










-
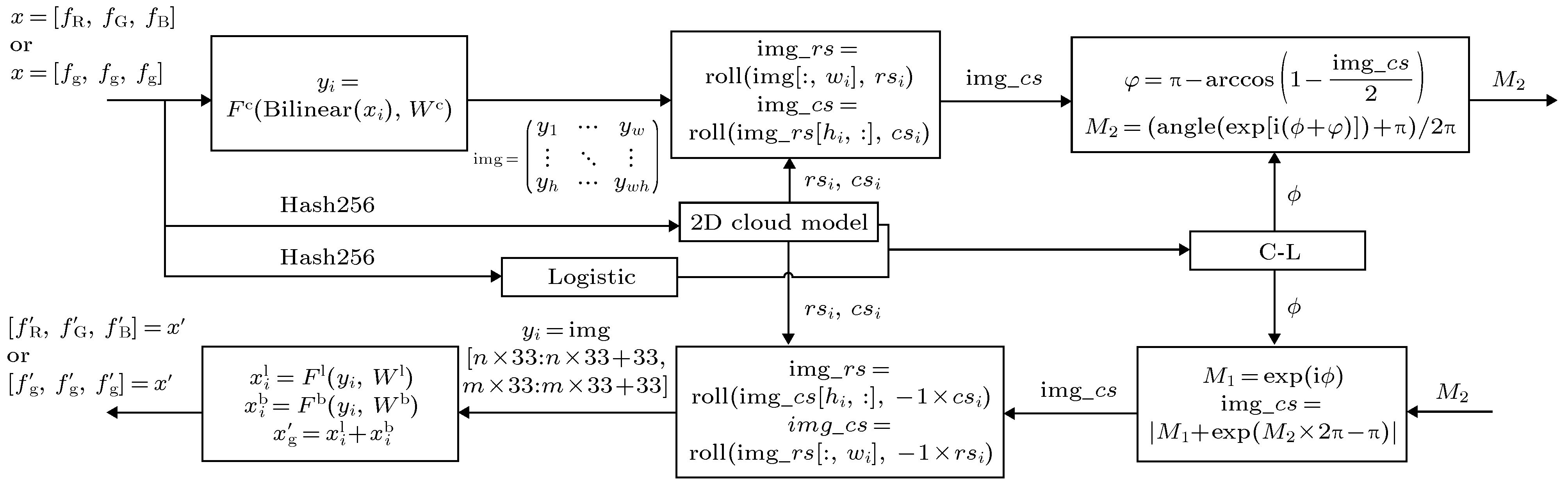
提出一种适用于灰度图像与RGB格式彩色图像的通用图像加密算法. 利用双线性插值Bilinear与卷积神经网络对图像进行压缩, 再使用二维云模型与Logistic组成的复合混沌系统对压缩图像加解密(滑动置乱与矢量分解), 最后对解密图像进行重构. 重构网络中, 由卷积神经网络与双线性插值Bilinear主要负责重构轮廓信息, 全连接层主要负责重构颜色信息. 实验结果表明, 该基于深度学习压缩感知与复合混沌系统的通用图像加密算法在数据处理质量和计算量上有着很大优势. 由于复合混沌系统有着足够大的密钥空间且将明文哈希值与密钥关联, 可实现一图一密的加密效果, 能有效抵抗暴力攻击与选择明文攻击, 与对比文献相比, 相关系数更接近理想值且信息熵与明文敏感性指标也都在临界值范围内, 其加密算法有着更高的安全性.Many image compression and encryption algorithms based on traditional compressed sensing and chaotic systems are time-consuming, have low reconstruction quality, and are suitable only for grayscale images. In this paper, we propose a general image compression encryption algorithm based on a deep learning compressed sensing and compound chaotic system, which is suitable for grayscale images and RGB format color images. Color images can be directly compressed and encrypted, but grayscale images need copying from 1 channel to 3 channels. First, the original image is divided into multiple 3 × 33 × 33 non-overlapping image blocks and the bilinear interpolation Bilinear and convolutional neural network are used to compress the image, so that the compression network has no restriction on the sampling rate and can obtain high-quality compression of image. Then a composite chaotic system composed of a two-dimensional cloud model and Logistic is used to encrypt and decrypt the compressed image (sliding scrambling and vector decomposition), and finally the decrypted image is reconstructed. In the reconstruction network, the convolutional neural network and bilinear interpolation Bilinear are mainly responsible for reconstructing the contour structure information, and the fully connected layer is mainly responsible for reconstructing and combining the color information to reconstruct a high-quality image. For grayscale images, we also need to calculate the average value of the corresponding positions of the 3 channels of the reconstructed image, and change the 3 channels into 1 channel. The experimental results show that the general image encryption algorithm based on deep learning compressed sensing and compound chaos system has great advantages in data processing quality and computational complexity. Although in the network the color images are used for training, the quality of grayscale image reconstruction is still better than that of other algorithms. The image encryption algorithm has a large enough key space and associates the plaintext hash value with the key, which realizes the encryption effect of one image corresponding to one key, thus being able to effectively resist brute force attacks and selective plaintext attacks. Compared with it in the comparison literature, the correlation coefficient is close to an ideal value, and the information entropy and the clear text sensitivity index are also within a critical range, which enhances the confidentiality of the image.
-
Keywords:
- deep learning /
- compressed sensing /
- encryption /
- compound chaotic system
[1] Donoho D L 2006 IEEE Trans. Inf. Theory 52 1289
 Google Scholar
Google Scholar
[2] Candes E J, Romberg J, Tao T 2006 IEEE Trans. Inf. Theory 52 489
Google Scholar
[3] Candes E J, Wakin M B 2008 IEEE Signal Process. Mag. 25 21
Google Scholar
[4] Mousavi A, Patel A B, Baraniuk R G 2015 53rd Annual Allerton Conference on Communication, Control, and Computing Monticello, USA, September 29–October 2, 2015 p1336
[5] 练秋生, 富利鹏, 陈书贞, 石保顺 2019 自动化学报 45 2082
Google Scholar
Lian Q S, Fu L P, Chen S Z, Shi B S 2019 Acta Autom. Sin. 45 2082
Google Scholar
[6] Kulkarni K, Lohit S, Turaga P, Kerviche R, Ashok A 2016 IEEE Conference on Computer Vision and Pattern Recognition Las Vegas, USA, June 26–30, 2016 p449
[7] Yao H T, Dai F, Zhang SL, Zhang Y D, Tian Q, Xu C S 2019 Neurocomputing 359 483
Google Scholar
[8] 李静, 向菲, 张军朋 2019 电子设计工程 27 84
Google Scholar
Li J, Xian F, Zhang J P 2019 Int. Electr. Elem. 27 84
Google Scholar
[9] Hu X C, Wei L S, Chen W, Chen Q Q, Guo Y 2020 IEEE Access 8 12452
Google Scholar
[10] 庄志本, 李军, 刘静漪, 陈世强 2020 物理学报 69 040502
Google Scholar
Zhuang Z B, Li J, Liu J Y, Chen S Q 2020 Acta Phys. Sin. 69 040502
Google Scholar
[11] Zhang D, Liao X F, Yang B, Zhang Y S 2018 Multim. Tools Appl. 77 2191
Google Scholar
[12] 石航, 王丽丹 2019 物理学报 68 200501
Google Scholar
Shi H, Wang L D 2019 Acta Phys. Sin. 68 200501
Google Scholar
[13] Gong L H, Qiu K D, Deng C Z, Zhou N R 2019 Opt. Laser Technol. 115 257
Google Scholar
[14] Qin W, Peng X 2010 Opt. Lett. 35 118
Google Scholar
[15] Liu Y N, Niu H Q, Li Z L 2019 Chin. Phys. Lett. 36 044302
Google Scholar
[16] Li C B, Yin W T, Jiang H, Zhang Y 2013 Comput. Optim. Appl. 56 507
Google Scholar
[17] Dong W S, Shi G M, Li X, Ma Y, Huang F 2014 IEEE Trans. Image Process. 23 3618
Google Scholar
[18] Metzler C A, Maleki A, Baraniuk R G 2016 IEEE Trans. Inf. Theory 62 5117
Google Scholar
[19] Guo Y, Jing S W, Zhou Y Y, Xu X, Wei L S 2020 IEEE Access 8 9896
Google Scholar
[20] Belazi A, El-Latif A A, Belghith S 2016 Signal Process. 128 155
Google Scholar
[21] Hua Z Y, Zhou Y C, Pun C M, Chen C 2015 Inf. Sci. 297 80
Google Scholar
[22] Wu Y, Zhou Y C, Saveriades G, Agaian S S, Noonan J P, Natarajan P 2013 Inf. Sci. 222 323
Google Scholar
-
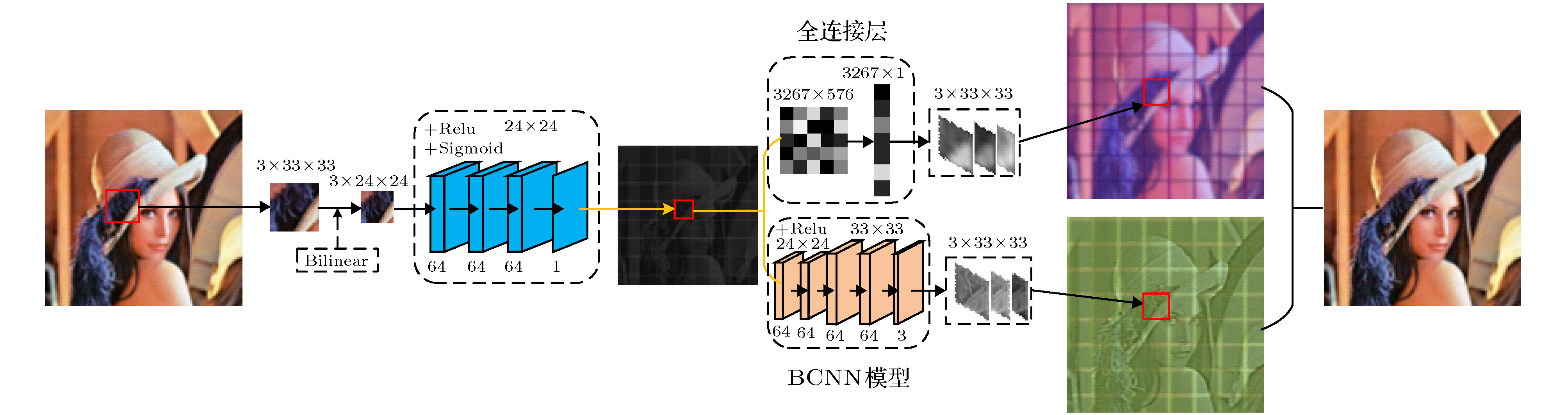
图 2 彩色图像的压缩重构网络(采样率MR = 0.18)
Fig. 2. Color image compression and reconstruction network, sampling rate MR = 0.18.

图 3 BCNN模型与全连接层分别重构的Lena和Sea图像 (a) Lena (灰度); (b) Lena (彩色); (c) Sea (灰度); (d) Sea (彩色)
Fig. 3. Lena and Sea images reconstructed from BCNN model and fully connected layer respectively: (a) Lena (gray); (b) Lena (color); (c) Sea (gray); (d) Sea (color).
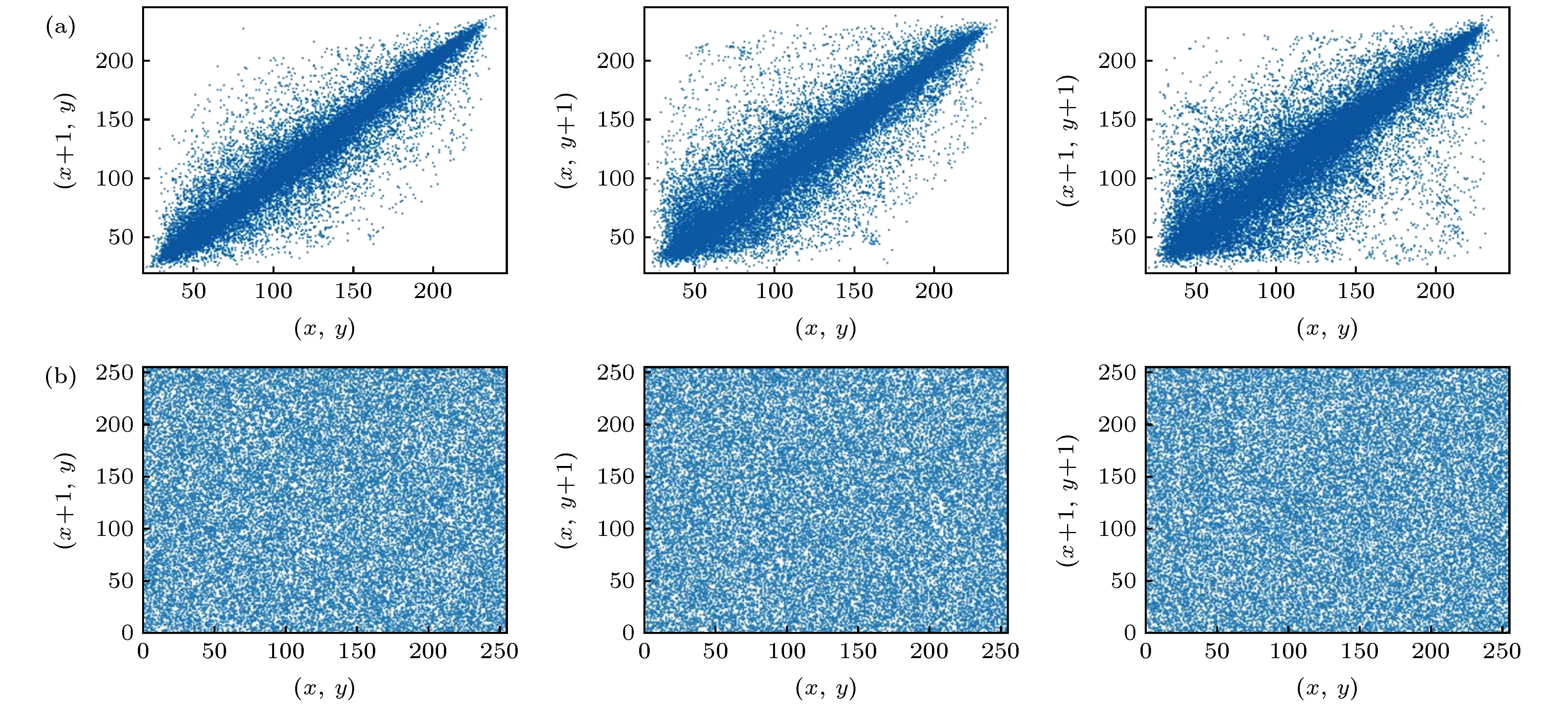
图 5 Lena (gray)图像明文与密文在水平、竖直、斜线3个方向的相关分布图 (a) 明文图像的相关分布图; (b)密文图像的相关分布图
Fig. 5. Correlation distribution of the plaintext and ciphertext in the horizontal, vertical and oblique directions of Lena (gray) images: (a) Correlation distribution of plaintext; (b) correlation distribution of ciphertext.

图 6 在密文图像上添加高斯噪声或椒盐噪声后重构出的Lena图像 (a), (b)使用的网络在训练时没有添加高斯噪声; (c), (d)使用的网络在训练时添加了强度为0.10的高斯噪声
Fig. 6. Lena image reconstructed by adding Gaussian noise or salt and pepper noise to the ciphertext image: The networks used in (a) and (b) did not add Gaussian noise during training; the networks used in (c) and (d) are trained with Gaussian noise with an intensity of 0.10.

图 7 Lena图像的密文被剪切后的重构结果 (a)剪切不同大小后的密文; (b), (c)使用的网络在训练时没有添加高斯噪声; (d), (e)使用的网络在训练时添加了强度为0.10的高斯噪声
Fig. 7. Reconstruction result after ciphertext cut of Lena image: (a) Cut ciphertexts of different sizes; the networks used in (b) and (c) did not add Gaussian noise during training; the networks used in (d) and (e) are trained with Gaussian noise with an intensity of 0.10.
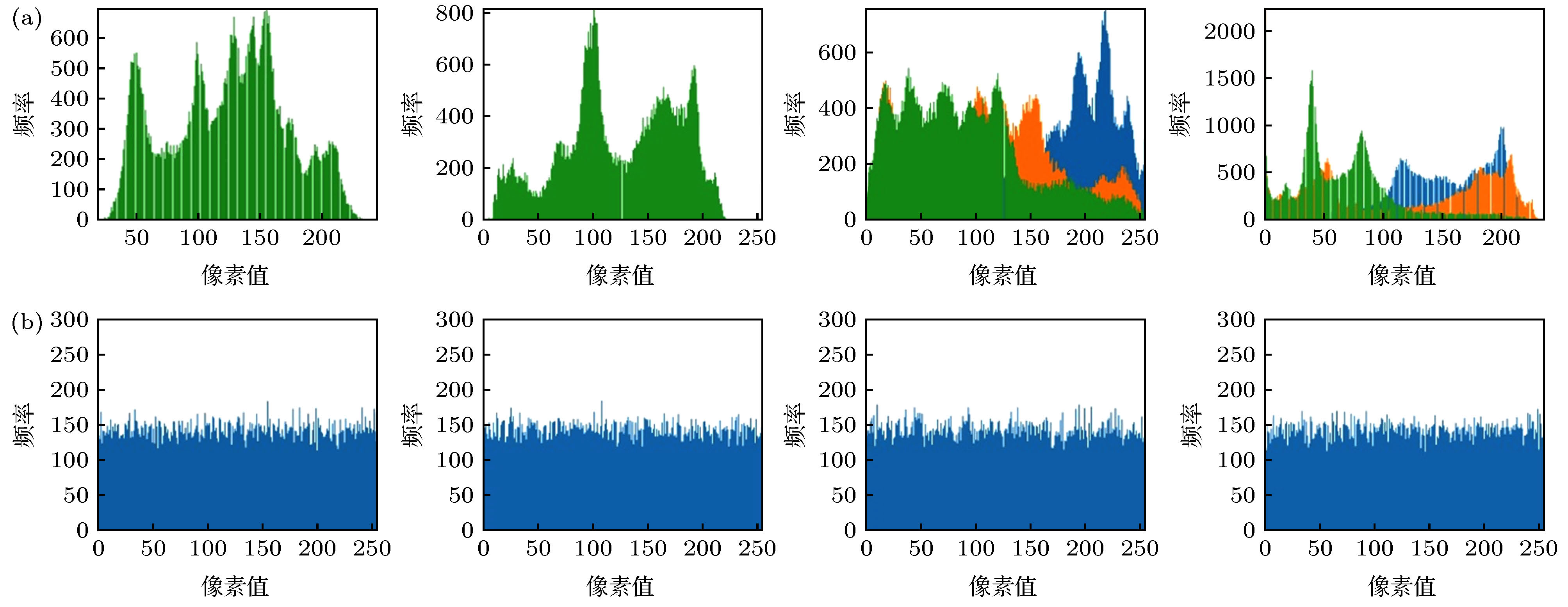
图 9 Lena (gray), Peppers (gray), Lena (color), Peppers (color)图像在明文与密文上的直方图 (a)明文直方图; (b)密文直方图
Fig. 9. Histograms of Lena (gray), Peppers (gray), Lena (color), Peppers (color) images in plain text and ciphertext: (a) Plain text histogram; (b) ciphertext histogram.
表 1 重构的灰度图像在不同算法、不同采样率下的PSNR
Table 1. PSNR of reconstructed gray images under different algorithms and different sampling rates.
采样率 算法 Lena Monarch Flinstones 平均PSNR 0.25 TVAL3 28.67 27.77 24.05 27.84 NLR-CS 29.39 25.91 22.43 28.05 D-AMP 28.00 26.39 25.02 28.17 ReconNet 26.54 24.31 22.45 25.54 DR2-Net 29.42 27.95 26.19 28.66 MSRNet 30.21 28.90 26.67 29.48 FCLBCNN 31.09 29.97 27.57 29.71 0.10 TVAL3 24.16 21.16 18.88 22.84 NLR-CS 15.30 14.59 12.18 14.19 D-AMP 22.51 19.00 16.94 21.14 ReconNet 23.83 21.10 18.92 22.68 DR2-Net 25.39 23.10 21.09 24.32 MSRNet 26.28 23.98 21.72 25.16 FCLBCNN 26.93 24.58 22.08 25.41 0.04 TVAL3 19.46 16.73 14.88 18.39 NLR-CS 11.61 11.62 8.96 10.58 D-AMP 16.52 14.57 12.93 15.49 ReconNet 21.28 18.19 16.30 19.99 DR2-Net 22.13 18.93 16.93 20.80 MSRNet 22.76 19.26 17.28 21.41 FCLBCNN 23.33 19.59 17.17 21.51 0.01 TVAL3 11.87 11.09 9.75 11.31 NLR-CS 5.95 6.38 4.45 5.30 D-AMP 5.73 6.20 4.33 5.19 ReconNet 17.87 15.39 13.96 17.27 DR2-Net 17.97 15.33 14.01 17.44 MSRNet 18.06 15.41 13.83 17.54 FCLBCNN 18.12 15.63 13.90 17.62  下载: 导出CSV
下载: 导出CSV
表 2 在BSD500测试集上不同算法、不同采样率下的平均PSNR和平均SSIM
Table 2. Mean PSNR and SSIM of different algorithms and different sampling rates on the BSD500 test set.
算法 MR = 0.08 MR = 0.10 MR = 0.18 MR = 0.25 MR = 0.53 PSNR SSIM PSNR SSIM PSNR SSIM PSNR SSIM PSNR SSIM ReconNet — — 23.28 0.6121 — — 25.48 0.7241 — — DR2-Net — — 24.26 0.6603 — — 27.56 0.7961 — — MSRNet — — 24.73 0.6837 — — 27.93 0.8121 — — FCLBCNN (gray) — — 24.83 0.7056 — — 28.19 0.8400 32.87 0.9392 FCLBCNN (color) 27.94 0.8252 — — 32.07 0.9279 — — — —
下载: 导出CSV
表 3 Lena图像在各阶段的效果(采样率MR = 0.53 (灰度), 0.18 (彩色))
Table 3. Lena image effects at various stages, sampling rate MR = 0.53 (gray), 0.18 (color).
原图 采样率 压缩图像 置乱图像 密文图像 重构图像 PSNR SSIM 
0.53 
36.4387 0.9715 
0.18 
32.5516 0.9456
下载: 导出CSV
表 4 不同加密算法的相关系数比较
Table 4. Comparison of correlation coefficients of different encryption algorithms.
测试图像 方向 明文(gray) 密文 本文(gray) 本文(color) 文献[20] 文献[21] Lena 水平 0.9396 0.0010 –0.0024 –0.0048 0.0011 竖直 0.9639 –0.0066 0.0012 –0.0112 0.0098 斜线 0.9189 –0.0039 0.0035 –0.0045 –0.0227 Peppers 水平 0.9769 –0.0004 –0.0023 –0.0056 0.0071 竖直 0.9772 0.0089 0.0063 –0.0162 –0.0065 斜线 0.9625 –0.0077 0.0004 –0.0113 –0.0165 平均值 水平 — 0.0003 –0.0024 –0.0052 0.0041 竖直 — 0.0012 0.0038 –0.0137 0.0017 斜线 — –0.0058 0.0020 –0.0079 –0.0196
下载: 导出CSV
表 5 不同加密算法得到的信息熵的比较
Table 5. Comparison of the entropy obtained by different encryption algorithms.
测试图像 明文(gray) 密文 本文(gary) 本文(color) 文献[12] Lena 7.3035 7.9949 7.9944 7.9544 Peppers 7.4344 7.9956 7.9952 7.9633
下载: 导出CSV
表 6 不同加密算法得到的局部信息熵比较
Table 6. Comparison of the local entropy obtained by different encryption algorithms.
测试图像 局部信息熵(gray/color) 临界值 $\begin{array}{l} u_{0.05}^{* - } = 7.9019 \\ u_{0.05}^{* + } = 7.9030 \end{array}$ $\begin{array}{l} u_{0.01}^{* - } = 7.9017 \\ u_{0.01}^{* + } = 7.9032 \end{array}$ $\begin{array}{l} u_{0.001}^{* - } = 7.9015 \\ u_{0.001}^{* + } = 7.9034 \end{array}$ Lena 7.9024/7.9027 Pass Pass Pass Peppers 7.9027/7.9023 Pass Pass Pass
下载: 导出CSV
表 7 不同加密算法得到的NPCR比较
Table 7. Comparison of NPCR obtained by different encryption algorithms.
下载: 导出CSV
表 8 不同加密算法得到的UACI比较
Table 8. Comparison of UACI obtained by different encryption algorithms.
测试图像 UACI (gray/color) UACI理论临界值 $\begin{array}{l} u_{0.05}^{* - } = 33.2824\% \\ u_{0.05}^{* + } = 33.6447\% \end{array}$ $\begin{array}{l} u_{0.01}^{* - } = 33.2255\% \\ u_{0.01}^{* + } = 33.7016\% \end{array}$ $\begin{array}{l} u_{0.001}^{* - } = 33.1594\% \\ u_{0.001}^{* + } = 33.7677\% \end{array}$ Lena 0.3352/0.3357 Pass Pass Pass Lena[12] 0.3303/— Fail Fail Fail Lena[20] 0.3370/— Fail Pass Pass Peppers 0.3333/0.3331 Pass Pass Pass Peppers[12] 0.3305/— Fail Fail Fail Peppers[20] 0.3369/— Fail Pass Pass
下载: 导出CSV
表 9 本文压缩加密算法与在原图上直接使用本文加密算法的耗时对比
Table 9. Time-consuming comparison that the compression encryption algorithm of this article and the encryption algorithm of this article directly used on the original image.
图像大小 压缩重构(gray/color) 加解密(gray/color) 总时间(gray/color) 编程工具 平台 256 × 256 0.21/0.20 0.66/0.65 0.87/0.85 Pycharm + Pytorch i5-8500 CPU — 0.93/2.81 0.93/2.81 512 × 512 0.91/0.89 2.51/2.51 3.42/3.40 — 3.89/11.96 3.89/11.96 1024 × 1024 4.81/4.62 9.40/9.42 14.21/14.04 — 15.84/48.51 15.84/48.51
下载: 导出CSV
-
[1] Donoho D L 2006 IEEE Trans. Inf. Theory 52 1289
Google Scholar
[2] Candes E J, Romberg J, Tao T 2006 IEEE Trans. Inf. Theory 52 489
Google Scholar
[3] Candes E J, Wakin M B 2008 IEEE Signal Process. Mag. 25 21
Google Scholar
[4] Mousavi A, Patel A B, Baraniuk R G 2015 53rd Annual Allerton Conference on Communication, Control, and Computing Monticello, USA, September 29–October 2, 2015 p1336
[5] 练秋生, 富利鹏, 陈书贞, 石保顺 2019 自动化学报 45 2082
Google Scholar
Lian Q S, Fu L P, Chen S Z, Shi B S 2019 Acta Autom. Sin. 45 2082
Google Scholar
[6] Kulkarni K, Lohit S, Turaga P, Kerviche R, Ashok A 2016 IEEE Conference on Computer Vision and Pattern Recognition Las Vegas, USA, June 26–30, 2016 p449
[7] Yao H T, Dai F, Zhang SL, Zhang Y D, Tian Q, Xu C S 2019 Neurocomputing 359 483
Google Scholar
[8] 李静, 向菲, 张军朋 2019 电子设计工程 27 84
Google Scholar
Li J, Xian F, Zhang J P 2019 Int. Electr. Elem. 27 84
Google Scholar
[9] Hu X C, Wei L S, Chen W, Chen Q Q, Guo Y 2020 IEEE Access 8 12452
Google Scholar
[10] 庄志本, 李军, 刘静漪, 陈世强 2020 物理学报 69 040502
Google Scholar
Zhuang Z B, Li J, Liu J Y, Chen S Q 2020 Acta Phys. Sin. 69 040502
Google Scholar
[11] Zhang D, Liao X F, Yang B, Zhang Y S 2018 Multim. Tools Appl. 77 2191
Google Scholar
[12] 石航, 王丽丹 2019 物理学报 68 200501
Google Scholar
Shi H, Wang L D 2019 Acta Phys. Sin. 68 200501
Google Scholar
[13] Gong L H, Qiu K D, Deng C Z, Zhou N R 2019 Opt. Laser Technol. 115 257
Google Scholar
[14] Qin W, Peng X 2010 Opt. Lett. 35 118
Google Scholar
[15] Liu Y N, Niu H Q, Li Z L 2019 Chin. Phys. Lett. 36 044302
Google Scholar
[16] Li C B, Yin W T, Jiang H, Zhang Y 2013 Comput. Optim. Appl. 56 507
Google Scholar
[17] Dong W S, Shi G M, Li X, Ma Y, Huang F 2014 IEEE Trans. Image Process. 23 3618
Google Scholar
[18] Metzler C A, Maleki A, Baraniuk R G 2016 IEEE Trans. Inf. Theory 62 5117
Google Scholar
[19] Guo Y, Jing S W, Zhou Y Y, Xu X, Wei L S 2020 IEEE Access 8 9896
Google Scholar
[20] Belazi A, El-Latif A A, Belghith S 2016 Signal Process. 128 155
Google Scholar
[21] Hua Z Y, Zhou Y C, Pun C M, Chen C 2015 Inf. Sci. 297 80
Google Scholar
[22] Wu Y, Zhou Y C, Saveriades G, Agaian S S, Noonan J P, Natarajan P 2013 Inf. Sci. 222 323
Google Scholar


 下载:
下载:

计量
- 文章访问数: 13491
- PDF下载量: 389
- 被引次数: 0
