










-
脉冲神经网络(spiking neural network, SNN)作为第三代神经网络, 其计算效率更高、资源开销更少, 且仿生能力更强, 展示出了对于语音、图像处理的优秀潜能. 传统的脉冲神经网络硬件加速器通常使用加法器模拟神经元对突触权重的累加. 这种设计对于硬件资源消耗较大、神经元/突触集成度不高、加速效果一般. 因此, 本工作开展了对拥有更高集成度、更高计算效率的脉冲神经网络推理加速器的研究. 阻变式存储器(resistive random access memory, RRAM)又称忆阻器(memristor), 作为一种新兴的存储技术, 其阻值随电压变化而变化, 可用于构建crossbar架构模拟矩阵运算, 已经在被广泛应用于存算一体(processing in memory, PIM)、神经网络计算等领域. 因此, 本次工作基于忆阻器阵列, 设计了权值存储矩阵, 并结合外围电路模拟了LIF (leaky integrate and fire)神经元计算过程. 之后, 基于LIF神经元模型实现了脉冲神经网络硬件推理加速器设计. 该加速器消耗了0.75k忆阻器, 集成了24k神经元和192M突触. 仿真结果显示, 在50 MHz的工作频率下, 该加速器通过部署三层的全连接脉冲神经网络对MNIST (mixed national institute of standards and technology)数据集进行推理加速, 其最高计算速度可达148.2 frames/s, 推理准确率为96.4%.Spiking neural network (SNN) as the third-generation artificial neural network, has higher computational efficiency, lower resource overhead and higher biological rationality. It shows greater potential applications in audio and image processing. With the traditional method, the adder is used to add the membrane potential, which has low efficiency, high resource overhead and low level of integration. In this work, we propose a spiking neural network inference accelerator with higher integration and computational efficiency. Resistive random access memory (RRAM or memristor) is an emerging storage technology, in which resistance varies with voltage. It can be used to build a crossbar architecture to simulate matrix computing, and it has been widely used in processing in memory (PIM), neural network computing, and other fields. In this work, we design a weight storage matrix and peripheral circuit to simulate the leaky integrate and fire (LIF) neuron based on the memristor array. And we propose an SNN hardware inference accelerator, which integrates 24k neurons and 192M synapses with 0.75k memristor. We deploy a three-layer fully connected network on the accelerator and use it to execute the inference task of the MNIST dataset. The result shows that the accelerator can achieve 148.2 frames/s and 96.4% accuracy at a frequency of 50 MHz.
-
Keywords:
- spiking neural networks /
- resistive random access memory /
- processing in memory /
- leaky integrate and fire model /
- hardware inference accelerator
[1] Redmon J, Farhadi A 2017 30th IEEE Conference on Computer Vision & Pattern Recognition Honolulu, HI, July 21–26, 2017 pp6517–6525
[2] Silver D, Schrittwieser J, Simonyan K, Antonoglou I, Huang A, Guez A, Hubert T, Baker L, Lai M, Bolton A, Chen Y, Lillicrap T, Hui F, Sifre L, Van Den Driessche G, Graepel T, Hassabis D 2017 Nature 550 354
 Google Scholar
Google Scholar
[3] McCulloch W S, Pitts W 1943 Bull. Math. Biophys. 5 115
Google Scholar
[4] Hodgkin A L, Huxley A F 1952 J. Physiol. 116 449
Google Scholar
[5] Gerstner W 1995 Phys. Rev. E:Stat. Phys. Plasmas Fluids Relat. Interdisciplin. Top. 51 738
[6] Maass W 1997 Neural Networks 10 1659
Google Scholar
[7] Roy K, Jaiswal A, Panda P 2019 Nature 575 607
Google Scholar
[8] 陈怡然, 李海, 陈逸中, 陈凡, 李思成, 刘晨晨, 闻武杰, 吴春鹏, 燕博南 2018 人工智能 13 46
Chen Y R, Li H, Chen Y Z, Chen F, Li S C, Liu C C, Wen W J, Wu C P, Yan B N 2018 Artif. Intell. View 13 46
[9] Schuman C D, Potok T E, Patton R M, Birdwell J D, Dean M E, Rose G S, Plank J S2017 arXiv:1705.06963
[10] Mahapatra N R, Venkatrao B 1999 Crossroads 5 2
[11] von Neumann J 1993 IEEE Ann. Hist. Comput. 15 27
Google Scholar
[12] Chen T, Du Z, Sun N, Wang J, Wu C, Chen Y, Temam O 2014 Acm Sigplan Notices 49 269
[13] Benjamin B V, Gao P, Mcquinn E, Chou D Hary S, Chandrasekaran A R, Bussat J, Alvarez-Icaza R, Arthur J V, Merolla P A, Boahen K 2014 Proc. IEEE 102 699
Google Scholar
[14] Pei J, Deng L, Song S, Zhao M G, Zhang Y H, Wu S, Wang G R, Zou Z, Wu Z Z, He W, Chen F, Deng N, Wu S, Wang Y, Wu Y J, Yang Z Y, Ma C, Li G Q, Han W T, Li H L, Wu H Q, Zhao R, Xie Y, Shi L P 2019 Nature 572 106
Google Scholar
[15] Davies M, Srinivasa N, Lin T H, Chinya G, Cao Y, Choday S H, Dimou G, Joshi P, Imam N, Jain S 2018 IEEE Micro 38 82
Google Scholar
[16] Akopyan F, Sawada J, Cassidy A, Alvarez-Icaza R, Arthur J, Merolla P, Imam N, Nakamura Y, Datta P, Nam G J 2015 IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 34 1537
Google Scholar
[17] Furber S B, Galluppi F, Temple S, Plana L A 2014 Proc. IEEE 102 652
Google Scholar
[18] 李锟, 曹荣荣, 孙毅, 刘森, 李清江, 徐晖 2019 微纳电子与智能制造 1 87
Li K, Cao R R, Sun Y, Liu S, Li Q J, Xu H 2019 Micro/nano Electron. Intell. Manuf. 1 87
[19] Xia Q F, Yang J J 2019 Nat. Mater. 18 309
Google Scholar
[20] 邓亚彬, 王志伟, 赵晨晖, 李琳, 贺珊, 李秋红, 帅建伟, 郭东辉 2021 计算机应用研究 38 2241
Deng Y B, Wang Z W, Zhao C H, Li L, He S, Li Q H, Shuai J W, Guo D H 2021 Appl. Res. Comput. 38 2241
[21] Burr G W, Shelby R M, Sidler S, Nolfo C D, Jang J, Boybat I, Shenoy R S, Narayanan P, Virwani K, Giacometti E U 2015 IEEE Trans. Electron Devices 62 3498
Google Scholar
[22] Moro F, Hardy M, Fain B, Dalgaty T, Clemencon P, De Pra A, Esmanhotto E, Castellani N, Blard F, Gardien F, Mesquida T, Rummens F, Eseni D, Casas J, Indiveri G, Payvand M, Vianello E 2022 Nat. Commun. 13 3506
Google Scholar
[23] 方旭东, 吴俊杰 2020 计算机工程与科学 42 1929
Google Scholar
Fang X D, Wu J J 2020 Comput. Eng. Sci. 42 1929
Google Scholar
[24] Peng Y, Wu H, Gao B, Eryilmaz S B, Qian H 2017 Nat. Commun. 8 15199
Google Scholar
[25] Huang L, Diao J T, Nie H S, Wang W, Li Z W, Li Q J, Liu H J 2021 Front. Neurosci. 15 639526
Google Scholar
-

图 1 基于LIF模型的全连接脉冲神经网络结构图
Fig. 1. Structure diagram of fully connected spiking neural network based on LIF model.

图 2 (a)神经元原理图; (b)神经元计算原理图
Fig. 2. (a) Neuron schematic diagram; (b) schematic diagram of neuron computation.

图 3 基于突触复用技术及权值共享技术的LIF神经元模型架构
Fig. 3. The LIF neuron model architecture based on synapse multiplexing technology and weight sharing technology.
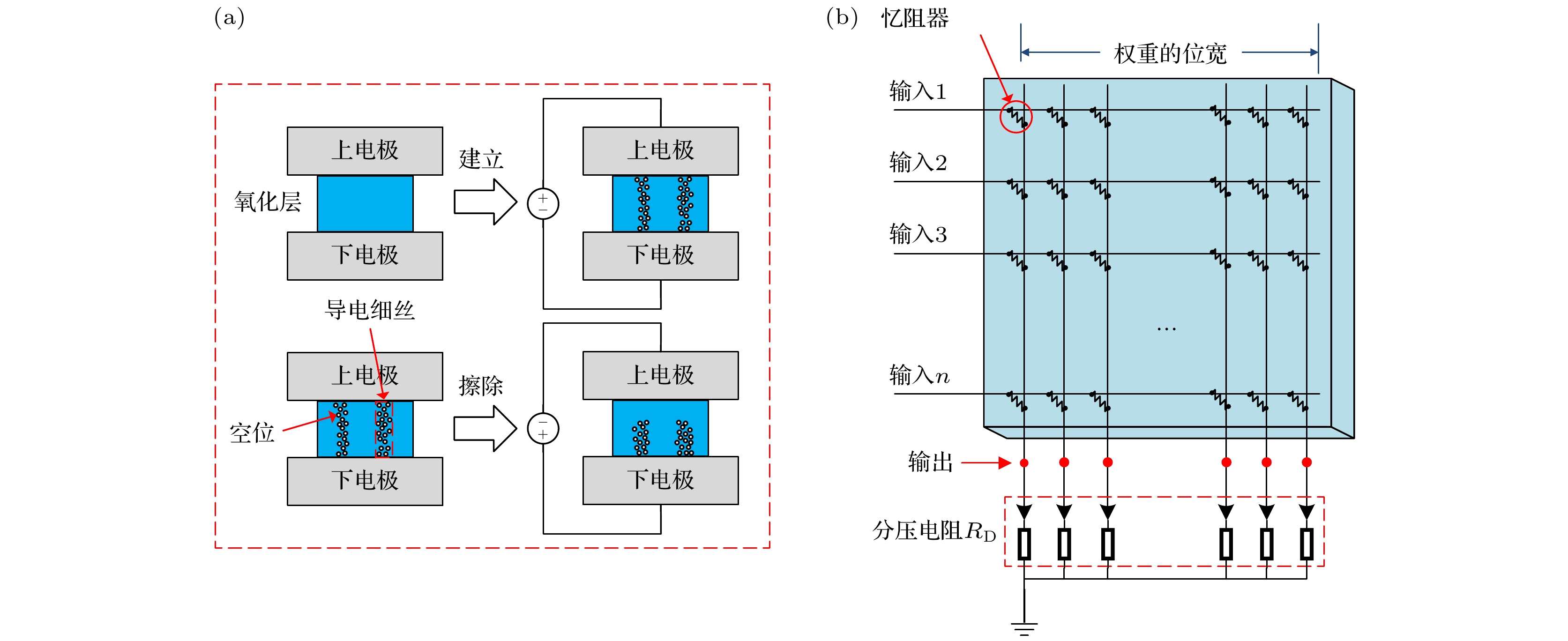
图 4 (a) 忆阻器的建立/擦除示意图; (b) 基于忆阻器的crossbar阵列
Fig. 4. (a) The set/reset operation of the memristor; (b) the crossbar structure based on the memristor.
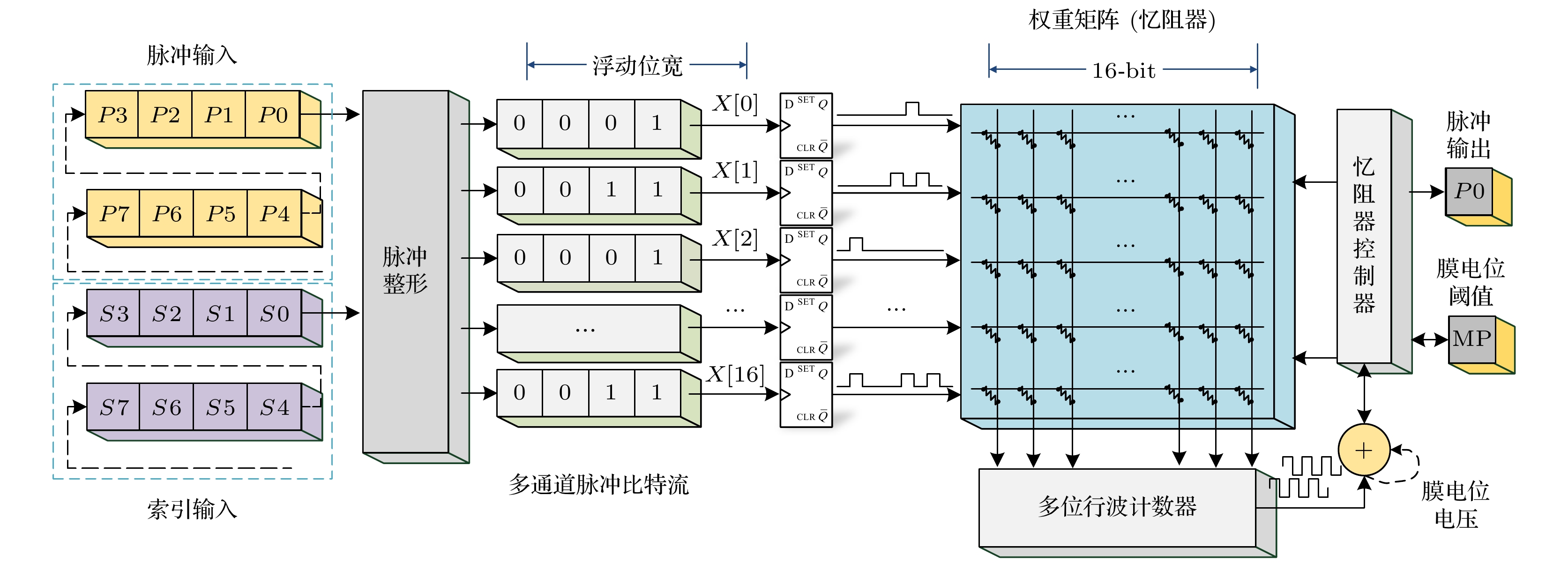
图 6 基于忆阻器阵列的计算核架构
Fig. 6. Computing core architecture based on resistive random access memory matrix.

图 7 基于硬件加速器的应用架构图
Fig. 7. Application architecture diagram based on hardware accelerator.
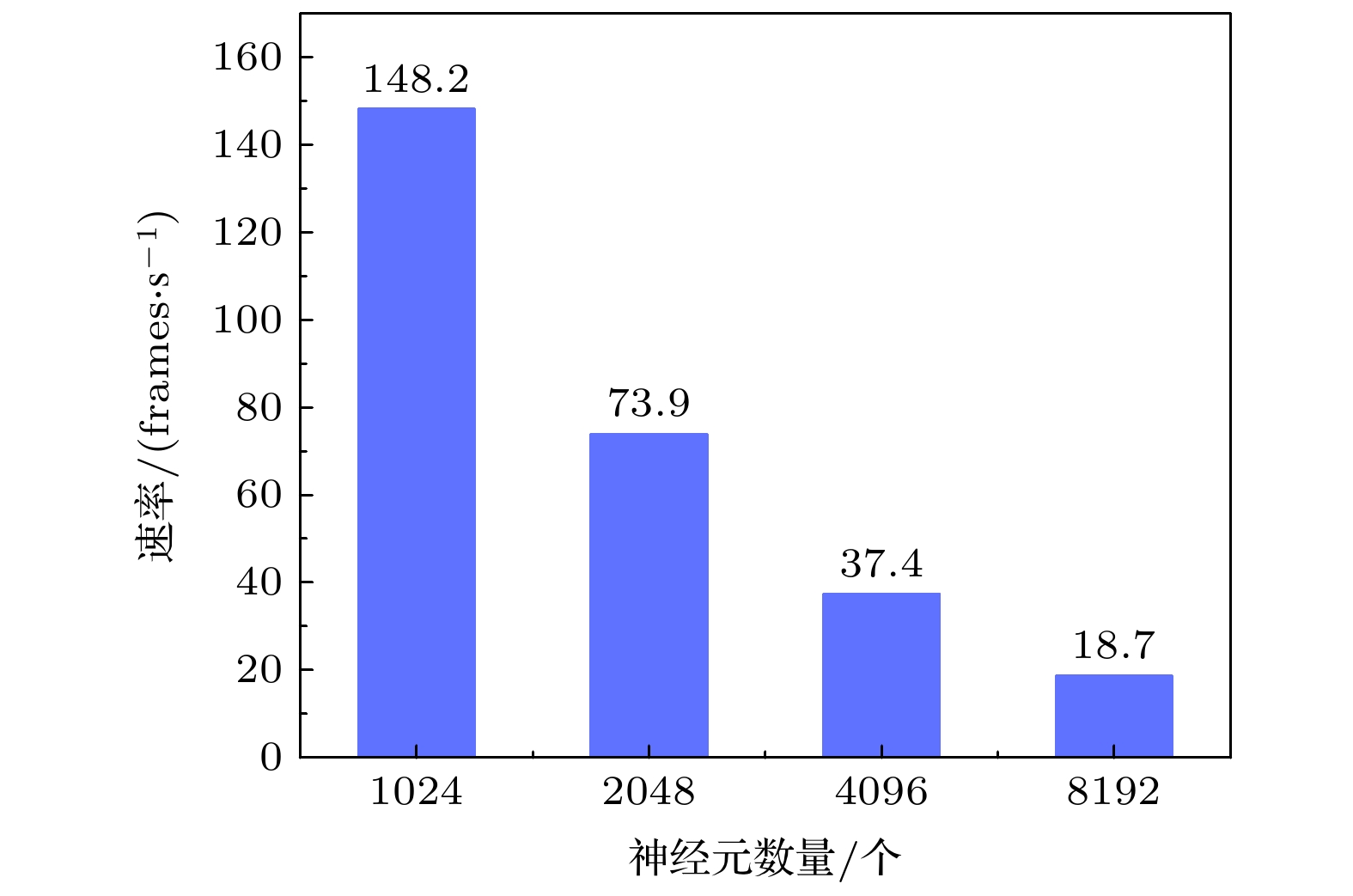
图 9 硬件加速器对不同规模神经网络计算的加速效率
Fig. 9. Acceleration efficiency of hardware accelerator for different scale neuron networks.
-
[1] Redmon J, Farhadi A 2017 30th IEEE Conference on Computer Vision & Pattern Recognition Honolulu, HI, July 21–26, 2017 pp6517–6525
[2] Silver D, Schrittwieser J, Simonyan K, Antonoglou I, Huang A, Guez A, Hubert T, Baker L, Lai M, Bolton A, Chen Y, Lillicrap T, Hui F, Sifre L, Van Den Driessche G, Graepel T, Hassabis D 2017 Nature 550 354
Google Scholar
[3] McCulloch W S, Pitts W 1943 Bull. Math. Biophys. 5 115
Google Scholar
[4] Hodgkin A L, Huxley A F 1952 J. Physiol. 116 449
Google Scholar
[5] Gerstner W 1995 Phys. Rev. E:Stat. Phys. Plasmas Fluids Relat. Interdisciplin. Top. 51 738
[6] Maass W 1997 Neural Networks 10 1659
Google Scholar
[7] Roy K, Jaiswal A, Panda P 2019 Nature 575 607
Google Scholar
[8] 陈怡然, 李海, 陈逸中, 陈凡, 李思成, 刘晨晨, 闻武杰, 吴春鹏, 燕博南 2018 人工智能 13 46
Chen Y R, Li H, Chen Y Z, Chen F, Li S C, Liu C C, Wen W J, Wu C P, Yan B N 2018 Artif. Intell. View 13 46
[9] Schuman C D, Potok T E, Patton R M, Birdwell J D, Dean M E, Rose G S, Plank J S2017 arXiv:1705.06963
[10] Mahapatra N R, Venkatrao B 1999 Crossroads 5 2
[11] von Neumann J 1993 IEEE Ann. Hist. Comput. 15 27
Google Scholar
[12] Chen T, Du Z, Sun N, Wang J, Wu C, Chen Y, Temam O 2014 Acm Sigplan Notices 49 269
[13] Benjamin B V, Gao P, Mcquinn E, Chou D Hary S, Chandrasekaran A R, Bussat J, Alvarez-Icaza R, Arthur J V, Merolla P A, Boahen K 2014 Proc. IEEE 102 699
Google Scholar
[14] Pei J, Deng L, Song S, Zhao M G, Zhang Y H, Wu S, Wang G R, Zou Z, Wu Z Z, He W, Chen F, Deng N, Wu S, Wang Y, Wu Y J, Yang Z Y, Ma C, Li G Q, Han W T, Li H L, Wu H Q, Zhao R, Xie Y, Shi L P 2019 Nature 572 106
Google Scholar
[15] Davies M, Srinivasa N, Lin T H, Chinya G, Cao Y, Choday S H, Dimou G, Joshi P, Imam N, Jain S 2018 IEEE Micro 38 82
Google Scholar
[16] Akopyan F, Sawada J, Cassidy A, Alvarez-Icaza R, Arthur J, Merolla P, Imam N, Nakamura Y, Datta P, Nam G J 2015 IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 34 1537
Google Scholar
[17] Furber S B, Galluppi F, Temple S, Plana L A 2014 Proc. IEEE 102 652
Google Scholar
[18] 李锟, 曹荣荣, 孙毅, 刘森, 李清江, 徐晖 2019 微纳电子与智能制造 1 87
Li K, Cao R R, Sun Y, Liu S, Li Q J, Xu H 2019 Micro/nano Electron. Intell. Manuf. 1 87
[19] Xia Q F, Yang J J 2019 Nat. Mater. 18 309
Google Scholar
[20] 邓亚彬, 王志伟, 赵晨晖, 李琳, 贺珊, 李秋红, 帅建伟, 郭东辉 2021 计算机应用研究 38 2241
Deng Y B, Wang Z W, Zhao C H, Li L, He S, Li Q H, Shuai J W, Guo D H 2021 Appl. Res. Comput. 38 2241
[21] Burr G W, Shelby R M, Sidler S, Nolfo C D, Jang J, Boybat I, Shenoy R S, Narayanan P, Virwani K, Giacometti E U 2015 IEEE Trans. Electron Devices 62 3498
Google Scholar
[22] Moro F, Hardy M, Fain B, Dalgaty T, Clemencon P, De Pra A, Esmanhotto E, Castellani N, Blard F, Gardien F, Mesquida T, Rummens F, Eseni D, Casas J, Indiveri G, Payvand M, Vianello E 2022 Nat. Commun. 13 3506
Google Scholar
[23] 方旭东, 吴俊杰 2020 计算机工程与科学 42 1929
Google Scholar
Fang X D, Wu J J 2020 Comput. Eng. Sci. 42 1929
Google Scholar
[24] Peng Y, Wu H, Gao B, Eryilmaz S B, Qian H 2017 Nat. Commun. 8 15199
Google Scholar
[25] Huang L, Diao J T, Nie H S, Wang W, Li Z W, Li Q J, Liu H J 2021 Front. Neurosci. 15 639526
Google Scholar

 下载:
下载:


计量
- 文章访问数: 16807
- PDF下载量: 501
- 被引次数: 0
