










-
在线社交网络逐渐成为人们不可或缺的重要工具, 识别网络中具有高影响力的节点作为初始传播源, 在社会感知与谣言控制等方面具有重要意义. 本文基于独立级联模型, 给出了一个描述有限步传播范围期望的指标—传播度, 并设计了一种高效的递推算法. 该指标在局部拓扑结构信息的基础上融合了传播概率对影响力进行刻画, 能够较好地反映单个节点的传播影响力. 对于多传播源影响力极大化问题, 本文提出了一种基于传播度的启发式算法—传播度折扣算法, 使得多个传播源的联合影响力最大. 最后, 将上述方法应用到三个真实网络中, 与经典指标和方法相比, 该方法不需要知道网络的全局结构信息, 而是充分了利用网络的局部结构信息, 可以较快地筛选出高传播影响力的传播源.On-line social networks have gradually become an indispensable tool for people. Identifying nodes with high influence in the network as an initial source of communication is of great significance in social perception and rumor control. According to the independent cascade model, in this paper we present an index describing the finite step propagation range expectation as the degree of propagation, and design an efficient recursive algorithm. Based on the local topology information, the index combines the propagation probability to characterize the influence, which can better reflect the propagation influence of a single node. For a single propagation source influence ordering problem, the node degree of propagation and propagation capability are better consistent with each other. And the propagation degree can well describe the propagation influence of nodes under different networks and propagation probabilities. For maximizing the multi-propagation source influence, in this paper we propose a propagation-based heuristic algorithm which is called propagation discount algorithm. This algorithm makes the joint influence of multiple propagation sources maximized. Finally, in this paper we apply the above method to three real networks, showing better effects than the classic indicators and methods. The algorithm has three advantages. First, the expected value of the final propagation range of each node in the small network can be accurately calculated. Second, the degree of propagation fully considers the local topology of the node and belongs to a locality indicator. Third, the indicator combines the effect of propagation probability and yields good outcomes under different networks and propagation probabilities.
-
Keywords:
- social network /
- influence measurement /
- influence maximization /
- information dissemination
[1] Fershtman M 1997 Soc. Networks 19 193
[2] Chen D B, Lu L Y, Shang M S, Zhang Y C, Zhou T 2012 Physica A 391 1777
[3] Freeman L C 1977 Sociometry 40 35
 Google Scholar
Google Scholar
[4] Bavelas A 1950 J. Acoust. Soc. Am. 22 725
Google Scholar
[5] Dabbousi B O, Rodriguez-Viejo J, Mikulec F V, Heine J R, Mattoussi H, Ober R, Jensen K F, Bawendi M G 1997 J. Phys. Chem. B 101 9463
[6] 闵磊, 刘智, 唐向阳 2015 物理学报 64 088901
Min L, Liu Z, Tang X Y 2015 Acta Phys. Sin. 64 088901
[7] Domingos P, Richardson M 2001 Proceedings of KDD'01 ACM SIG KDD International Conference on Knowledge Discovery and Data Mining San Francisco, CA, USA, August 26−29, 2001 p57
[8] Kempe D, Kleinberg J, Tardos E 2003 Proc. 9th ACM SIGKDD Intl. Conf. On Knowledge Discovery and Data Mining New Washington, DC, USA, August 24−27, 2003 p137
[9] Leskovec J, Krause A, Guestrin C, Faloutsos C, VanBriesen J, Glance N 2007 Proc. 13 th ACM SIGKDD Intl. Conf. on Knowledge Discovery and Data Mining USA, August 24−27, 2007 p420
[10] Chen W, Wang Y, Yang S 2009 Proc. 15th ACM SIGKDD Intl. Conf. on Knowledge discovery and data mining Paris, France, June 28−July 1, 2009 p199
[11] Sheikhahmadi A, Nematbakhsh M A, Shokrollahi A 2015 Physica A 436 833
[12] Kimura M, Saito K 2006 Knowledge-Based Intelligent Information and Engineering Systems: 10th international conference Bournemouth, UK, October 9−11, 2006 p259
[13] Chen W, Wang C, Wang Y 2010 Proc. 16th ACM SIGKDD Intl. Conf. on Knowledge discovery and data mining WashingtonDC, USA, July 25−28, 2010 p1029
[14] Wang Y, Cong G, Song G 2010 Proc. 16th ACM SIGKDD Intl. Conf. on Knowledge discovery and mining Washington DC, USA, July 25−28, 2010 p1039
[15] Li D, Xu Z M, Chakraborty N 2014 PloS One 9 e102199
Google Scholar
[16] Hu Y Q, Ji S G, Jin Y L, Feng L, Stanley H E, Havlin S 2018 PNAS 115 7468
Google Scholar
[17] Lancichinetti A, Fortunato S 2009 Phys. Rev. E 80 056117
[18] Leskovec J, Lang K, Dasgupta A, Mahoney M W 2009 Internet Mathematics 6 29
Google Scholar
[19] Lapata M 2006 Comput. Linguist. 32 471
Google Scholar
[20] Kitsak M, Gallos L K, Havlin S, Liljeros F, Muchnik L, Stanley H E, Makse H A 2010 Nat. Phys. 6 888
Google Scholar
-

图 1 一个简单网络例子 (a)网络图; (b)图(a)对应的传播树
Fig. 1. A simple network example: (a) The network diagram; (b) the corresponding propagation tree of (a).

图 2 (a)不同仿真次数下的近似传播期望值和传播度随时间的变化; (b)不同仿真次数的近似传播期望值与传播度的方差变化
Fig. 2. (a) Approximate propagation expectation and the degree of propagation over time for different simulation times; (b) variance of the approximate propagation expectation and the degree of propagation of different simulation times.

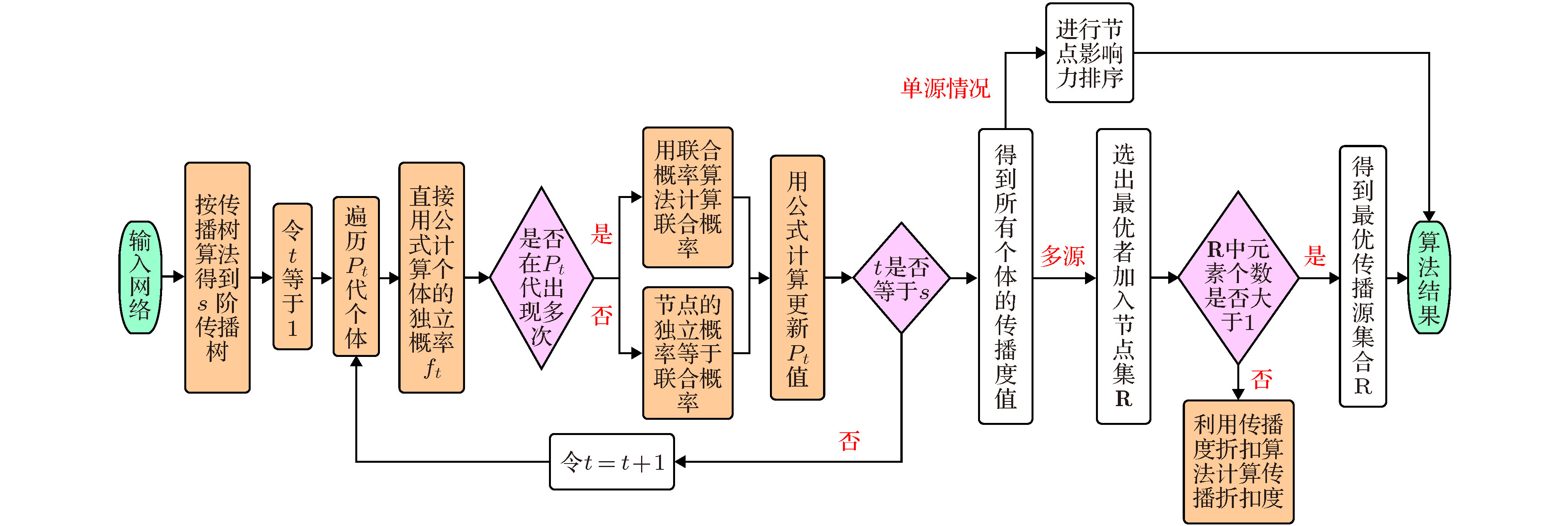
图 4 基于传播度的节点影响力极大化算法流程图
Fig. 4. Flow chart of node influence maximization algorithm based on propagation degree.
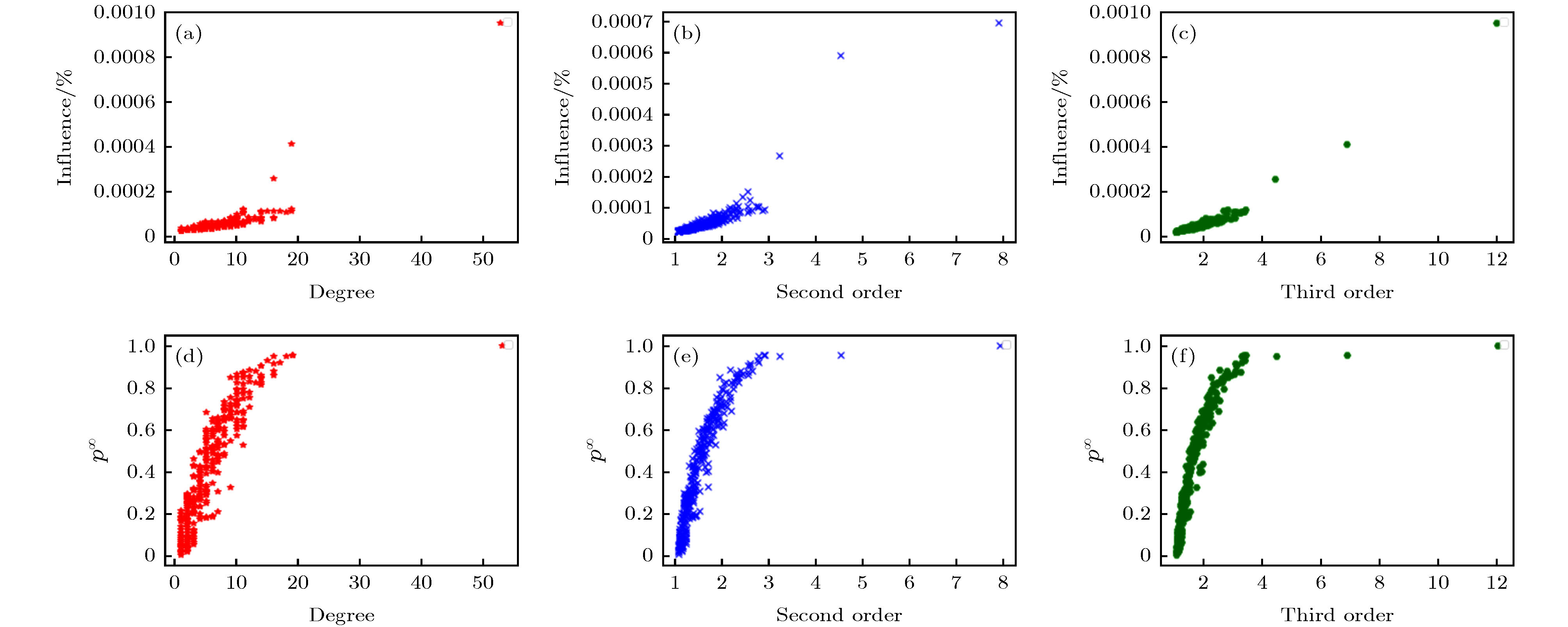
图 5 (a)−(c) 分别反映了Deezer网络随机挑选若干节点的传播能力与度, 二阶传播度, 三阶传播度的关系, 其中β = 0.06; (d)−(f) 分别反映了Deezer网络随机挑选若干节点全局传播概率(参见文献[12])与度, 二阶传播度, 三阶传播度的对应情况, 其中β = 0.12(这里通过仿真实验不难发现该网络的渗流阈值介于0.06和0.12之间)
Fig. 5. (a)−(c): Respectively reflects the relationship between the propagation capacity and degree, second-order propagation, and third-order propagation of several nodes randomly selected by the Deezer network, where β = 0.06; (d)−(f): Respectively reflects the global propagation probability of randomly selected nodes by the Deezer network (see reference[12]) Correspondence with degrees, second-order propagation, and third-order propagation, where β = 0.12 (here, it is not difficult to find through the simulation experiments that the percolation threshold of the network is between 0.06 and 0.12)
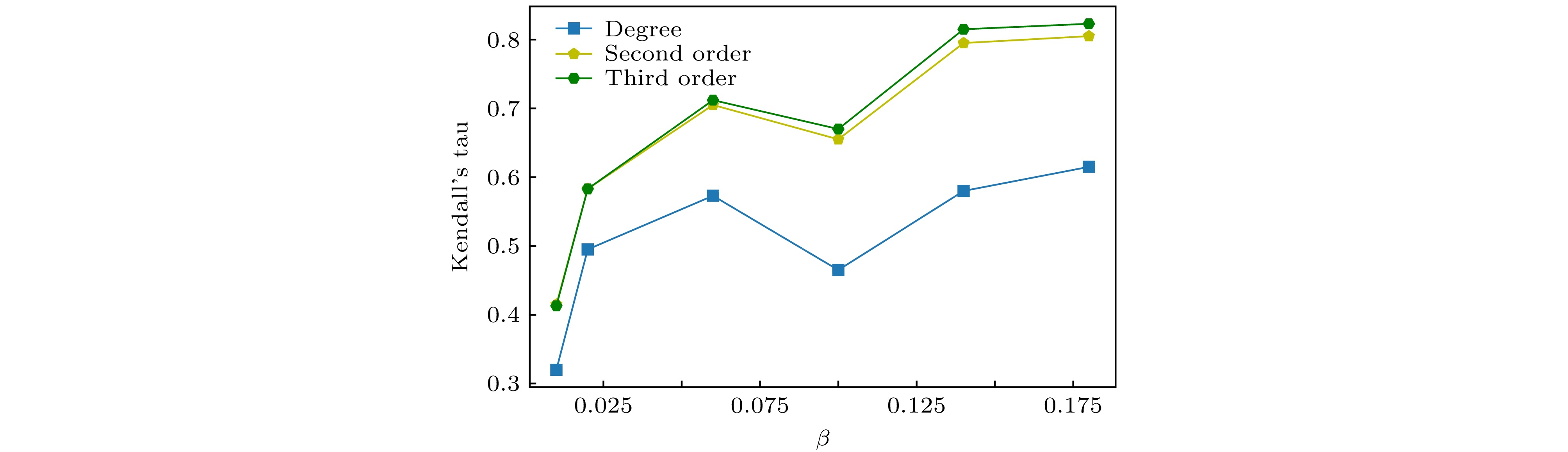
图 6 不同传播概率下度, 二阶、三阶传播度与仿真传播能力的kendall’s tau系数
Fig. 6. Kendall’s tau coefficient for different propagation probabilities, second-order, third-order propagation and simulation propagation ability.
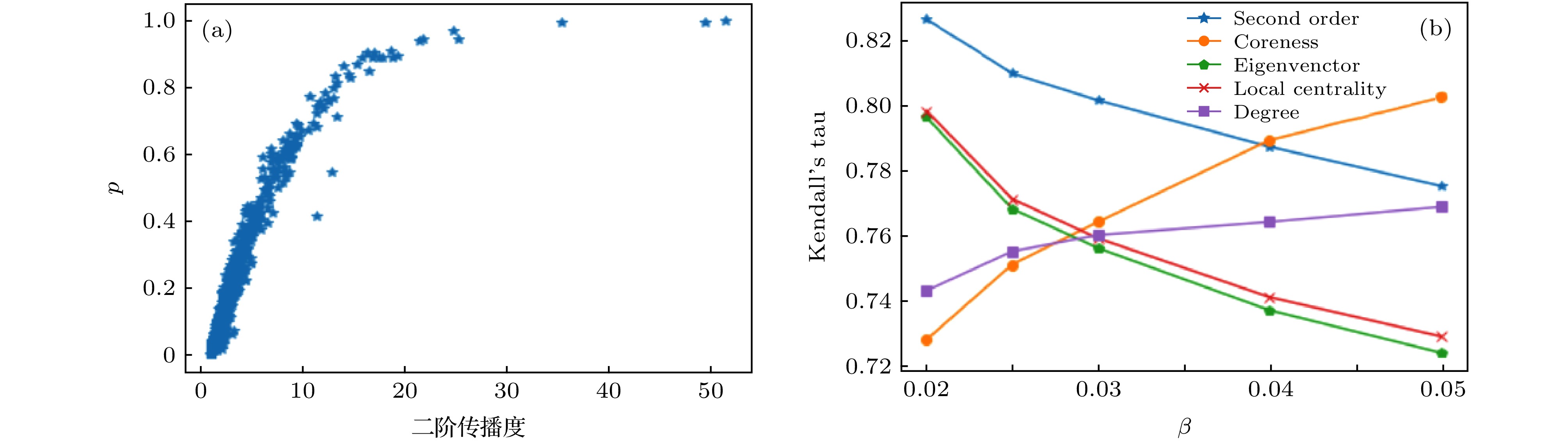
图 7 (a)在Email-Enron网络中, 传播概率为0.02的情况下二阶传播度和全局传播概率p的关系; (b)各指标在不同概率下与传播能力的kendall’s tau系数
Fig. 7. (a) The relationship between the second-order propagation degree and the global propagation probability p in the case of the Email-Enron network with a propagation probability of 0.02; (b) the kendall's tau coefficient of each indicator with different propagation rates and propagation capabilities.

图 8 (a)在Facebook网络中, 传播概率为0.09的情况下二阶传播度和全局传播概率p的关系; (b)各指标在不同概率下与传播能力的kendall’s tau系数
Fig. 8. (a) The relationship between the second-order propagation degree and the global propagation probability p in the case of a Facebook network with a propagation probability of 0.09; (b) the kendall's tau coefficient of each indicator with different propagation rates and propagation capabilities.
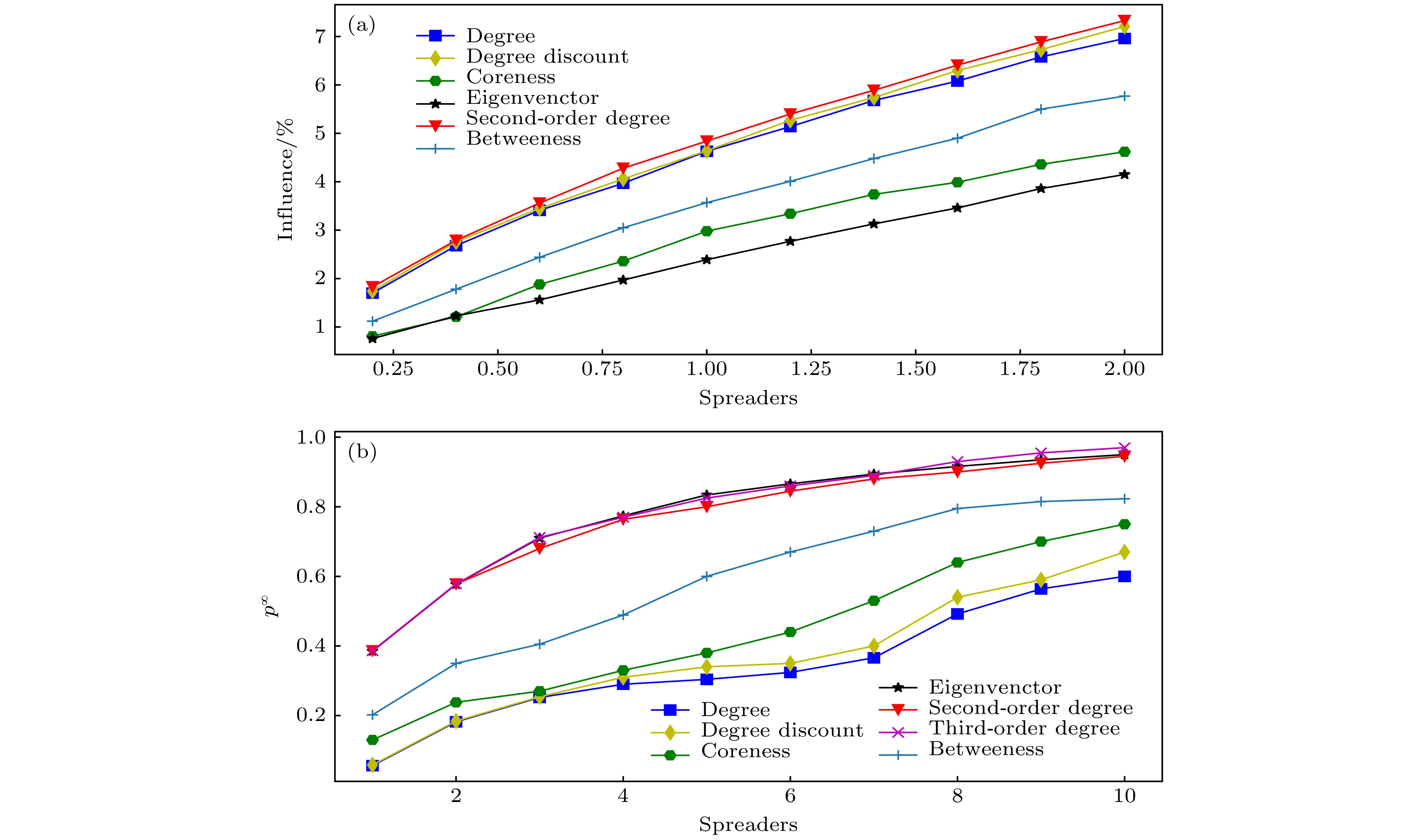
图 9 在Deezer网络中(a)不同算法下传播范围随所选种子节点数量的变化和(b)不同算法下全局传播概率随种子节点数量的变化, 其中候选节点为度为6, 7, 8的9792个节点
Fig. 9. In the Deezer network, (a) the variation of the propagation range with the number of selected seed nodes under different algorithms; (b) the variation of the global propagation probability with the number of seed nodes under different algorithms. The candidate nodes are 9792 nodes with a degree of 6, 7 and 8.

图 10 (a), (b)和(c), (d)分别比较了Email-Enron, Facebook网络在不同算法下所选种子节点的传播性能
Fig. 10. (a), (b), and (c), (d), respectively, compare the propagation performance of Email-Enron, the selected seed node of the Facebook network under different algorithms.
表 1 联合概率算法
Table 1. Joint probability algorithm
辅助算法二 联合概率算法 输入 时间t, 节点u以及对于u的序号集W 输出 联合概率${{{f}}_{{t}}}\left( {{{{u}}_{{W}}}} \right)$ 1. if W只含一个元素 then 2. 找到该节点的双亲节点${{{v}}_{\left( {{i}} \right)}}$ 3. ${{{f}}_{{t}}}\left( {{{{u}}_{{W}}}} \right) = {{{f}}_{{{t}} - {{1}}}}\left( {{{{v}}_{\left( {{i}} \right)}}} \right) \times {{\beta }} \times \left( {{{1}} - {{{p}}_{{{t}} - {{1}}}}\left( {{u}} \right)} \right)$ 4. else 5. 找到传播树种${{{P}}_{{t}}}$代序号集为W的u节点, 记其双亲节点为${{{v}}_{{1}}}, {{{v}}_{{2}}}, \cdots , {{{v}}_{{l}}}$, 出现次数为$ m_1, $$ m_2, \cdots , m_l$, 这些路径对于双亲节点的序号集分别为${{{X}}_{{1}}}, {{{X}}_{{2}}}, \cdots , {{{X}}_{{l}}}$, 对于节点u的序号集分别为${{{Y}}_{{1}}}, {{{Y}}_{{2}}}, \cdots {{{Y}}_{{l}}}$. 6. for ${{j}} = 0 \to {{l}}$ do 7. ${{{f}}_{{t}}}\left( {{{{u}}_{{{{Y}}_{{j}}}}}} \right) = {{F}}\left( {{{t}} - {{1}}, {{{v}}_{{j}}}, {{{X}}_{{j}}}} \right) \times {{\beta }}$ 8. end for 9. ${{{f}}_{{t}}}\left( {{{{u}}_{{W}}}} \right) = \left[ {{{1}} - \mathop \prod \nolimits_{{{j}} = {{1}}}^{{l}} \left( {{{1}} - {{{f}}_{{t}}}\left( {{{{u}}_{{{{Y}}_{{j}}}}}} \right)} \right)} \right] \times \left( {{{1}} - {{{p}}_{{{t}} - {{1}}}}\left( {{u}} \right)} \right)$ 10. end if 11. return ${{{f}}_{{t}}}\left( {{{{u}}_{{W}}}} \right)$  下载: 导出CSV
下载: 导出CSV
表 2 种子节点s阶传播度的算法流程伪代码
Table 2. Pseudocode of the algorithm flow for s order progpagation of the seed node.
递推算法 求种子节点s阶传播度 输入 seed, ${{\beta }}$, s 输出 ${{{d}}_{{s}}}$ 1. ${\rm Tree }_{s} = {\rm FTree }(\rm seed)$ %获取节点${{seed}}$的s阶传播树 2. 赋初值${ { {p} }_{ {0} } }\left( { { {\rm seed} } } \right) = { { {f} }_{ {0} } }\left( { { {\rm seed} } } \right) = { {1} }$, 其他情况${{{p}}_{{t}}}\left( {{u}} \right) = {{{f}}_{{t}}}\left( {{u}} \right) = {{0}}$ 3. for ${{t}} = {{1}} \to {{s}}$ do 4. for ${{{u}}_{{y}}} \in {{{P}}_{{t}}}$ do %遍历传播树中${{{P}}_{{t}}}$代的个体 5. 获得${{{u}}_{{y}}}$的双亲节点${{{v}}_{{x}}}$ %表示节点u所在传播树层中第x个u节点 6. ${{{f}}_{{t}}}\left( {{{{u}}_{{y}}}} \right) = {{{f}}_{{{t}} - {{1}}}}\left( {{{{v}}_{{x}}}} \right) \times {{\beta }} \times \left( {{{1}} - {{{p}}_{{{t}} - {{1}}}}\left( {{u}} \right)} \right)$ 7. end for 8. for ${{u}} \in {{{P}}_{{t}}}$ do 9. 获得u的序号集W %指${{{P}}_{{t}}}$代节点u出现次序构成的集合 10. 计算联合概率${{{f}}_{{t}}}\left( {{u}} \right) = {{F}}\left( {{{t}}, {{u}}, {{W}}} \right)$ 11. end for 12. for $u \in {\rm Tree}_{s}$ do 13. ${{{p}}_{{t}}}\left( {{u}} \right) = {{{p}}_{{{t}} - 1}}\left( {{u}} \right) + {{{f}}_{{t}}}\left( {{u}} \right)$ 14. end for 15. end for 16. ${ { {d} }_{ {s} } }\left( { { \rm{seed} } } \right) = \mathop \sum \nolimits_{ {u} } { { {p} }_{ {s} } }\left( { {u} } \right)$ 17. return ${{{d}}_{{s}}}$
下载: 导出CSV
-
[1] Fershtman M 1997 Soc. Networks 19 193
[2] Chen D B, Lu L Y, Shang M S, Zhang Y C, Zhou T 2012 Physica A 391 1777
[3] Freeman L C 1977 Sociometry 40 35
Google Scholar
[4] Bavelas A 1950 J. Acoust. Soc. Am. 22 725
Google Scholar
[5] Dabbousi B O, Rodriguez-Viejo J, Mikulec F V, Heine J R, Mattoussi H, Ober R, Jensen K F, Bawendi M G 1997 J. Phys. Chem. B 101 9463
[6] 闵磊, 刘智, 唐向阳 2015 物理学报 64 088901
Min L, Liu Z, Tang X Y 2015 Acta Phys. Sin. 64 088901
[7] Domingos P, Richardson M 2001 Proceedings of KDD'01 ACM SIG KDD International Conference on Knowledge Discovery and Data Mining San Francisco, CA, USA, August 26−29, 2001 p57
[8] Kempe D, Kleinberg J, Tardos E 2003 Proc. 9th ACM SIGKDD Intl. Conf. On Knowledge Discovery and Data Mining New Washington, DC, USA, August 24−27, 2003 p137
[9] Leskovec J, Krause A, Guestrin C, Faloutsos C, VanBriesen J, Glance N 2007 Proc. 13 th ACM SIGKDD Intl. Conf. on Knowledge Discovery and Data Mining USA, August 24−27, 2007 p420
[10] Chen W, Wang Y, Yang S 2009 Proc. 15th ACM SIGKDD Intl. Conf. on Knowledge discovery and data mining Paris, France, June 28−July 1, 2009 p199
[11] Sheikhahmadi A, Nematbakhsh M A, Shokrollahi A 2015 Physica A 436 833
[12] Kimura M, Saito K 2006 Knowledge-Based Intelligent Information and Engineering Systems: 10th international conference Bournemouth, UK, October 9−11, 2006 p259
[13] Chen W, Wang C, Wang Y 2010 Proc. 16th ACM SIGKDD Intl. Conf. on Knowledge discovery and data mining WashingtonDC, USA, July 25−28, 2010 p1029
[14] Wang Y, Cong G, Song G 2010 Proc. 16th ACM SIGKDD Intl. Conf. on Knowledge discovery and mining Washington DC, USA, July 25−28, 2010 p1039
[15] Li D, Xu Z M, Chakraborty N 2014 PloS One 9 e102199
Google Scholar
[16] Hu Y Q, Ji S G, Jin Y L, Feng L, Stanley H E, Havlin S 2018 PNAS 115 7468
Google Scholar
[17] Lancichinetti A, Fortunato S 2009 Phys. Rev. E 80 056117
[18] Leskovec J, Lang K, Dasgupta A, Mahoney M W 2009 Internet Mathematics 6 29
Google Scholar
[19] Lapata M 2006 Comput. Linguist. 32 471
Google Scholar
[20] Kitsak M, Gallos L K, Havlin S, Liljeros F, Muchnik L, Stanley H E, Makse H A 2010 Nat. Phys. 6 888
Google Scholar

 下载:
下载:
计量
- 文章访问数: 10345
- PDF下载量: 119
- 被引次数: 0
