










-
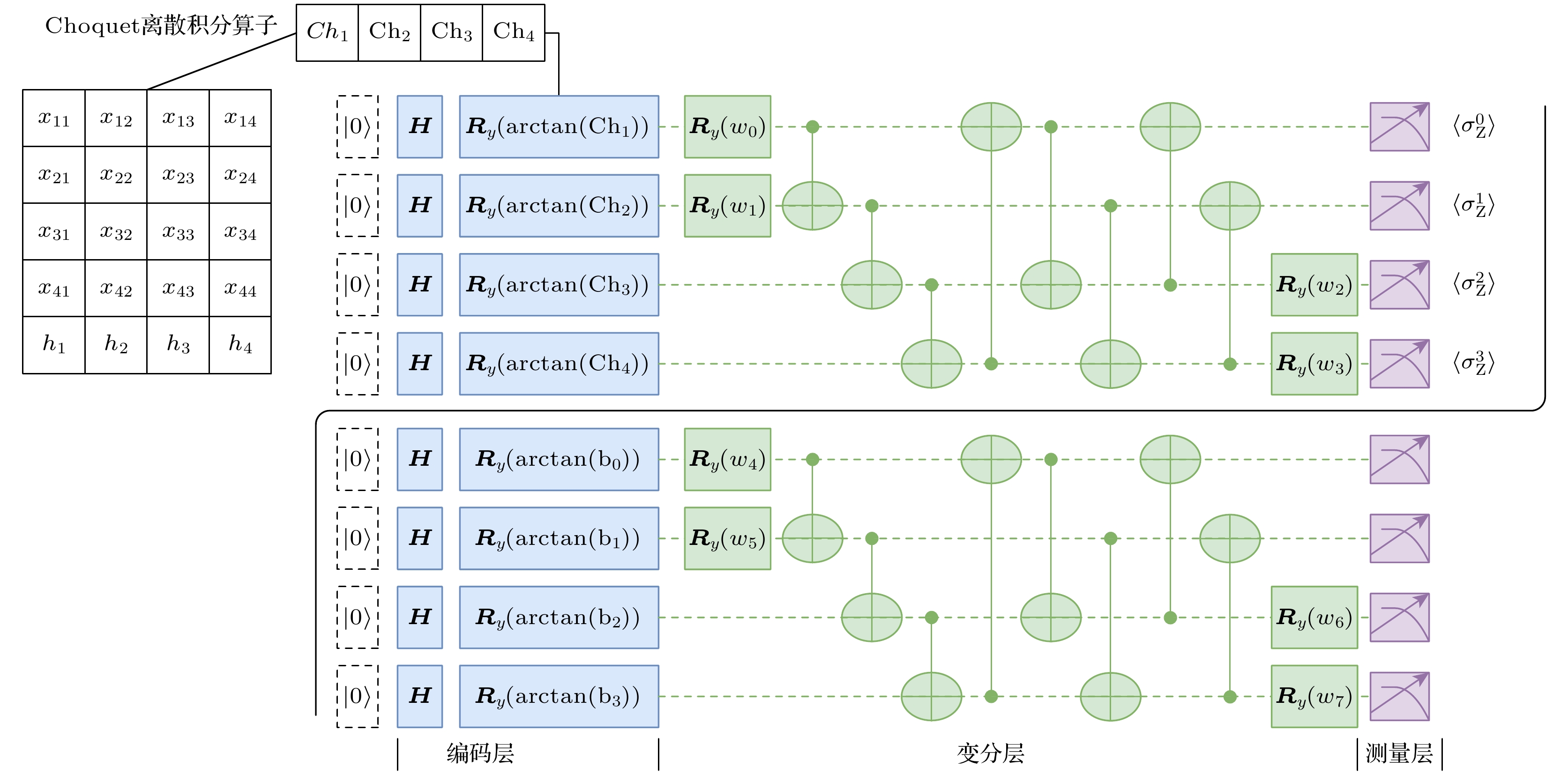
长短期记忆(long-short term memory, LSTM)神经网络通过引入记忆单元来解决长期依赖、梯度消失和梯度爆炸问题, 广泛应用于时间序列分析与预测. 将量子计算与LSTM神经网络结合将有助于提高其计算效率并降低模型参数个数, 从而显著改善传统LSTM神经网络的性能. 本文提出一种可用于图像分类的混合量子LSTM (hybrid quantum LSTM, HQLSTM)网络模型, 利用变分量子电路代替经典LSTM网络中的神经细胞, 以实现量子网络记忆功能, 同时引入Choquet离散积分算子来增强数据之间的聚合程度. HQLSTM网络中的记忆细胞由多个可实现不同功能的变分量子电路(variation quantum circuit, VQC)构成, 每个VQC由三部分组成: 编码层利用角度编码降低网络模型设计的复杂度; 变分层采用量子自然梯度优化算法进行设计, 使得梯度下降方向不以特定参数为目标, 从而优化参数更新过程, 提升网络模型的泛化性和收敛速度; 测量层利用泡利 Z 门进行测量, 并将测量结果的期望值输入到下一层实现对量子电路中有用信息的提取. 在MNIST, FASHION-MNIST和CIFAR数据集上的图像分类实验结果表明, 与经典LSTM、量子LSTM相比, HQLSTM模型获得了较高的图片分类精度和较低的损失值. 同时, HQLSTM、量子LSTM网络空间复杂度相较于经典的LSTM网络实现了明显的降低.
-
关键词:
- 量子神经网络 /
- 变分量子电路 /
- 混合量子长短期记忆神经网络
Long-short term memory (LSTM) neural network solves the problems of long-term dependence, gradient disappearance and gradient explosion by introducing memory units, and is widely used in time series analysis and prediction. Combining quantum computing with LSTM neural network will help to improve its computational efficiency and reduce the number of model parameters, thus significantly improving the performance of traditional LSTM neural network. This paper proposes a hybrid quantum LSTM (hybrid quantum long-short term memory, HQLSTM) network model that can be used to realize the image classification. It uses variable quantum circuits to replace the nerve cells in the classical LSTM network to realize the memory function of the quantum network. At the same time, it introduces Choquet integral operator to enhance the degree of aggregation between data. The memory cells in the HQLSTM network are composed of multiple variation quantum circuits (VQC) that can realize different functions. Each VQC consists of three parts: the coding layer, which uses angle coding to reduce the complexity of network model design; the variation layer, which is designed with quantum natural gradient optimization algorithm, so that the gradient descent direction does not target specific parameters, thereby optimizing the parameter update process and improving the generalization and convergence speed of the network model; the measurement layer, which uses the Pauli Z gate to measure, and the expected value of the measurement result is input to the next layer to extract useful information from the quantum circuit. The experimental results on the MNIST, FASHION-MNIST and CIFAR datasets show that the HQLSTM model achieves higher image classification accuracy and lower loss value than the classical LSTM model and quantum LSTM model. At the same time, the network space complexity of HQLSTM and quantum LSTM are significantly reduced compared with the classical LSTM network.-
Keywords:
- quantum neural networks /
- variational quantum circuits /
- hybrid quantum long short-term memory neural networks
[1] Acharya U R, Oh S L, Hagiwara Y, HongTan J, Adam M, Gertych A, Tan R S 2017 Comput. Biol. Med. 89 389
 Google Scholar
Google Scholar
[2] Hage S R, Nieder A 2016 Trends Neurosci. 39 813
Google Scholar
[3] Xu S, Liu K, Li X G 2019 Neurocomputing 335 1
Google Scholar
[4] Zhao J, Yang S P, Li Q, Liu Y Q, Gu X H, Liu W P 2021 Measurement 176 109088
Google Scholar
[5] Feng X C, Qin B, Liu T 2018 Sci. China Inf. Sci. 61 092106
Google Scholar
[6] Tsai S T, Kuo E J, Tiwary P 2020 Nat. Commun. 11 5115
Google Scholar
[7] Yadav S S, Jadhav S M 2019 J. Big Data 6 96
Google Scholar
[8] Yan R, Ren F, Wang Z H, Wang L H, Zhang T, Liu Y D, Rao X S, Zheng C H, Zhang F 2020 Methods 173 52
Google Scholar
[9] Xin M, Wang Y 2019 EURASIP J. Image Video Process. 2019 40
Google Scholar
[10] Steane A 1998 Rep. Prog. Phys. 61 117
Google Scholar
[11] Gyongyosi L, Imre S 2019 Comput. Sci. Rev. 31 51
Google Scholar
[12] Egger D J, Gambella C, Marecek J, McFaddin S, Mevissen M, Raymond R, Simonetto A, Woerner S, Yndurain E 2020 IEEE Trans. Quantum Eng. 1 3101724
Google Scholar
[13] Wu N, Song F M 2007 Front. Comput. Sci. 1 1
Google Scholar
[14] He K Y, Geng X, Huang R T, Liu J S, Chen W 2021 Chin. Phys. B 30 080304
Google Scholar
[15] Harrow A W, Hassidim A, Lloyd S 2009 Phys. Rev. Lett. 103 150502
Google Scholar
[16] Grover L K 2005 Phys. Rev. Lett. 95 150501
Google Scholar
[17] Yoder T J, Low G H, Chuang I L 2014 Phys. Rev. Lett. 113 210501
Google Scholar
[18] Kouda N, Matsui N, Nishimura H, Peper F 2005 Neural Comput. Appl. 14 114
Google Scholar
[19] Li P C, Xiao H, Shang F H, Tong X F, Li X, Cao M J 2013 Neurocomputing 117 81
Google Scholar
[20] Li P C, Xiao H 2013 Neural Process. Lett. 40 143
[21] Zhou R G, Ding Q L 2007 Int. J. Theor. Phys. 46 3209
Google Scholar
[22] Cong I, Choi S, Lukin M D 2019 Nat. Phys. 15 1273
Google Scholar
[23] Henderson M, Shakya S, Pradhan S, Cook T 2020 Quantum Mach. Intell. 2 1
Google Scholar
[24] Niu X F, Ma W P 2021 Laser Phys. Lett. 18 025201
Google Scholar
[25] Houssein E H, Abohashima Z, Elhoseny M, Mohamed W M 2022 J. Comput. Des. Eng. 9 343
[26] Hur T, Kim L, Park D K 2022 Quantum Mach. Intell. 4 1
Google Scholar
[27] Chen G M, Chen Q, Long S, Zhu W H, Yuan Z D, Wu Y L 2022 Pattern Anal. Applic. 25 1
Google Scholar
[28] Xia R, Kais S 2020 Entropy 22 828
Google Scholar
[29] Mari A, Bromley T R, Izaac J, Schuld M, Killoran N 2020 Quantum 4 340
Google Scholar
[30] Yu Y, Si X S, Hu C H, Zhang J X 2019 Neural Comput. 31 1235
Google Scholar
[31] Shewalkar A 2019 J. Artif. Intell. Soft 9 235
[32] Hua Y, Mou L, Zhu X X 2019 ISPRS J. Photogramm. Remote Sens. 149 188
Google Scholar
[33] Takáč Z, Ferrero-Jaurrieta M, Horanská Ľ, Krivoňáková N, Dimuro G. P, Bustince H 2021 2021 International Conference on Electrical, Computer and Energy Technologies (ICECET) Malaysia, Kuala Lumpur, June 12–13, 2021 p1
[34] Ma A, Filippi A. M, Wang Z, Yin Z 2019 Remote Sens. 11 194
Google Scholar
[35] Chen S Y C, Yoo S, Fang Y L L 2022 2022 IEEE International Conference on Acoustics, Speech and Signal Processing Singapore May 22–27, 2022 p8622
[36] Stokes J, Izaac J, Killoran N, Carleo G 2020 Quantum 4 269
Google Scholar
[37] Wiebe N 2020 New J. Phys. 22 091001
Google Scholar
[38] Wei S J, Chen Y H, Zhou Z R, Long G L 2022 AAPPS Bull. 32 1
Google Scholar
[39] 赵娅, 郭嘉慧, 李盼池 2021 电子与信息学报 43 204
Google Scholar
Zhao Y, Guo J H, Li P C 2021 J. Electron. Inf. Techn. 43 204
Google Scholar
[40] Watson T F, Philips S G J, Kawakami E, Ward D R, Scarlino P, Veldhorst M, Savage D E, Lagally M G, Friesen M, Coppersmith S N, Eriksson M A, Vandersypen L M K 2018 Nature 555 633
Google Scholar
[41] Chew Y, Tomita T, Mahesh T P, Sugawa S, Léséleuc S D, Ohmori K 2022 Nat. Photonics. 16 724
Google Scholar
[42] 杨靖北, 丛爽, 陈鼎 2017 控制理论与应用 34 15144
Google Scholar
Yang J B, Cong S, Chen D 2017 J. Control Theory Appl. 34 15144
Google Scholar
[43] Gokhale P, Angiuli O, Ding Y, Gui K, Tomesh T, Suchara M, Martonosi M, Chong F T 2020 IEEE Trans. Quantum Eng. 1 1
Google Scholar
[44] Huang H Y, Kueng R, Preskill J 2021 Phys. Rev. Lett. 126 190505
Google Scholar
-
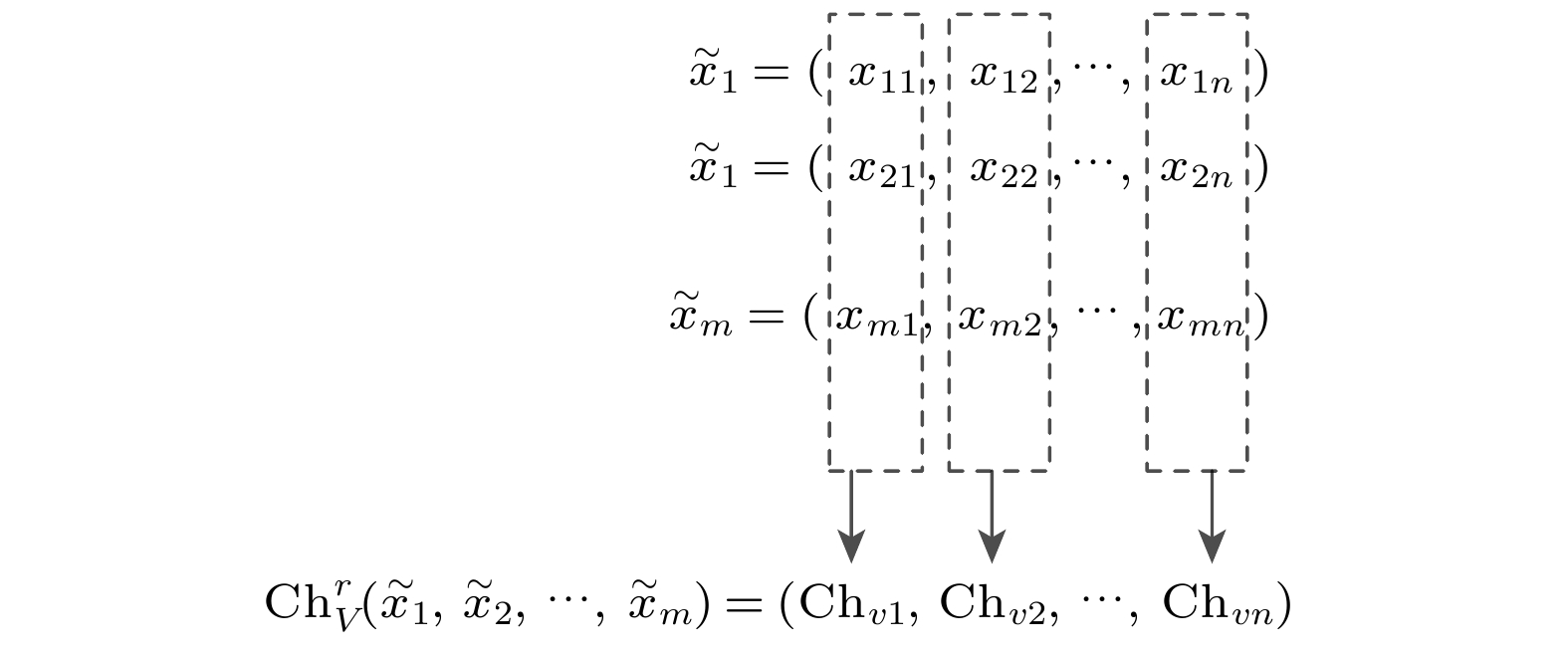
图 2 二维的Choquet离散积分算子图示
Fig. 2. Two-dimensional Choquet discrete integral operator diagram.
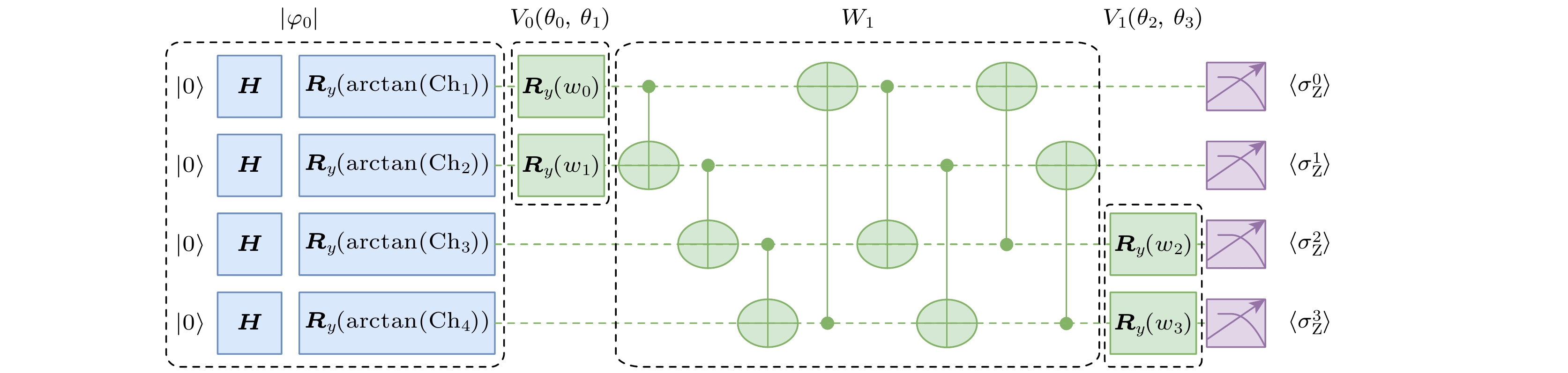
图 5 计算Fubini-Study度量张量的部分VQC结构
Fig. 5. Calculate part of the VQC structure of the Fubini-Study metric tensor.

图 6 数据集样本 (a) MNIST数据集; (b) FASHION-MNIST数据集; (c) CIFAR数据集
Fig. 6. Dataset image samples: (a) MNIST dataset; (b) FASHION_MNIST dataset; (c) CIFAR dataset.
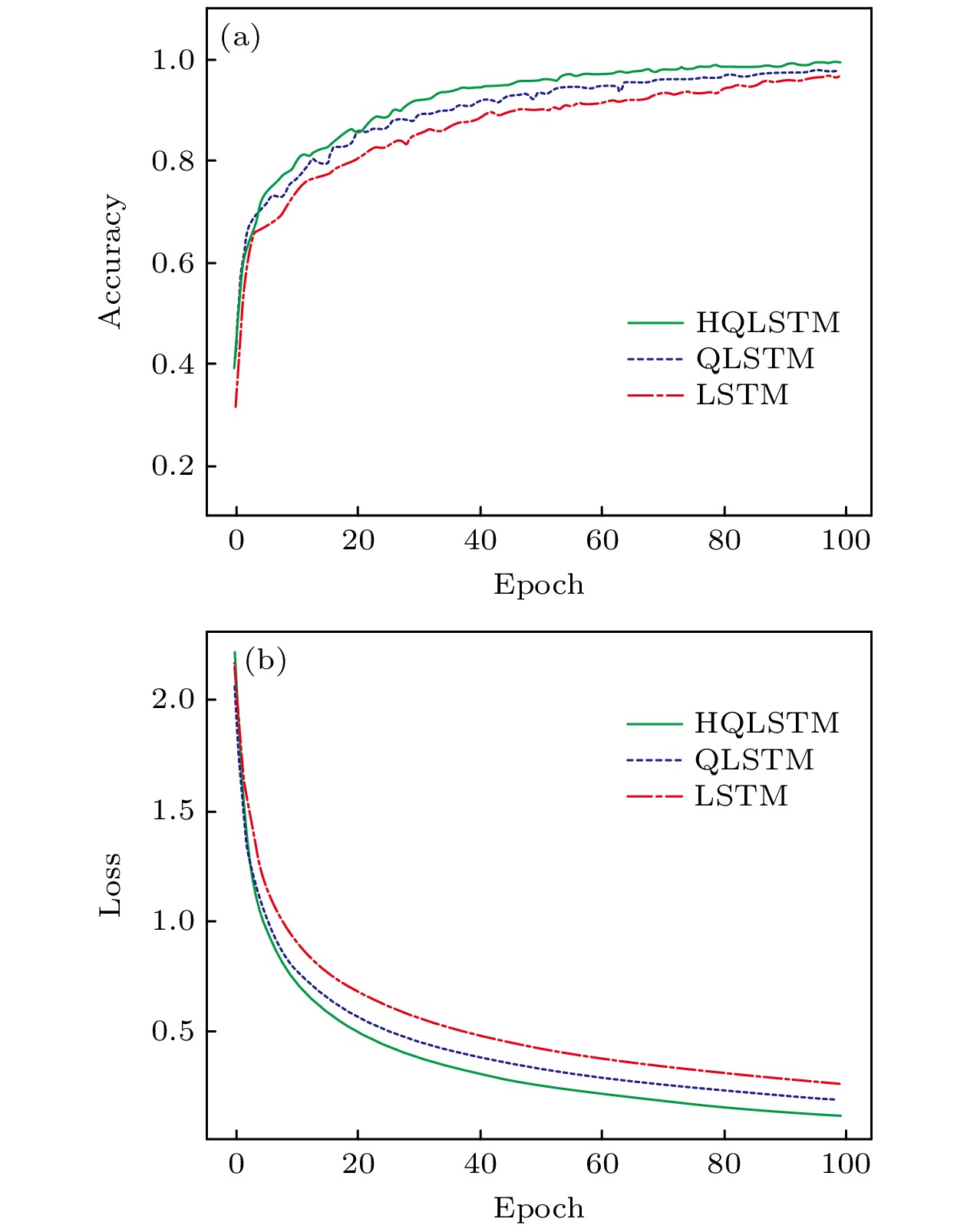
图 7 MNIST数据集 (a)分类精度对比; (b)损失函数值对比
Fig. 7. MNIST dataset: (a) Comparison of classification accuracy; (b) comparison of loss value.

图 8 不同优化算法损失值对比
Fig. 8. Comparison of loss values of different optimization algorithms.
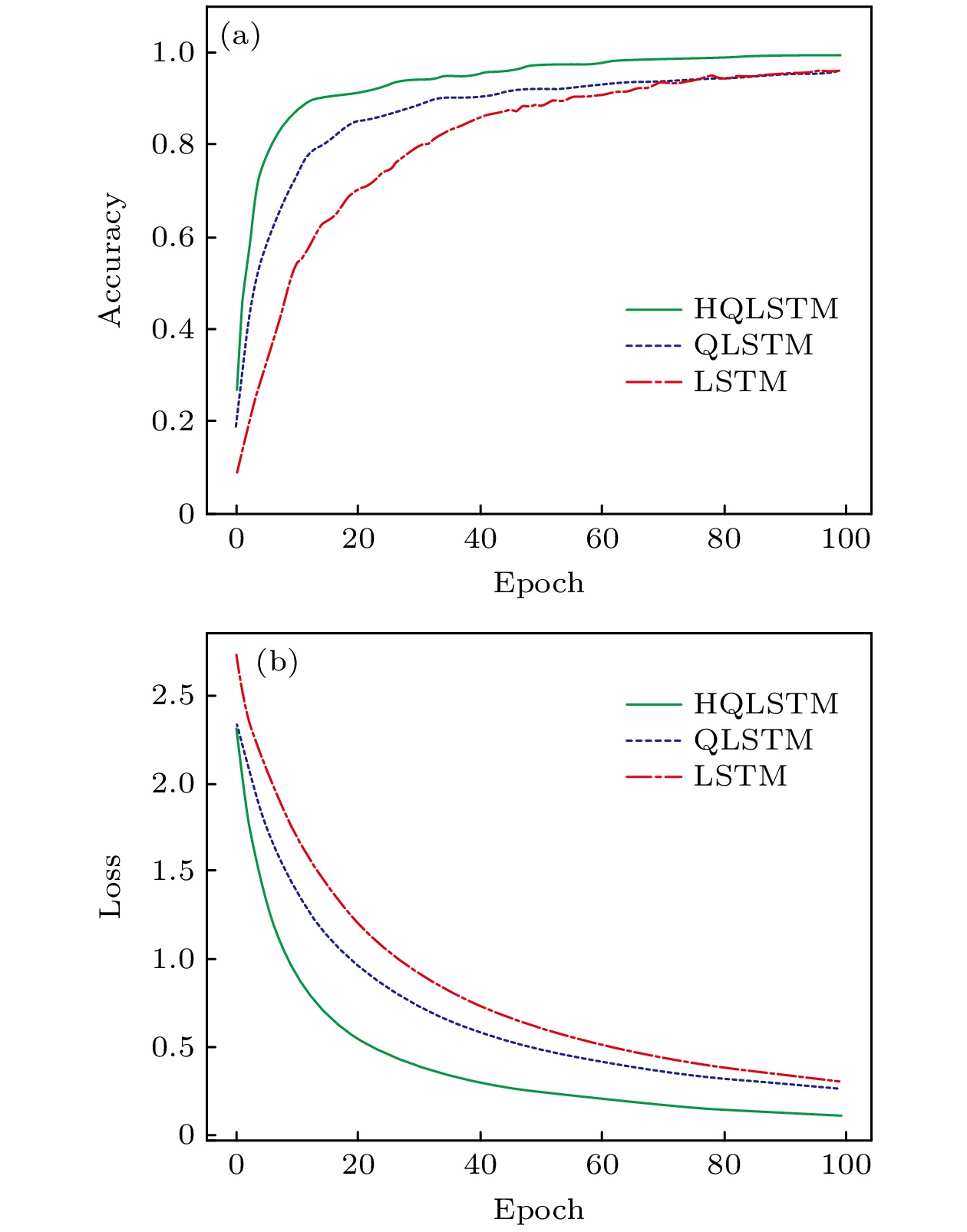
图 9 FASHION-MNIST数据集 (a) 分类精度对比; (b) 损失函数值对比
Fig. 9. FASHION-MNIST dataset: (a) Comparison of classification accuracy; (b) comparison of loss value
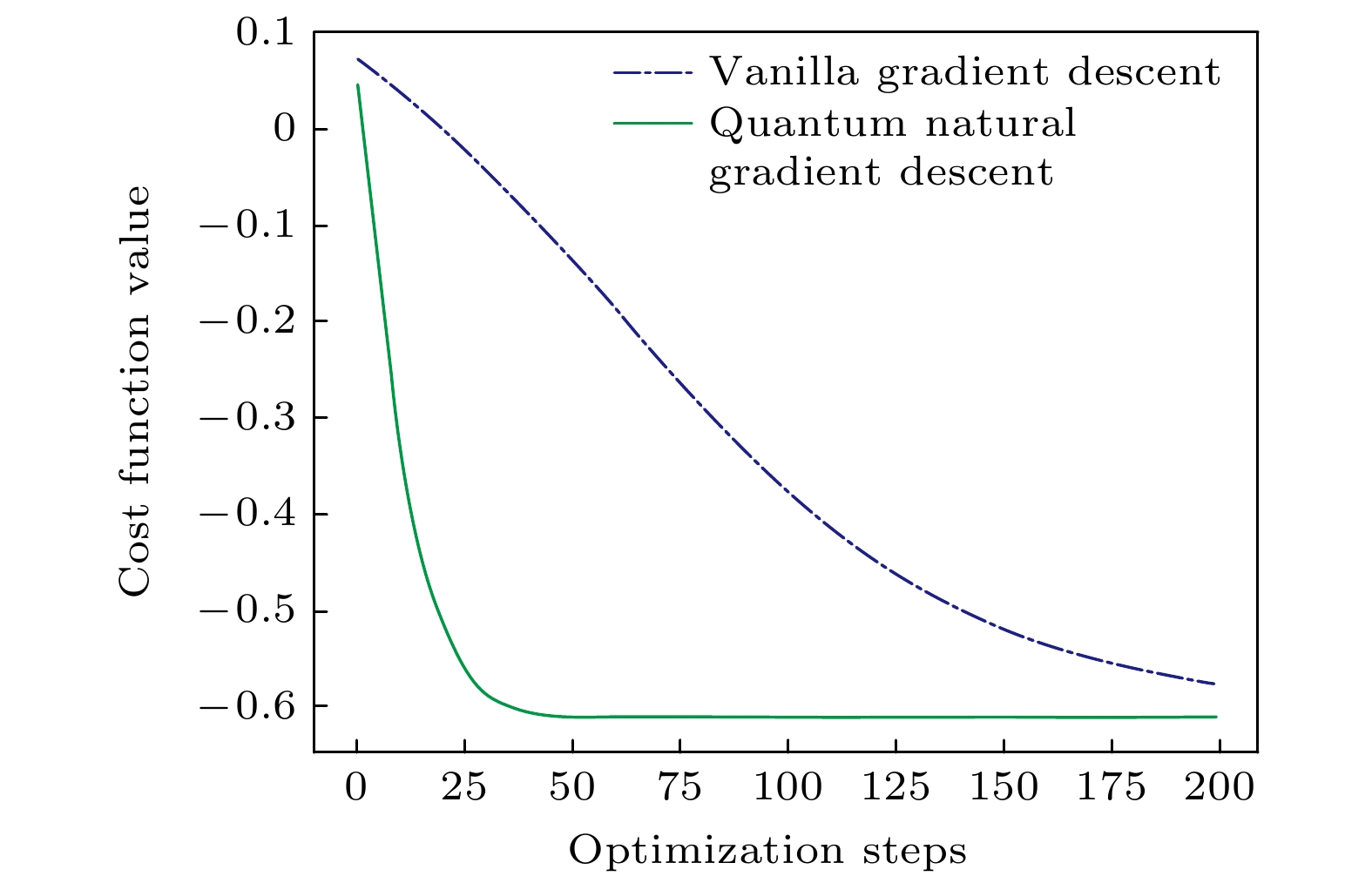
图 10 不同优化算法损失值对比
Fig. 10. Comparison of loss values of different optimization algorithms.
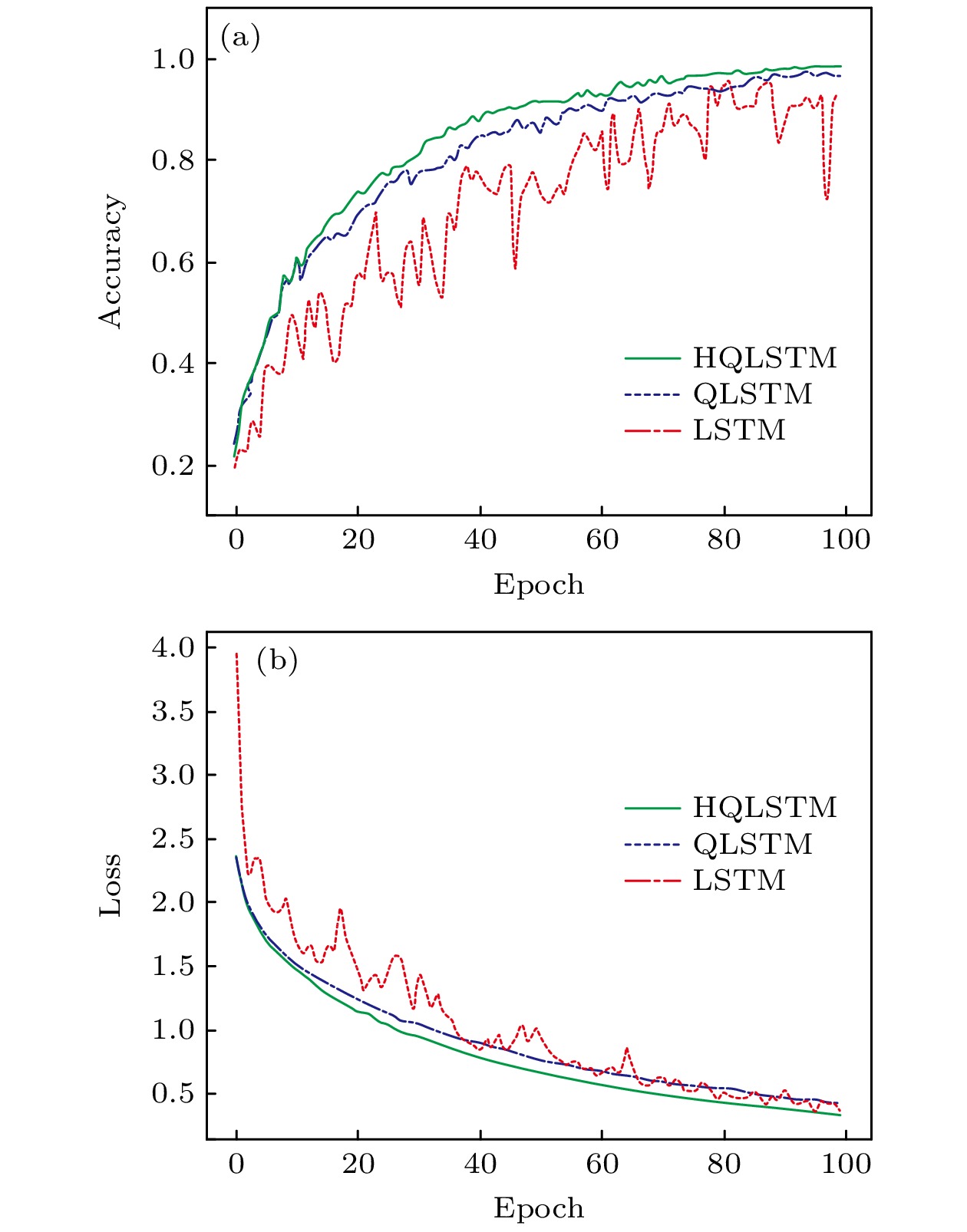
图 11 CIFAR彩色数据集 (a)分类精度对比; (b)损失函数值对比
Fig. 11. CIFAR color dataset: (a) Classification accuracy; (b) comparison of loss value.
表 1 LSTM网络模型参数
Table 1. LSTM network model parameters.
参数 数量 Input_size 4 Hidden_size 4 Time_step 49 Dropout比率 0.15 Batch 128 网络层数 2 输出节点数 10 学习率 0.001  下载: 导出CSV
下载: 导出CSV
表 2 QLSTM和HQLSTM网络模型参数
Table 2. QLSTM and HQLSTM network model parameters.
参数 数量 输入量子比特数 4 Hidden_size 4 Time_step 49 Dropout比率 0.15 Batch 128 网络层数 2 输出节点数 10 学习率 0.001
下载: 导出CSV
-
[1] Acharya U R, Oh S L, Hagiwara Y, HongTan J, Adam M, Gertych A, Tan R S 2017 Comput. Biol. Med. 89 389
Google Scholar
[2] Hage S R, Nieder A 2016 Trends Neurosci. 39 813
Google Scholar
[3] Xu S, Liu K, Li X G 2019 Neurocomputing 335 1
Google Scholar
[4] Zhao J, Yang S P, Li Q, Liu Y Q, Gu X H, Liu W P 2021 Measurement 176 109088
Google Scholar
[5] Feng X C, Qin B, Liu T 2018 Sci. China Inf. Sci. 61 092106
Google Scholar
[6] Tsai S T, Kuo E J, Tiwary P 2020 Nat. Commun. 11 5115
Google Scholar
[7] Yadav S S, Jadhav S M 2019 J. Big Data 6 96
Google Scholar
[8] Yan R, Ren F, Wang Z H, Wang L H, Zhang T, Liu Y D, Rao X S, Zheng C H, Zhang F 2020 Methods 173 52
Google Scholar
[9] Xin M, Wang Y 2019 EURASIP J. Image Video Process. 2019 40
Google Scholar
[10] Steane A 1998 Rep. Prog. Phys. 61 117
Google Scholar
[11] Gyongyosi L, Imre S 2019 Comput. Sci. Rev. 31 51
Google Scholar
[12] Egger D J, Gambella C, Marecek J, McFaddin S, Mevissen M, Raymond R, Simonetto A, Woerner S, Yndurain E 2020 IEEE Trans. Quantum Eng. 1 3101724
Google Scholar
[13] Wu N, Song F M 2007 Front. Comput. Sci. 1 1
Google Scholar
[14] He K Y, Geng X, Huang R T, Liu J S, Chen W 2021 Chin. Phys. B 30 080304
Google Scholar
[15] Harrow A W, Hassidim A, Lloyd S 2009 Phys. Rev. Lett. 103 150502
Google Scholar
[16] Grover L K 2005 Phys. Rev. Lett. 95 150501
Google Scholar
[17] Yoder T J, Low G H, Chuang I L 2014 Phys. Rev. Lett. 113 210501
Google Scholar
[18] Kouda N, Matsui N, Nishimura H, Peper F 2005 Neural Comput. Appl. 14 114
Google Scholar
[19] Li P C, Xiao H, Shang F H, Tong X F, Li X, Cao M J 2013 Neurocomputing 117 81
Google Scholar
[20] Li P C, Xiao H 2013 Neural Process. Lett. 40 143
[21] Zhou R G, Ding Q L 2007 Int. J. Theor. Phys. 46 3209
Google Scholar
[22] Cong I, Choi S, Lukin M D 2019 Nat. Phys. 15 1273
Google Scholar
[23] Henderson M, Shakya S, Pradhan S, Cook T 2020 Quantum Mach. Intell. 2 1
Google Scholar
[24] Niu X F, Ma W P 2021 Laser Phys. Lett. 18 025201
Google Scholar
[25] Houssein E H, Abohashima Z, Elhoseny M, Mohamed W M 2022 J. Comput. Des. Eng. 9 343
[26] Hur T, Kim L, Park D K 2022 Quantum Mach. Intell. 4 1
Google Scholar
[27] Chen G M, Chen Q, Long S, Zhu W H, Yuan Z D, Wu Y L 2022 Pattern Anal. Applic. 25 1
Google Scholar
[28] Xia R, Kais S 2020 Entropy 22 828
Google Scholar
[29] Mari A, Bromley T R, Izaac J, Schuld M, Killoran N 2020 Quantum 4 340
Google Scholar
[30] Yu Y, Si X S, Hu C H, Zhang J X 2019 Neural Comput. 31 1235
Google Scholar
[31] Shewalkar A 2019 J. Artif. Intell. Soft 9 235
[32] Hua Y, Mou L, Zhu X X 2019 ISPRS J. Photogramm. Remote Sens. 149 188
Google Scholar
[33] Takáč Z, Ferrero-Jaurrieta M, Horanská Ľ, Krivoňáková N, Dimuro G. P, Bustince H 2021 2021 International Conference on Electrical, Computer and Energy Technologies (ICECET) Malaysia, Kuala Lumpur, June 12–13, 2021 p1
[34] Ma A, Filippi A. M, Wang Z, Yin Z 2019 Remote Sens. 11 194
Google Scholar
[35] Chen S Y C, Yoo S, Fang Y L L 2022 2022 IEEE International Conference on Acoustics, Speech and Signal Processing Singapore May 22–27, 2022 p8622
[36] Stokes J, Izaac J, Killoran N, Carleo G 2020 Quantum 4 269
Google Scholar
[37] Wiebe N 2020 New J. Phys. 22 091001
Google Scholar
[38] Wei S J, Chen Y H, Zhou Z R, Long G L 2022 AAPPS Bull. 32 1
Google Scholar
[39] 赵娅, 郭嘉慧, 李盼池 2021 电子与信息学报 43 204
Google Scholar
Zhao Y, Guo J H, Li P C 2021 J. Electron. Inf. Techn. 43 204
Google Scholar
[40] Watson T F, Philips S G J, Kawakami E, Ward D R, Scarlino P, Veldhorst M, Savage D E, Lagally M G, Friesen M, Coppersmith S N, Eriksson M A, Vandersypen L M K 2018 Nature 555 633
Google Scholar
[41] Chew Y, Tomita T, Mahesh T P, Sugawa S, Léséleuc S D, Ohmori K 2022 Nat. Photonics. 16 724
Google Scholar
[42] 杨靖北, 丛爽, 陈鼎 2017 控制理论与应用 34 15144
Google Scholar
Yang J B, Cong S, Chen D 2017 J. Control Theory Appl. 34 15144
Google Scholar
[43] Gokhale P, Angiuli O, Ding Y, Gui K, Tomesh T, Suchara M, Martonosi M, Chong F T 2020 IEEE Trans. Quantum Eng. 1 1
Google Scholar
[44] Huang H Y, Kueng R, Preskill J 2021 Phys. Rev. Lett. 126 190505
Google Scholar

 下载:
下载:
计量
- 文章访问数: 8331
- PDF下载量: 144
- 被引次数: 0
