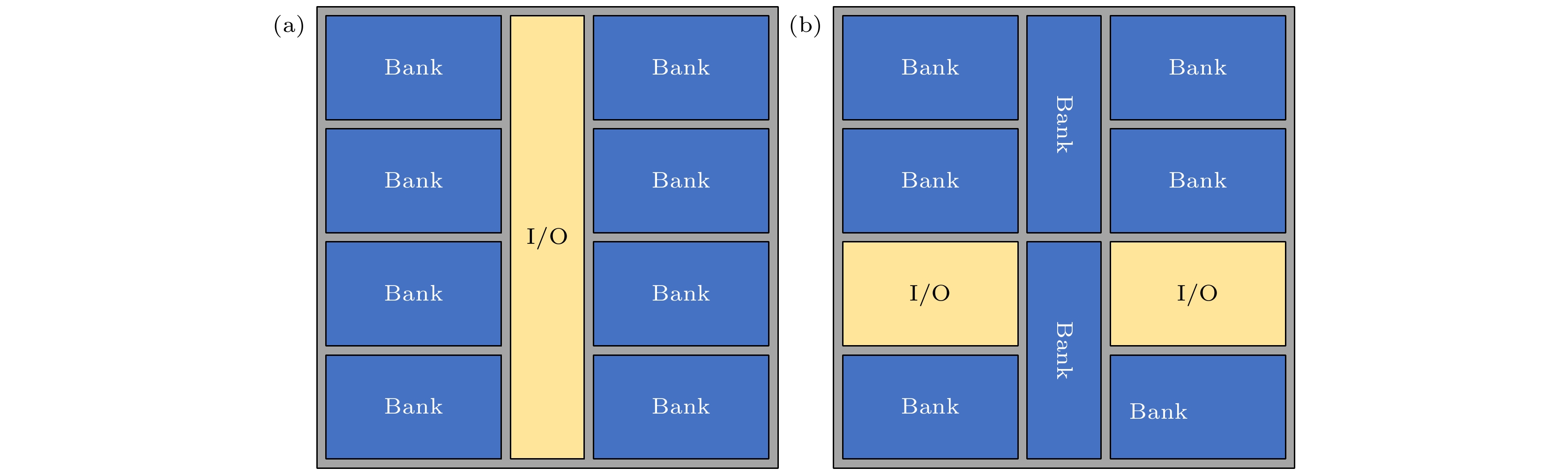
图 7 两种不同的TSV阵列布局 (a) 常规布局; (b) Core-布局
Fig. 7. Two different TSV array layouts: (a) Conventional layout; (b) core layout.
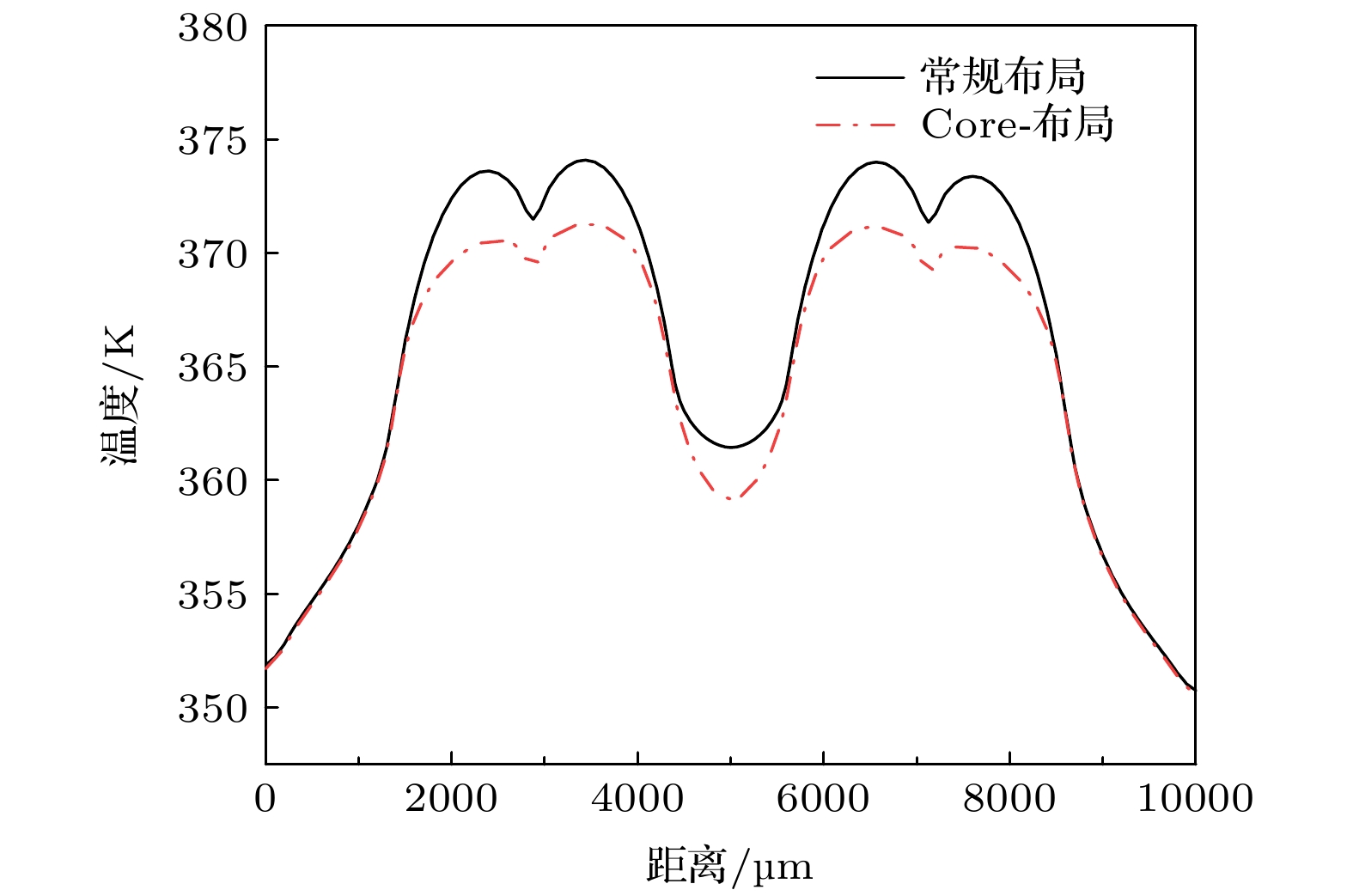
图 8 两种不同TSV阵列布局时处理器的温度分布
Fig. 8. Temperature distributions of processors with two different TSV arrays.
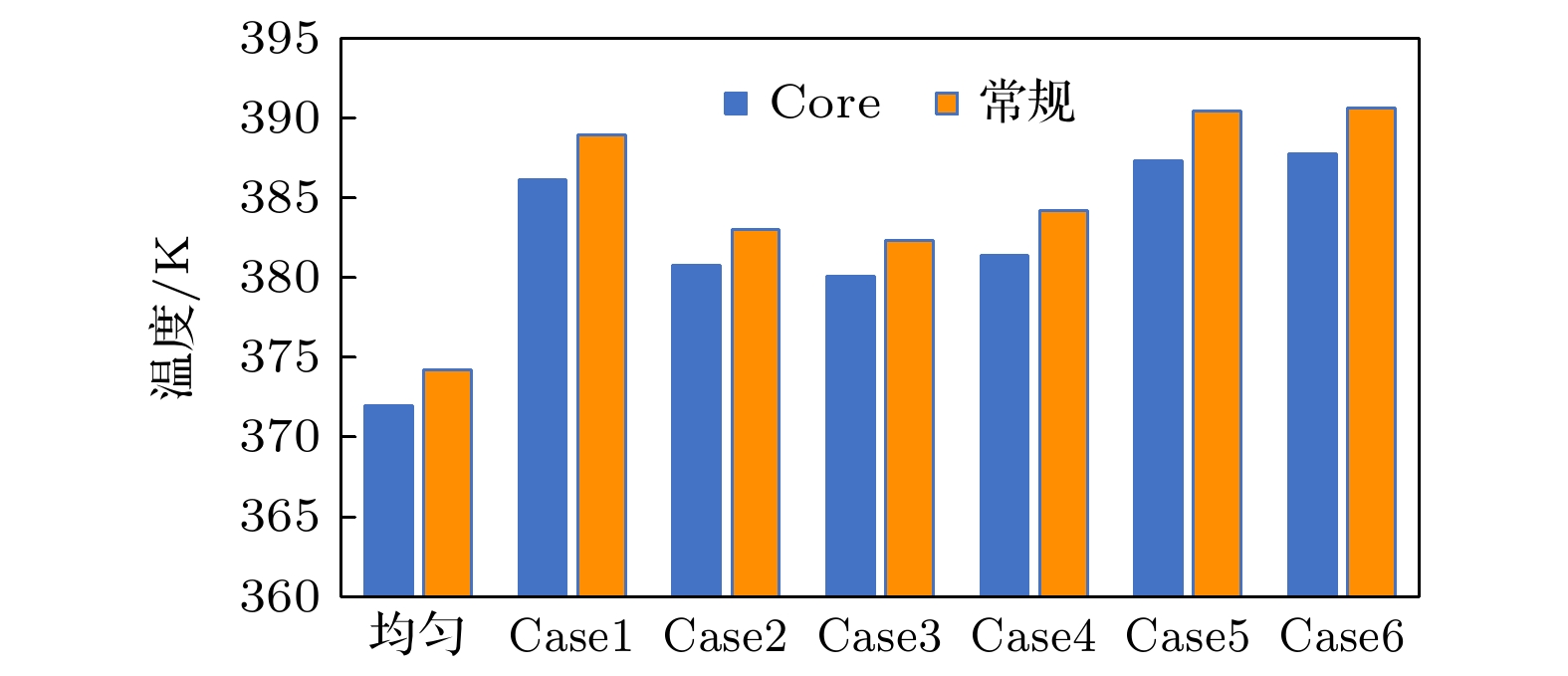
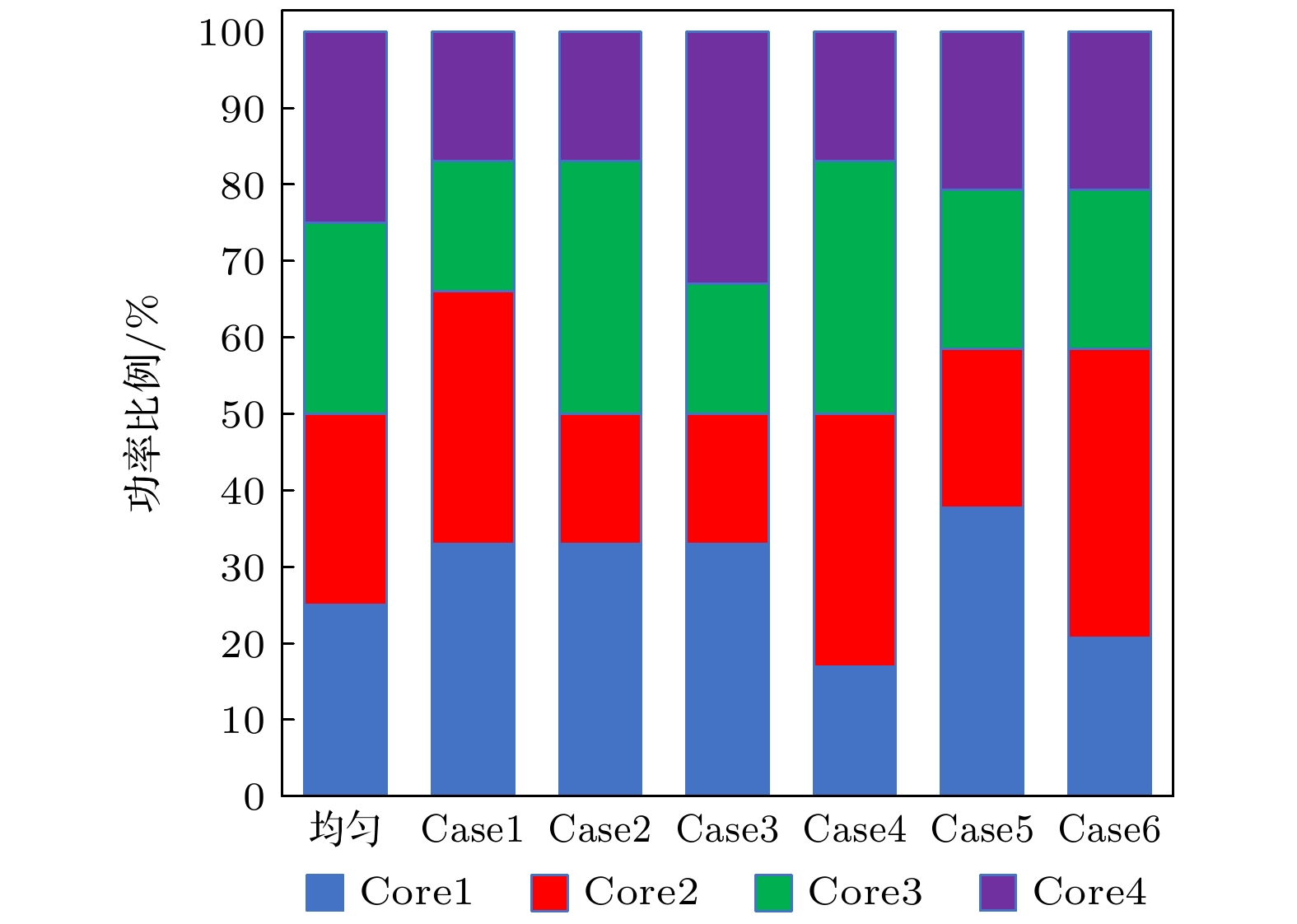
图 11 不同功率分配下处理器芯片最高温度
Fig. 11. Maximum temperature of processor chip under different power allocation.
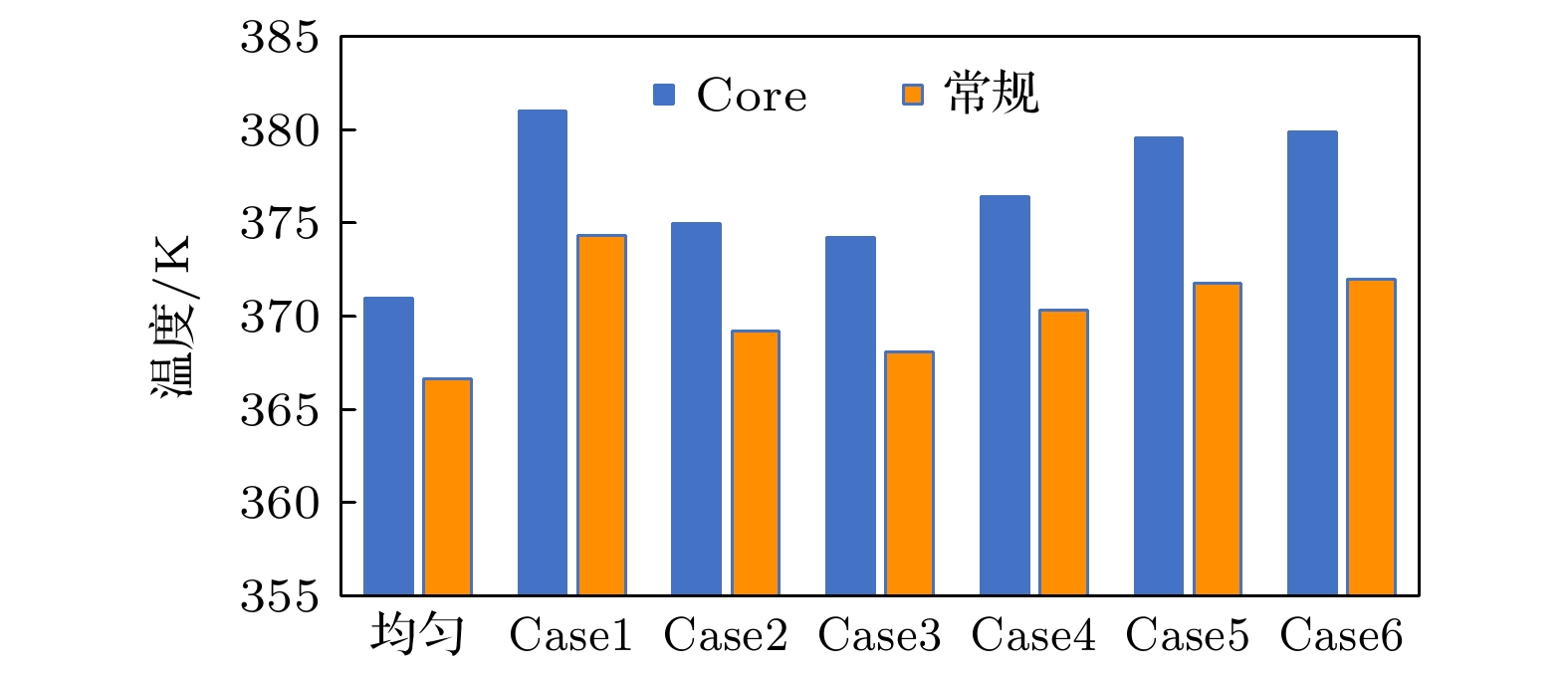
图 12 不同功率分配下DRAM芯片最高温度
Fig. 12. Maximum temperature of DRAM chip under different power allocation.
表 1 FEM与改进DCM的仿真时间对比
Table 1. Simulation time comparison between FEM and improved DCM.
耦合情况 仿真方法 仿真时间 仿真自由度 不考虑耦合 FEM 60 S 416941 改进DCM 55.3 S 电热耦合 FEM 154 S 改进DCM 104.7 S  下载: 导出CSV
下载: 导出CSV
表 2 不同功率分配时仿真时间
Table 2. Improving simulation time of DCM and FEM with different power allocation.
布局方式 改进的DCM法仿真时间/s FEM平均时间/s 自由度 Case1 Case2 Case3 Case4 Case5 Case6 常规布局 105.6 106.1 106.0 105.7 107.2 104.8 152.2 416941 Core布局 100.9 105.6 102.6 101.4 101.9 100.3 144.9 404345
下载: 导出CSV
表 3 不同功率分配下Core-布局相比于常规布局的芯片温度变化
Table 3. Chip temperature change of core layout compared with conventional layout under different power allocation.
温度变化 均匀 Case1 Case2 Case3 Case4 Case5 Case6 处理器降温/K 2.20 2.82 2.25 2.25 2.82 3.13 2.90 DRAM升温/K 4.29 6.69 5.77 6.12 6.09 7.83 7.88
下载: 导出CSV
-
[1] Benkart P, Kaiser A, Munding A, Bschorr M, Pfleiderer H J, Kohn E, Heittmann A, Huebner H, Ramacher U 2005 IEEE Des. Test Comput. 22 512
Google Scholar
[2] P op, E 2010 Nano Res. 3 147
Google Scholar
[3] Li S, Ahn J H, Strong R D, Brockman J B, Tullsen D M, Jouppi N P 2010 2009 42nd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO) New York, United states, December 12–16, 2009 p469
[4] Wang X P, Yin W Y, He S 2010 IEEE Trans. Electron Devices 57 1382
Google Scholar
[5] 冯永平, 崔俊芝, 邓明香 2009 物理学报 58 327
Google Scholar
Feng Y P, Cui J Z, Deng M X 2009 Acta Phys. Sin. 58 327
Google Scholar
[6] Xie J Y, Swaminathan M 2014 IEEE Trans. Compon. Pack. Manuf. Technol. 4 588
Google Scholar
[7] Lu T J, Jin J M 2014 IEEE Trans. Compon. Pack. Manuf. Technol. 4 1684
Google Scholar
[8] Sai M P D, Yu H, Shang Y, Tan C S 2013 IEEE Trans. Comput-Aided Des. Integr. Circuits Syst. 32 1734
Google Scholar
[9] 王存海, 郑树, 张欣欣 2020 物理学报 69 034401
Google Scholar
Wang C H, Zheng S, Zhang X X 2020 Acta Phys. Sin. 69 034401
Google Scholar
[10] Wang D W, Zhao W S, Chen W C, Zhu G D, Xie H, Gao P Q, Yin W Y 2019 IEEE Trans. Electron Devices 66 5117
Google Scholar
[11] 柴泾睿 2019 博士学位论文 (西安: 西安电子科技大学)
Chai J R 2019 Ph. D. Dissertation (Xi'an: Xidian University) (in Chinese)
[12] Lin S G, Chrysler R, Mahajan V K.De K, Banerjee K 2007 IEEE Trans. Electron Devices 54 3342
Google Scholar
[13] Lin S G, Chrysler R, Mahajan V K.De K, Banerjee K 2007 IEEE Trans. Electron Devices 54 3351
Google Scholar
[14] Pi Y D, Wang N Y, Chen J, Miao M, Jin Y F, Wang W 2018 Int. J. Heat Mass Transfer 120 361
Google Scholar
[15] Chai J R, Dong G, Yang Y T 2019 IEEE Trans. Electron Devices 66 1032
Google Scholar
[16] Wang H, Wan J C, Tan S, Zhang C, Tang H, Yuan Y, Huang K H, Zhang Z H 2018 IEEE Trans. Comput. 67 617
Google Scholar
[17] Alotto P, Freschi F, Repetto M, Rosso C 2013 The Cell Method for Electrical Engineering and Multiphysics Problems (Berlin-Heidelberg: Springer-Verlag) pp11−113
[18] Tonti E 2001 CMES-Comput. Model. Eng. Sci. 2 237
Google Scholar
[19] Freschi F, Giaccone L, Repetto M 2008 Compel-Int. J. Comput. Math. Electr. Electron. Eng. 27 1343
Google Scholar
[20] Alotto P, Freschi F, Repetto M 2010 IEEE Trans. Magn. 46 2959
Google Scholar
[21] Zhang Y, Sarvey T E, Bakir M S 2014 2014 International 3D Systems Integration Conference (3DIC) Kinsdale, Ireland, December 1–3, 2014 p14
[22] Ma H, Yu D Q, Wang J 2014 Microelectron. Reliab. 54 425
Google Scholar
[23] Tavakkoli F, Ebrahimi S, Wang S, Vafai K 2016 Int. J. Heat Mass Transfer 97 337
Google Scholar
[24] Ren Z, Alqahtani A, Bagherzadeh N, Lee J 2020 IEEE Trans. Compon. Pack. Manuf. Technol. 4 599
Google Scholar

 下载:
下载:

计量
- 文章访问数: 9007
- PDF下载量: 121
- 被引次数: 0
