











-
How to use quantitative analysis methods to identify which nodes are the most important in complex network, or to evaluate the importance of a node relative to one or more other nodes, is one of the hot issues in network science research. Now, a variety of effective models have been proposed to identify important nodes in complex network. Among them, the gravity model regards the coreness of nodes as the mass of object, the shortest distance between nodes as the distance between objects, and comprehensively considers the local information of nodes and path information to identify influential nodes. However, only the coreness is used to represente the quality of the object, and the factors considered are relatively simple. At the same time, some studies have shown that the network can easily identify the core-like group nodes with locally and highly clustering characteristics as core nodes when performing k-core decomposition, which leads to the inaccuracy of the gravity algorithm. Based on the universal gravitation method, considering the node H index, the number of node cores and the location of node structural holes, this paper proposes an improved algorithm ISM and its extended algorithm ISM+. The SIR model is used to simulate the propagation process in several classical real networks and artificial networks, and the results show that the proposed algorithm can better identify important nodes in the network than other centrality indicators.
-
Keywords:
- complex networks /
- spreading influence /
- gravity model /
- H index /
- k-shell method
[1] Lü L Y, Chen D B, Ren X L, Zhang Q M, Zhang Y C, Zhou T 2016 Phys. Rep. 650 1
 Google Scholar
Google Scholar
[2] Pastor-Satorras R, Vespignani A 2001 Phys. Rev. Lett. 86 3200
Google Scholar
[3] Albert R, Barabási A L 2002 Rev. Modern Phys. 74 47
Google Scholar
[4] Alshahrani M, Fuxi Z, Sameh A, Mekouar S, Huang S 2020 Inform. Sciences 527 88
Google Scholar
[5] Albert R, Jeong H, Barabási A L 1999 Nature 401 130
Google Scholar
[6] Chen D B, Lu L Y, Shang M S, Zhang Y C, Zhou T 2012 Physica A 391 1777
Google Scholar
[7] Sabidussi G 1966 Psychometrika 31 581
Google Scholar
[8] Freeman L C 1977 Sociometry 40 35
Google Scholar
[9] Kitsak M, Gallos L K, Havlin S, Liljeros F, Muchnik L, Stanley H E, Makse H A 2010 Nat. Phys. 6 888
[10] Lü L Y, Zhou T, Zhang Q M, Stanley H E 2016 Nat. Commun. 7 10168
Google Scholar
[11] Bae J, Kim S 2014 Physica A 395 549
Google Scholar
[12] Zeng A, Zhang C J 2013 Phys. Lett. A 377 1031
Google Scholar
[13] Zareie A, Sheikhahmadi A, Khamforoosh K 2018 Expert Syst. Appl. 108 96
Google Scholar
[14] Fei L, Lu J, Feng Y 2020 Comput. Ind. Eng. 142 106355
Google Scholar
[15] 韩忠明, 吴杨, 谭旭升, 段大高, 杨伟杰 2015 物理学报 64 058902
Google Scholar
Hang Z M, Wu Y, Tan X S, Duan D G, Yang W J 2015 Acta Phys. Sin. 64 058902
Google Scholar
[16] Wang Z X, Du C J, Fan J P, X Y 2017 Neurocomputing 260 466
Google Scholar
[17] 闫光辉, 张萌, 罗浩, 李世魁, 刘婷 2019 通信学报 40 109
Google Scholar
Yan G H, Zhang M, Luo H, Li S K, Liu T 2019 J. Communications 40 109
Google Scholar
[18] Alon U 2007 Nat. Rev. Genet. 8 450
Google Scholar
[19] Benson A R, Gleich D F, Leskovec J 2016 Science 353 163
Google Scholar
[20] Li Y, Deng Y 2018 Int. J. Comput. Commun. Control 13 792
Google Scholar
[21] Wang J, Qiao K Y, Zhang Z Y 2019 Future Gener. Comp. Sy. 91 1
Google Scholar
[22] Morone F, Makse H A 2015 Nature 527 544
[23] Zhong L F, Liu Q H, Wang W, Cai S M 2018 Physica A 511 78
Google Scholar
[24] Ma L L, Ma C, Zhang H F, Wang B H 2016 Physica A 451 205
Google Scholar
[25] Li Z, Ren T, Ma X Q, Liu S M, Zhang Y X, Zhou T 2019 Sci. Rep. 9 1
Google Scholar
[26] Yang X, Xiao F Y 2021 Knowl-Based Syst. 227 107198
Google Scholar
[27] Burt R S 2004 American J. Sociology 110 349
Google Scholar
[28] Liu Y, Tang M, Zhou T, Do Y 2015 Sci. Rep. 5 9602
[29] Newman M E J 2002 Phys. Rev. E 66 016128
Google Scholar
[30] Kendall M G 1945 Biometrika 33 239
Google Scholar
[31] Knight W R 1966 J. Amer. Statist. Assoc. 61 436
Google Scholar
[32] Rossi R, Ahmed N 2015 Twenty-ninth AAAI Conference on Artificial Intelligence Austin, Texas, USA, January 4 2015, pp4292–4293
[33] Blagus N, Šubelj L, Bajec M 2012 Physica A 391 2794
Google Scholar
[34] Newman M E J 2006 Phys. Rev. E 74 036104
Google Scholar
[35] Batagelj V, Mrvar A 1998 Connections 21 47
[36] Isella L, Stehlé J, Barrat A, Cattuto C, Pinton J F 2011 J. Theor. Biol. 271 166
Google Scholar
[37] Lin J H, Guo Q, Dong W Z, Tang L Y, Liu J G 2014 Phys. Lett. A 378 3279
Google Scholar
-

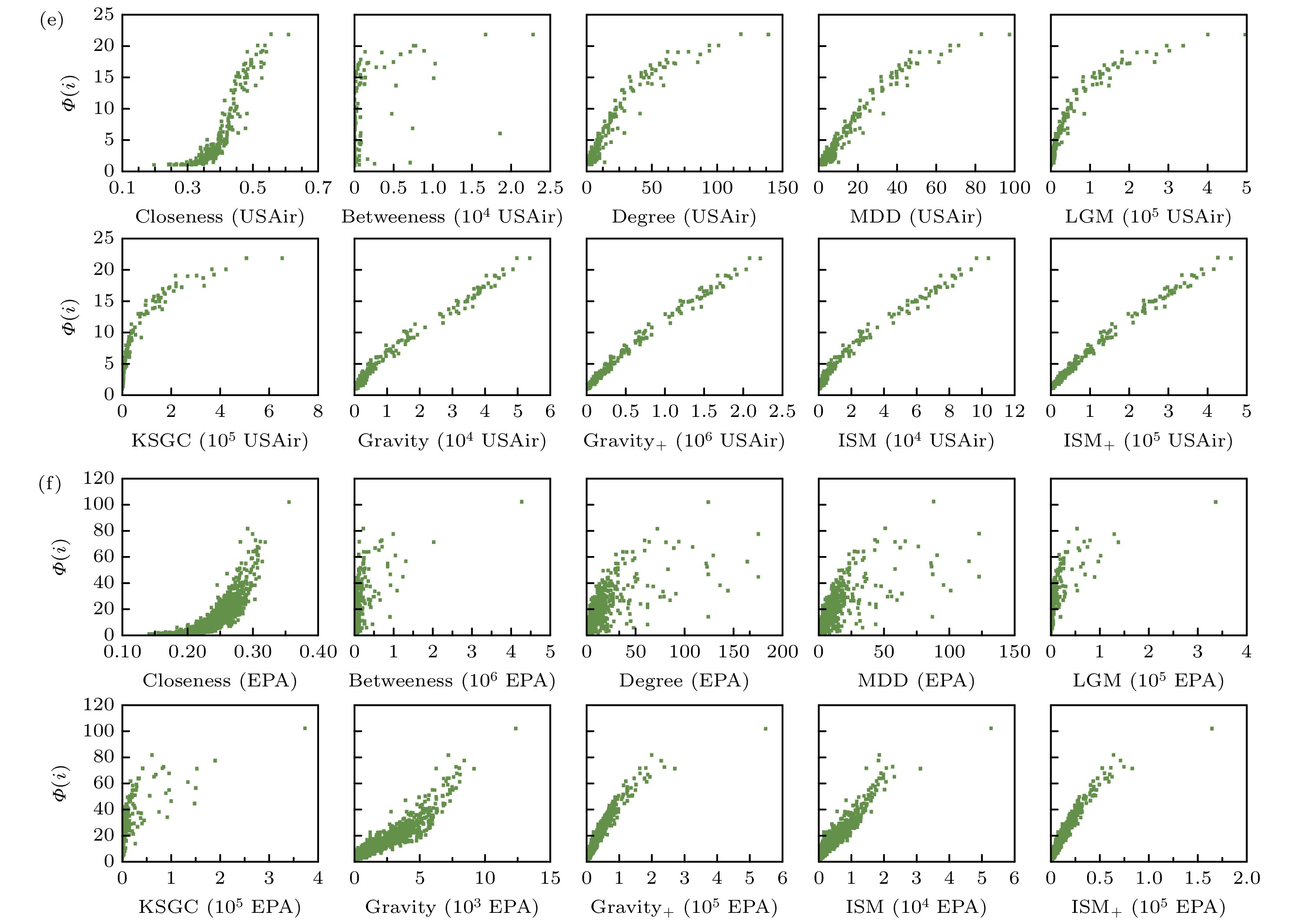
图 1 十种不同排序方法得到的排序结果与SIR传播过程感染节点数的相关性 (a) Enron; (b) Facebook; (c) Netscience; (d) Infectious; (e) USAir; (f) EPA
Figure 1. The correlation between the ranking results obtained by ten different ranking methods and the number of infected nodes in the SIR propagation process: (a) Enron; (b) Facebook; (c) Netscience; (d) Infectious; (e) USAir; (f) EPA.
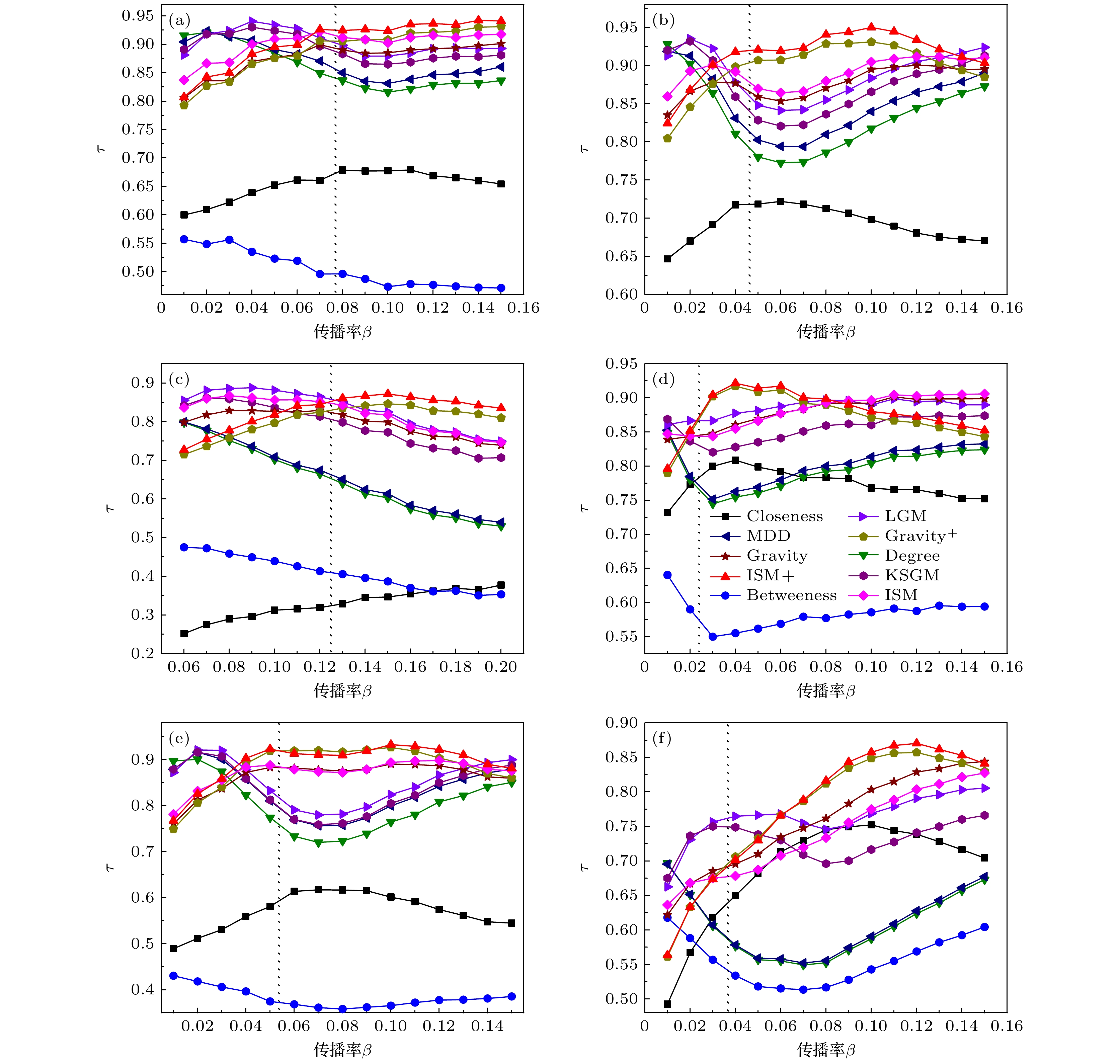
图 2 6个真实网络数据集上十种不同排序方法排序准确性对比 (a) Enron; (b) Facebook; (c) Netscience; (d) Infectious; (e) USAir; (f) EPA
Figure 2. Comparison of sorting accuracy of ten different sorting methods on six real network datasets: (a) Enron; (b) Facebook; (c) Netscience; (d) Infectious; (e) USAir; (f) EPA.

图 3 不同比例节点下十种评估算法的Kendall相关系数对比 (a) Enron; (b) Facebook; (c) Netscience; (d) Infectious; (e) USAir; (f) EPA
Figure 3. Comparison of Kendall correlation coefficients of ten node influence evaluation algorithms under different scale nodes: (a) Enron; (b) Facebook; (c) Netscience; (d) Infectious; (e) USAir; (f) EPA.
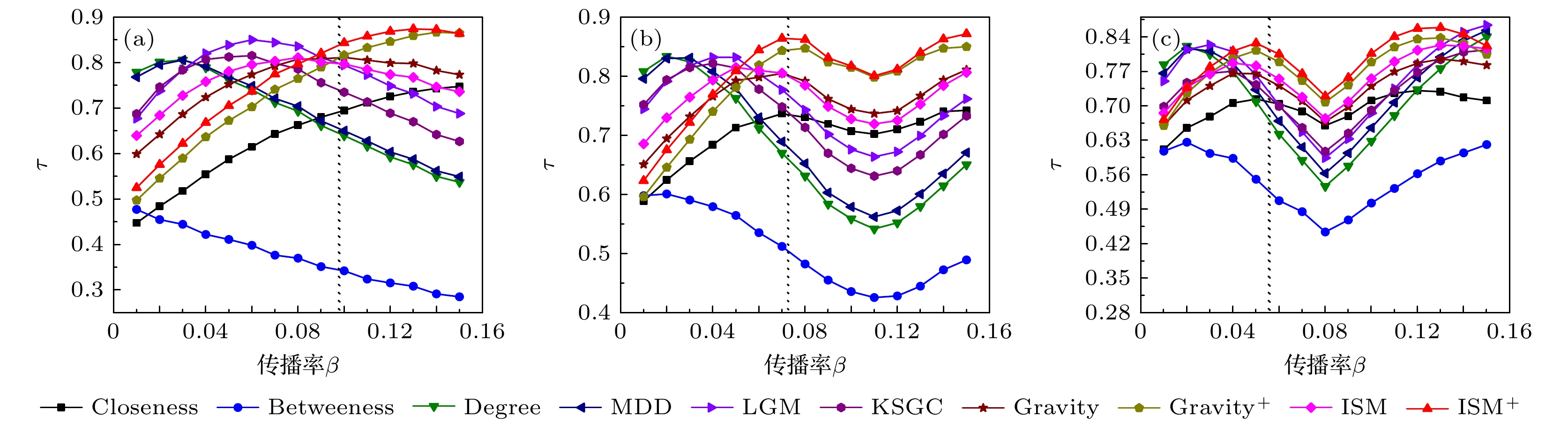
图 4 LFR模拟数据集上十种评估算法的Kendall相关系数对比, 黑色虚线为三个网络的传播阈值βth
(a) $\langle k\rangle $ = 5, βth = 0.0984; (b)$\langle k\rangle $ = 10, βth = 0.0723; (c)$\langle k\rangle $ = 15, βth = 0.0577Figure 4. Comparison of Kendall correlation coefficients of ten evaluation algorithms on the LFR simulation dataset, the black dashed line is the propagation threshold βth of three different network: (a)
$\langle k\rangle $ = 5, βth = 0.0984; (b)$\langle k\rangle $ = 10, βth = 0.0723; (c)$\langle k\rangle $ = 15, βth = 0.0577.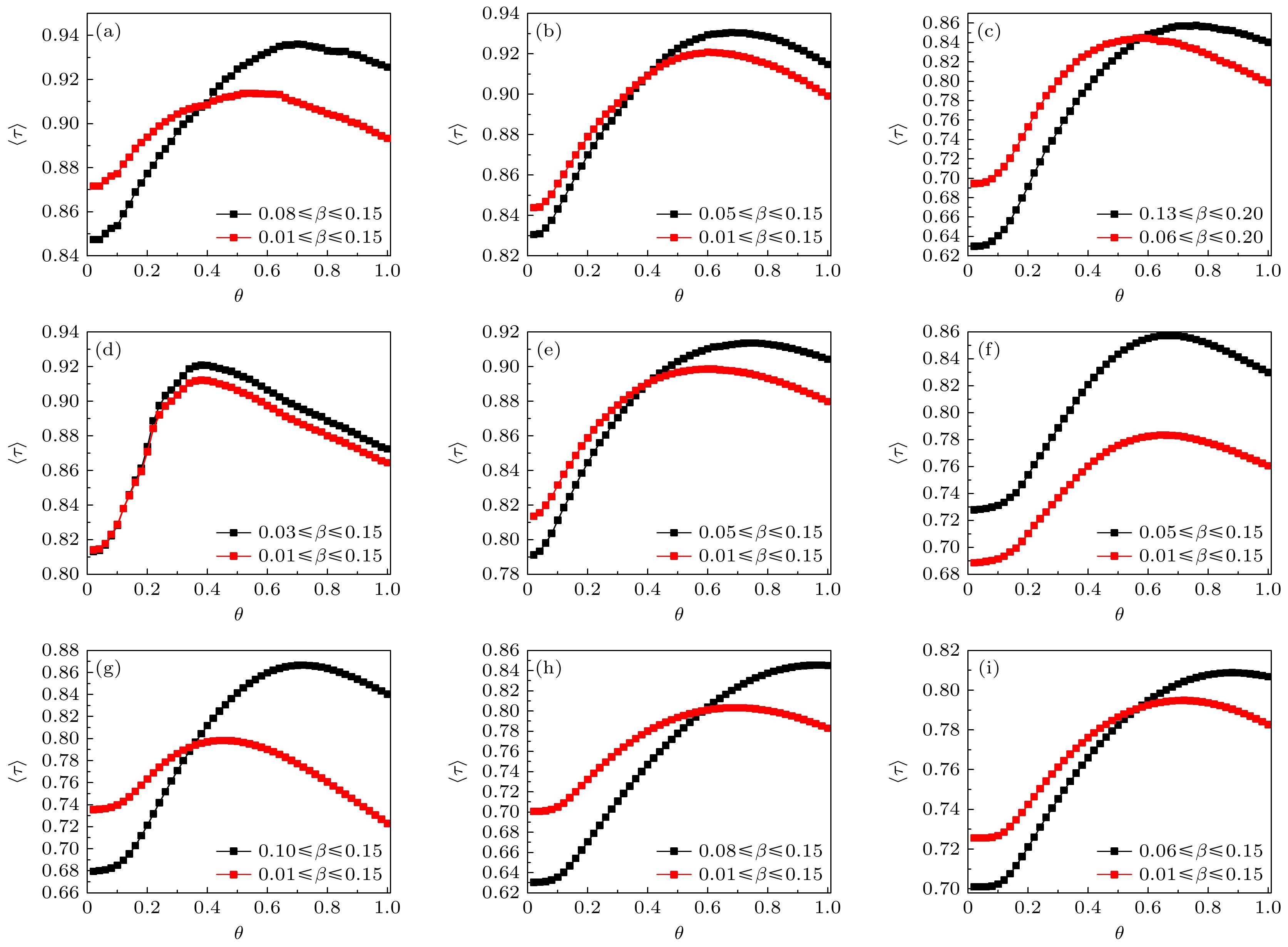
图 5 当β变化时, 不同θ值所对应的ISM+方法生成的节点重要性排序序列与SIR传播扩散过程生成的节点传播影响力排序序列之间的平均Kendall
$\langle \tau \rangle $ 值 (a) Enron; (b) Facebook; (c) Netscience; (d) Infectious; (e) USAir; (f) EPA; (g) LFR_k5; (h) LFR_k10; (i) LFR_k15Figure 5. The average Kendall’s
$\langle \tau \rangle $ obtained by comparing the ranking list generated by SIR spreading process and the ranking list generated by the ISM+ methods with different θ when the β changes: (a) Enron; (b) Facebook; (c) Netscience; (d) Infectious; (e) USAir; (f) EPA; (g) LFR_k5; (h) LFR_k10; (i) LFR_k15.表 1 6个真实网络的拓扑统计参数
Table 1. Topological parameters of six real networks.
网络名 N E $ \langle d \rangle $ ${\beta _{{\text{th}}}}$ $\beta $ $ \langle k \rangle $ C D $ k{s_{\max }} $ Enron 143 623 2.9670 0.0774 0.08 8.7133 0.4339 8 9 Facebook 324 2218 3.0537 0.0466 0.05 13.6914 0.4658 7 18 Netscience 379 914 6.0419 0.1250 0.13 4.8232 0.7410 17 8 USAir 453 2025 2.7381 0.0231 0.03 12.8072 0.6252 6 26 Infectious 410 2765 3.6309 0.0534 0.05 13.4878 0.4558 9 17 Web_EPA 4253 6258 4.5003 0.0366 0.08 4.1839 0.0714 10 6  DownLoad: CSV
DownLoad: CSV
-
[1] Lü L Y, Chen D B, Ren X L, Zhang Q M, Zhang Y C, Zhou T 2016 Phys. Rep. 650 1
Google Scholar
[2] Pastor-Satorras R, Vespignani A 2001 Phys. Rev. Lett. 86 3200
Google Scholar
[3] Albert R, Barabási A L 2002 Rev. Modern Phys. 74 47
Google Scholar
[4] Alshahrani M, Fuxi Z, Sameh A, Mekouar S, Huang S 2020 Inform. Sciences 527 88
Google Scholar
[5] Albert R, Jeong H, Barabási A L 1999 Nature 401 130
Google Scholar
[6] Chen D B, Lu L Y, Shang M S, Zhang Y C, Zhou T 2012 Physica A 391 1777
Google Scholar
[7] Sabidussi G 1966 Psychometrika 31 581
Google Scholar
[8] Freeman L C 1977 Sociometry 40 35
Google Scholar
[9] Kitsak M, Gallos L K, Havlin S, Liljeros F, Muchnik L, Stanley H E, Makse H A 2010 Nat. Phys. 6 888
[10] Lü L Y, Zhou T, Zhang Q M, Stanley H E 2016 Nat. Commun. 7 10168
Google Scholar
[11] Bae J, Kim S 2014 Physica A 395 549
Google Scholar
[12] Zeng A, Zhang C J 2013 Phys. Lett. A 377 1031
Google Scholar
[13] Zareie A, Sheikhahmadi A, Khamforoosh K 2018 Expert Syst. Appl. 108 96
Google Scholar
[14] Fei L, Lu J, Feng Y 2020 Comput. Ind. Eng. 142 106355
Google Scholar
[15] 韩忠明, 吴杨, 谭旭升, 段大高, 杨伟杰 2015 物理学报 64 058902
Google Scholar
Hang Z M, Wu Y, Tan X S, Duan D G, Yang W J 2015 Acta Phys. Sin. 64 058902
Google Scholar
[16] Wang Z X, Du C J, Fan J P, X Y 2017 Neurocomputing 260 466
Google Scholar
[17] 闫光辉, 张萌, 罗浩, 李世魁, 刘婷 2019 通信学报 40 109
Google Scholar
Yan G H, Zhang M, Luo H, Li S K, Liu T 2019 J. Communications 40 109
Google Scholar
[18] Alon U 2007 Nat. Rev. Genet. 8 450
Google Scholar
[19] Benson A R, Gleich D F, Leskovec J 2016 Science 353 163
Google Scholar
[20] Li Y, Deng Y 2018 Int. J. Comput. Commun. Control 13 792
Google Scholar
[21] Wang J, Qiao K Y, Zhang Z Y 2019 Future Gener. Comp. Sy. 91 1
Google Scholar
[22] Morone F, Makse H A 2015 Nature 527 544
[23] Zhong L F, Liu Q H, Wang W, Cai S M 2018 Physica A 511 78
Google Scholar
[24] Ma L L, Ma C, Zhang H F, Wang B H 2016 Physica A 451 205
Google Scholar
[25] Li Z, Ren T, Ma X Q, Liu S M, Zhang Y X, Zhou T 2019 Sci. Rep. 9 1
Google Scholar
[26] Yang X, Xiao F Y 2021 Knowl-Based Syst. 227 107198
Google Scholar
[27] Burt R S 2004 American J. Sociology 110 349
Google Scholar
[28] Liu Y, Tang M, Zhou T, Do Y 2015 Sci. Rep. 5 9602
[29] Newman M E J 2002 Phys. Rev. E 66 016128
Google Scholar
[30] Kendall M G 1945 Biometrika 33 239
Google Scholar
[31] Knight W R 1966 J. Amer. Statist. Assoc. 61 436
Google Scholar
[32] Rossi R, Ahmed N 2015 Twenty-ninth AAAI Conference on Artificial Intelligence Austin, Texas, USA, January 4 2015, pp4292–4293
[33] Blagus N, Šubelj L, Bajec M 2012 Physica A 391 2794
Google Scholar
[34] Newman M E J 2006 Phys. Rev. E 74 036104
Google Scholar
[35] Batagelj V, Mrvar A 1998 Connections 21 47
[36] Isella L, Stehlé J, Barrat A, Cattuto C, Pinton J F 2011 J. Theor. Biol. 271 166
Google Scholar
[37] Lin J H, Guo Q, Dong W Z, Tang L Y, Liu J G 2014 Phys. Lett. A 378 3279
Google Scholar

 DownLoad:
DownLoad:








Catalog
Metrics
- Abstract views: 11601
- PDF Downloads: 258
- Cited By: 0
